







Dataset让我们可以知道数据在什么位置,及数据的的索引对应的数据。
Dataloader相当于加载器,把数据加载到神经网络中
import torchvision
#测试数据集,train设置为false,因为数据集原本是PIL.image类型,但是我们要用的是tesor类型,所以转换一下
from torch.utils.data import DataLoader
test_data = torchvision.datasets.CIFAR10("./data",train=False,transform=torchvision.transforms.ToTensor(),download=True)
#加载测试集
#batch_size=4即每次从test_data中取4个数据集进行打包
test_loader = DataLoader(dataset=test_data,batch_size=4,shuffle=True,num_workers=0,drop_last=False)
#测试数据集中第一张图片及target
img,target = test_data[0]
print(img.shape)
print(target)
#取test_loader中的每一个返回
for data in test_loader:
imgs,targets = data
print(imgs.shape)
print(targets)运行结果: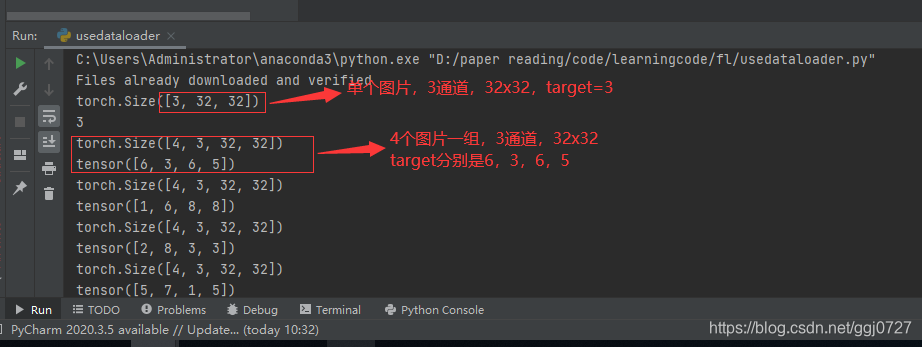
修改batch_size
import torchvision
#测试数据集,train设置为false,因为数据集原本是PIL.image类型,但是我们要用的是tesor类型,所以转换一下
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
test_data = torchvision.datasets.CIFAR10("./data",train=False,transform=torchvision.transforms.ToTensor(),download=True)
#加载测试集
#batch_size=64即每次从test_data中取64个数据集进行打包,drop_last=true意思是最后一张不足64个的时候舍弃,false不舍弃
test_loader = DataLoader(dataset=test_data,batch_size=64,shuffle=True,num_workers=0,drop_last=False)
#测试数据集中第一张图片及target
img,target = test_data[0]
print(img.shape)
print(target)
writer = SummaryWriter("dataloader")
step = 0
for data in test_loader:
imgs,targets = data
# print(imgs.shape)
# print(targets)
writer.add_images("test_data",imgs,step)
step = step +1
writer.close()
运行后想在tensorboard打开,则tenminal执行以下操作:

点击链接:
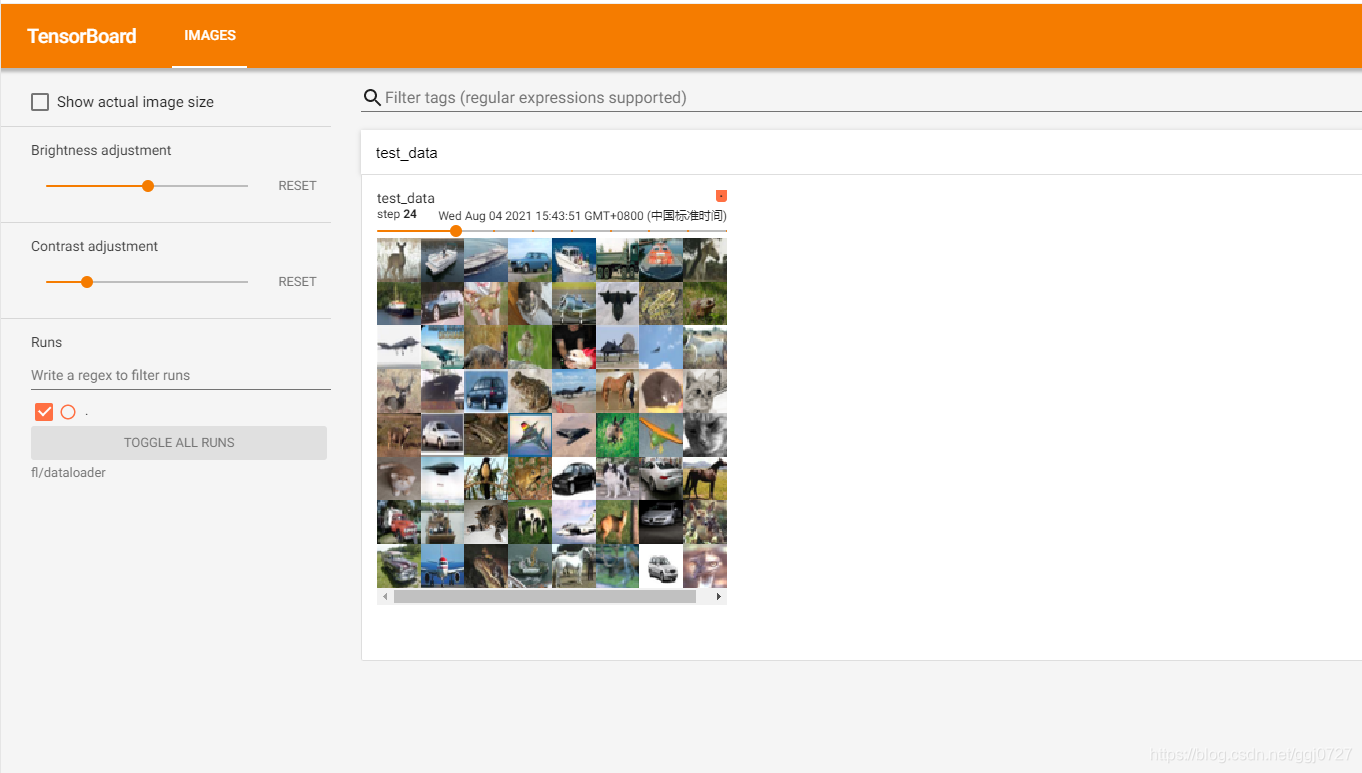
(注:如果无法打开,则修改一下logdir的路径,改成相对路径/绝对路径)
对shuffle的使用、修改。在每一轮中shuffle=False时读的数据是一样的。改为True时则顺序打乱
import torchvision
#测试数据集,train设置为false,因为数据集原本是PIL.image类型,但是我们要用的是tesor类型,所以转换一下
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
test_data = torchvision.datasets.CIFAR10("./data",train=False,transform=torchvision.transforms.ToTensor(),download=True)
#加载测试集
#batch_size=64即每次从test_data中取64个数据集进行打包,drop_last=true意思是最后一张不足64个的时候舍弃,
test_loader = DataLoader(dataset=test_data,batch_size=64,shuffle=False,num_workers=0,drop_last=True)
#测试数据集中第一张图片及target
img,target = test_data[0]
print(img.shape)
print(target)
writer = SummaryWriter("dataloader")
for epoch in range(2):
step = 0
#epoch=0时,读取数据一遍,epoch=1时又读取一遍。shuffle=False时读的数据是一样的。改为True时顺序打乱
for data in test_loader:
imgs,targets = data
# print(imgs.shape)
# print(targets)
writer.add_images("Epoch:{}".format(epoch),imgs,step)
step = step +1
writer.close()
在tensorboard显示如下:
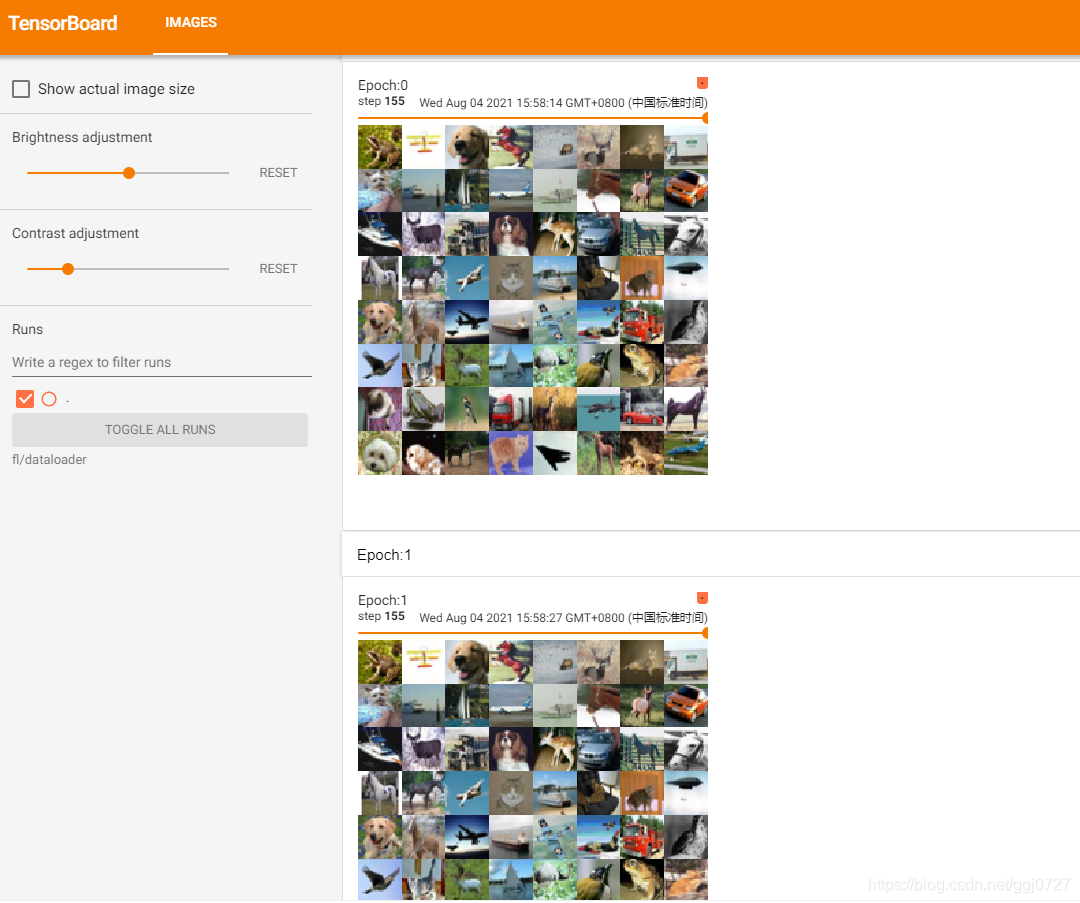
可以看到,两轮的数据顺序时一致的,因此通常shuffle设置为True

















 770
770

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









