






 本文深入探讨了LinkedHashMap,它是HashMap的子类,实现了Map接口。LinkedHashMap通过before和after引用形成双向链表,根据访问时间排序。文章详细解析了HashMap的扩容策略和Tree化机制,并介绍了LinkedHashMap如何在get操作时更新访问顺序,以及如何利用removeEldestEntry实现LRU缓存。
本文深入探讨了LinkedHashMap,它是HashMap的子类,实现了Map接口。LinkedHashMap通过before和after引用形成双向链表,根据访问时间排序。文章详细解析了HashMap的扩容策略和Tree化机制,并介绍了LinkedHashMap如何在get操作时更新访问顺序,以及如何利用removeEldestEntry实现LRU缓存。

LinkedHashMap的原理大致和上篇文章提到的数据结构类似。LRU算法实现
它继承自HashMap , 实现了map 接口。 所以,我们先来看下HashMap 的实现方式。
一. HashMap
HashMap 的目的是为了实现一种键值对, 能够在O(1)的时间复杂度内找到键所对应的值值所在的位置。

主要的数据结构由以下两个属性实现。
// 每一个节点的hash值,由key 的hashcode 和value 的hashcode异或得到。
// next 指向此节点在这条链中的后继节点
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
}
// The table, initialized on first use,
// and resized as necessary. When allocated, length is always a power of two.
transient Node<K,V>[] table;table 被称作hash 桶,每个桶存储一条节点拉链, 感觉英文表述的比较清楚,我将jdk 的源码注释放在了上面。
二. HashMap 主要属性
上面注释提到了当需要的时候,table 进行扩容。
HashMap 的扩容策略:
用属性initialCapacity 表示初始化容量。loadFactor表示加载因子。threshold表示哈希表内元素数量的阈值,当哈希表内元素数量超过阈值时,会发生扩容resize()。threshold = 哈希桶.length * loadFactor;
// 参数列表为空的HashMap 使用默认的initialCapacity(16)和默认的loadFactor(0.75)
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted
} 扩容的策略可以简单的理解为申请一个新的两倍大小的hash桶, 并将原来hash桶中的元素逐个复制到新的hash 桶中, 属性table指向新桶, 并回收旧的hash桶。
// tree 化的阈值
static final int TREEIFY_THRESHOLD = 8;
static final int UNTREEIFY_THRESHOLD = 6;jdk 中的HashMap 还有一个很重要的特性: 当HashMap 中元素的个数远大于桶的个数, 发生hash 碰撞的概率就会提高。 因为每个桶中是一条单链表。 假设链表长度平均为n , 查询的时间复杂度就变成了 log(n), 为此, HashMap 做了一个很巧妙的设计,当插入节点链表长度大于8 的时候, 会把节点结构由Node转化为TreeNode , 把单链表进行Tree 化转化为红黑树, 以此来降低时间复杂度。 上面两个属性就行Tree 化和 逆Tree化的长度阈值。
tips: 至于为啥阈值是8,看到过一种说法, log(8)= 3 , 8/2 = 4 , 当8个元素的时候, 遍历查找的时间复杂度开始大于红黑树。
三. LinkedHashMap概述
LinkedHashMap 的特性, 每个节点间由一个before引用 和 after 引用串联起来成为一个双向链表。链表节点按照访问时间进行排序,最近访问过的链表放在链表尾。
// 10 是初始大小,0.75 是装载因子,true 是表示按照访问时间排序
HashMap<Integer, Integer> m = new LinkedHashMap<>(10, 0.75f, true);
m.put(3, 11);
m.put(1, 12);
m.put(5, 23);
m.put(2, 22);
m.put(3, 26);
m.get(5);
for (Map.Entry e : m.entrySet()) {
System.out.println(e.getKey());
}例如 上段代码, 输出的结果就是 1,2,3,5。
四. LinkedHashMap 主要结构
其结构图如图:
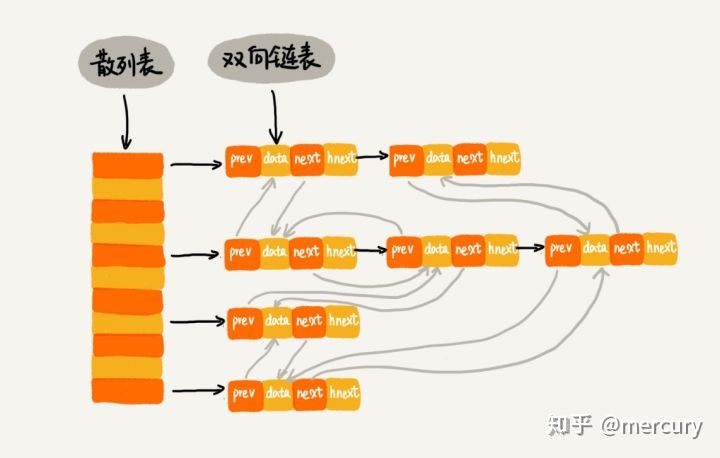
static class Entry<K,V> extends HashMap.Node<K,V> {
Entry<K,V> before, after;
Entry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
}在HashMap 的节点的基础上, 加上了两个引用来将所有节点串联成一个双向链表。
LinkedHashMap 重写了get() 方法,在afterNodeAccess()函数中,会将当前被访问到的节点e,移动至内部的双向链表的尾部。
public V get(Object key) {
Node<K,V> e;
if ((e = getNode(hash(key), key)) == null)
return null;
if (accessOrder)
afterNodeAccess(e);
return e.value;
}LinkedHashMap并没有重写任何put方法。但是其重写了构建新节点的newNode()方法。
newNode()会在HashMap的putVal()方法里被调用,HashMap 的 put()方法会调用putVal() 方法。 实现的逻辑: 根据hash值找到散列位置i,先判断table[i]是否存在node ,如果不存在,则调用newNode()并赋值给table[i],如果存在,则插入到单链表或红黑树的后面。
//在构建新节点时,构建的是`LinkedHashMap.Entry` 不再是`Node`.
Node<K,V> newNode(int hash, K key, V value, Node<K,V> e) {
LinkedHashMap.Entry<K,V> p =
new LinkedHashMap.Entry<K,V>(hash, key, value, e);
linkNodeLast(p);
return p;
}
重新后的newnode 只添加了一条逻辑, 把节点添加到双链表的尾部。
在HashMap 的putVal() 中有一个空方法就是为LinkedHashMap 预留的 :afterNodeAccess () 在HashMap 中它是一个空方法, 而在LinkedHashMap 中我们可以看到其实现:
//回调函数,新节点插入之后回调 , 根据evict 和 判断是否需要删除最老插入的节点。如果实现LruCache会用到这个方法。
void afterNodeInsertion(boolean evict) { // possibly remove eldest
LinkedHashMap.Entry<K,V> first;
//LinkedHashMap 默认返回false 则不删除节点
if (evict && (first = head) != null && removeEldestEntry(first)) {
K key = first.key;
removeNode(hash(key), key, null, false, true); }
}
//LinkedHashMap 默认返回false 则不删除节点。 返回true 代表要删除最早的节点。通常构建一个LruCache会在达到Cache的上限是返回true
protected boolean removeEldestEntry(Map.Entry<K,V> eldest) {
return false;
}回到上篇内容,如果我们要根据LinkedHashMap 实现一个LruCashed , 我们只需要继承LinkedHashMap ,重写removeEldestEntry, 当当前长度> 缓存长度, 返回true 即可。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









