动态规划求解MDP(基于贝尔曼方程) 一、策略迭代法 1. 策略评估 基于贝尔曼方程的动态规划迭代: 基本思想:在当前策略Pi下,初始化值函数V0,用当前策略和前Vk来更新Vk+1,直至Vk+1收敛 2. 策略改进 a − n e w = arg max a Q π ( s , a ) a_{-} n e w=\arg \max _{a} Q_{\pi}(s, a) a

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









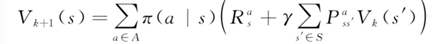
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3443
3443





