









 本文深入剖析了LinkedHashMap的内部实现机制,包括其与HashMap的主要区别、如何维持元素的插入或访问顺序,以及如何利用这些特性实现LRU缓存策略。
本文深入剖析了LinkedHashMap的内部实现机制,包括其与HashMap的主要区别、如何维持元素的插入或访问顺序,以及如何利用这些特性实现LRU缓存策略。
LinkedHashMap
概述
本文主要参考了Java Collection Framework 源码剖析这位博主的专栏,写的很好,感兴趣的可以去看一下!
LinkedHashMap是HashMap的子类,其具有HashMap的所有特性;
LinkedHashMap增加了时间和空间上的开销,但是它通过维护一个额外的双向链表保证了迭代顺序。特别地,该迭代顺序可以是插入顺序,也可以是访问顺序;
根据链表中元素的顺序可以分为:保持插入顺序的LinkedHashMap 和 保持访问顺序的LinkedHashMap
HashMap和LinkedHashMap的Entry结构示意图如下:
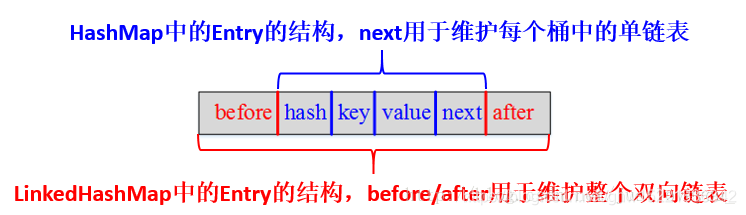
HashMap和双向链表的配合和分工合作造成就了LinkedHashMap;next用于维护HashMap各个桶中的Entry链,before、after用于维护LinkedHashMap的双向链表,虽然它们的作用对象都是Entry,但是各自分离。
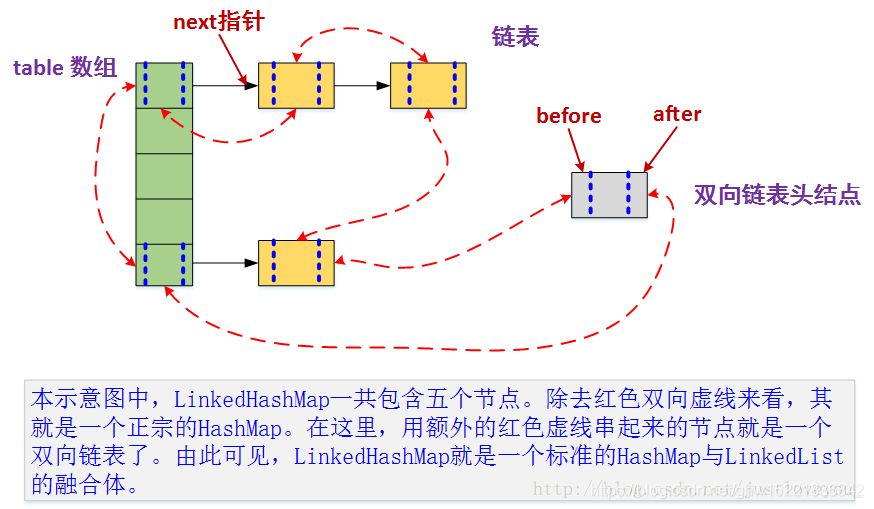
LinkedHashMap在JDK中的定义
1、类结构定义
LinkedHashMap继承于HashMap,其在JDK中的定义为:
public class LinkedHashMap<K,V>
extends HashMap<K,V>
implements Map<K,V> {
...
}
2、成员变量定义
LinkedHashMap增加了双向链表头结点header和标志位accessOrder(值为true时,表示按照访问顺序迭代;值为false时,表示按照插入顺序迭代);
private transient Entry<K,V> header; // 双向链表的表头元素
private final boolean accessOrder; //true表示按照访问顺序迭代,false时表示按照插入顺序
3、基本元素Entry
LinkedHashMap中的Entry增加了两个指针before和after,分别用于维护双向链接列表,next用于维护HashMap各个桶中Entry的连接顺序,before、after用于维护Entry插入的先后顺序的:
private static class Entry<K,V> extends HashMap.Entry<K,V> {
// These fields comprise the doubly linked list used for iteration.
Entry<K,V> before, after;
Entry(int hash, K key, V value, HashMap.Entry<K,V> next) {
super(hash, key, value, next);
}
...
}
LinkedHashMap的快速存取
1、put(key,value)
LinkedHashMap没有对put(key,value)方法做任何直接修改,完全继承了HashMap的put(key,value)的方法;对addEntry方法和Entry的recordAccess方法进行了重写;
void addEntry(int hash, K key, V value, int bucketIndex) {
//创建新的Entry,并插入到LinkedHashMap中
createEntry(hash, key, value, bucketIndex); // 重写了HashMap中的createEntry方法
//双向链表的第一个有效节点(header后的那个节点)为最近最少使用的节点,这是用来支持LRU算法的
Entry<K,V> eldest = header.after;
//如果有必要,则删除掉该近期最少使用的节点,
//这要看对removeEldestEntry的覆写,由于默认为false,因此默认是不做任何处理的。
if (removeEldestEntry(eldest)) {
removeEntryForKey(eldest.key);
} else {
//扩容到原来的2倍
if (size >= threshold)
resize(2 * table.length);
}
}
在LinkedHashMap的addEntry方法中,它重写了HashMap中的createEntry方法,我们接着看一下createEntry方法:
void createEntry(int hash, K key, V value, int bucketIndex) {
// 向哈希表中插入Entry,这点与HashMap中相同
//创建新的Entry并将其链入到数组对应桶的链表的头结点处,
HashMap.Entry<K,V> old = table[bucketIndex];
Entry<K,V> e = new Entry<K,V>(hash, key, value, old);
table[bucketIndex] = e;
//在每次向哈希表插入Entry的同时,都会将其插入到双向链表的尾部,
//这样就按照Entry插入LinkedHashMap的先后顺序来迭代元素(LinkedHashMap根据双向链表重写了迭代器)
//同时,新put进来的Entry是最近访问的Entry,把其放在链表末尾 ,也符合LRU算法的实现
e.addBefore(header);
size++;
}
***addBefore的本质是一个双向链表的插入***
//在双向链表中,将当前的Entry插入到existingEntry(header)的前面
private void addBefore(Entry<K,V> existingEntry) {
after = existingEntry;
before = existingEntry.before;
before.after = this;
after.before = this;
}
2、get(Object key)
LinkedHashMap中重写了HashMap中的get方法:
public V get(Object key) {
// 根据key获取对应的Entry,若没有这样的Entry,则返回null
Entry<K,V> e = (Entry<K,V>)getEntry(key);
if (e == null) // 若不存在这样的Entry,直接返回
return null;
e.recordAccess(this);
return e.value;
}
3、resize()
LinkedHashMap完全继承了HashMap的resize()方法,只是对它所调用的transfer方法进行了重写;
void resize(int newCapacity) {
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
// 若 oldCapacity 已达到最大值,直接将 threshold 设为 Integer.MAX_VALUE
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return; // 直接返回
}
// 否则,创建一个更大的数组
Entry[] newTable = new Entry[newCapacity];
//将每条Entry重新哈希到新的数组中
transfer(newTable); //LinkedHashMap对它所调用的transfer方法进行了重写
table = newTable;
threshold = (int)(newCapacity * loadFactor); // 重新设定 threshold
}
Map扩容操作的核心在于重哈希
void transfer(HashMap.Entry[] newTable) {
int newCapacity = newTable.length;
// 与HashMap相比,借助于双向链表的特点进行重哈希使得代码更加简洁
for (Entry<K,V> e = header.after; e != header; e = e.after) {
int index = indexFor(e.hash, newCapacity); // 计算每个Entry所在的桶
// 将其链入桶中的链表
e.next = newTable[index];
newTable[index] = e;
}
}
LRU缓存
LinkedHashMap区别于HashMap最大的一个不同点是,前者是有序的,而后者是无序的。为此,LinkedHashMap增加了两个属性用于保证顺序,分别是双向链表头结点header和标志位accessOrder。我们知道,header是LinkedHashMap所维护的双向链表的头结点,而accessOrder用于决定具体的迭代顺序。
当accessOrder的标志位为true时,表示双向链表中的元素按照访问的先后顺序排列;
recordAccess方法判断accessOrder是否为true,如果是,则将当前访问的Entry(put进来的Entry或get出来的Entry)移到双向链表的尾部(key不相同时,put新Entry时,会调用addEntry,它会调用createEntry,该方法同样将新插入的元素放入到双向链表的尾部,既符合插入的先后顺序,又符合访问的先后顺序,因为这时该Entry也被访问了);
当标志位accessOrder的值为false时,虽然也会调用recordAccess方法,但不做任何操作;
当我们要用LinkedHashMap实现LRU算法时,就需要调用该构造方法并将accessOrder置为true
void recordAccess(HashMap<K,V> m) {
LinkedHashMap<K,V> lm = (LinkedHashMap<K,V>)m;
//如果链表中元素按照访问顺序排序,则将当前访问的Entry移到双向循环链表的尾部,
//如果是按照插入的先后顺序排序,则不做任何事情。
if (lm.accessOrder) {
lm.modCount++;
//移除当前访问的Entry
remove();
//将当前访问的Entry插入到链表的尾部
addBefore(lm.header);
}
}
- 设定最大缓存空间 MAX_ENTRIES 为 3;
- 使用 LinkedHashMap 的构造函数将 accessOrder 设置为 true,开启 LRU 顺序;
- 覆盖 removeEldestEntry() 方法实现,在节点多于 MAX_ENTRIES 就会将最近最久未使用的数据移除;
class LRUCache<K, V> extends LinkedHashMap<K, V> {
private static final int MAX_ENTRIES = 3;
protected boolean removeEldestEntry(Map.Entry eldest) {
return size() > MAX_ENTRIES;
}
LRUCache() {
super(MAX_ENTRIES, 0.75f, true);
}
}
LinkedHashMap和HashMap的区别
- LinkedHashMap是HashMap的子类;
- LinkedHashMap中的Entry增加了两个指针before和after,分别用于维护双向链表;
- LinkedHashMap对put做了更改,例如,在LinkedHashMap中向哈希表中插入新Entry的同时,还会通过Entry的addBefore方法将其链入双向链表中;
- LinkedHashMap 完全继承了HashMap 的resize 操作,但是鉴于性能和LinkedHashMap 自身特点的考量,LinkedHashMap 对其中的重哈希过程(transfer 方法)进行了重写;
- 在读取操作上,LinkedHashMap 中重写了HashMap 中的get 方法,通过HashMap
中的getEntry 方法获取Entry 对象。在此基础上,进一步获取指定键对应的值;

















 1369
1369

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









