




 Luna是一种线性统一嵌套注意力模型,通过两个嵌套的线性注意力函数近似softmax注意力,实现线性时间复杂度。它引入固定长度额外序列,允许线性注意操作并存储上下文信息。模型包括打包和解包注意力,有效减少参数数量,适用于处理可变长度序列和自回归注意力。
Luna是一种线性统一嵌套注意力模型,通过两个嵌套的线性注意力函数近似softmax注意力,实现线性时间复杂度。它引入固定长度额外序列,允许线性注意操作并存储上下文信息。模型包括打包和解包注意力,有效减少参数数量,适用于处理可变长度序列和自回归注意力。
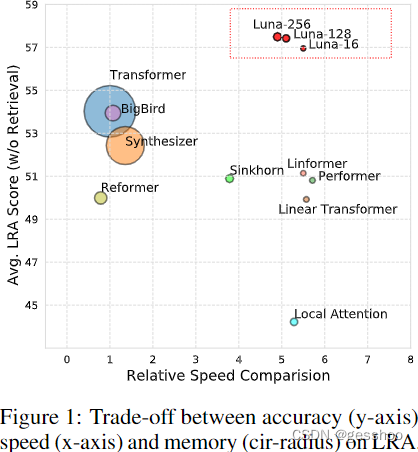
线性统一嵌套注意力。用两个嵌套的线性注意力函数近似softmax attention,只产生线性(而不是二次)的时间和空间复杂性。
Luna引入了一个固定长度的额外的序列作为输入,对应着一个额外的输出,寻允许Luna线性地进行注意操作,同时还存储足够的上下文信息。
具体地说,利用第一个注意力函数,Luna将输出序列打包成固定长度的序列。然后,使用第二个注意力函数对打包的序列进行解包。Luna引入了一个固定长度的附加序列作为输入和一个附加的相应输出。重要的是,额外的输入能够像Linformer一样高效地线性的注意力操作,同时也存储了足够的上下文信息。不像Linformer的是,Luna能模拟可变长度序列和自回归注意力。
模型
Pack and Unpack Attention
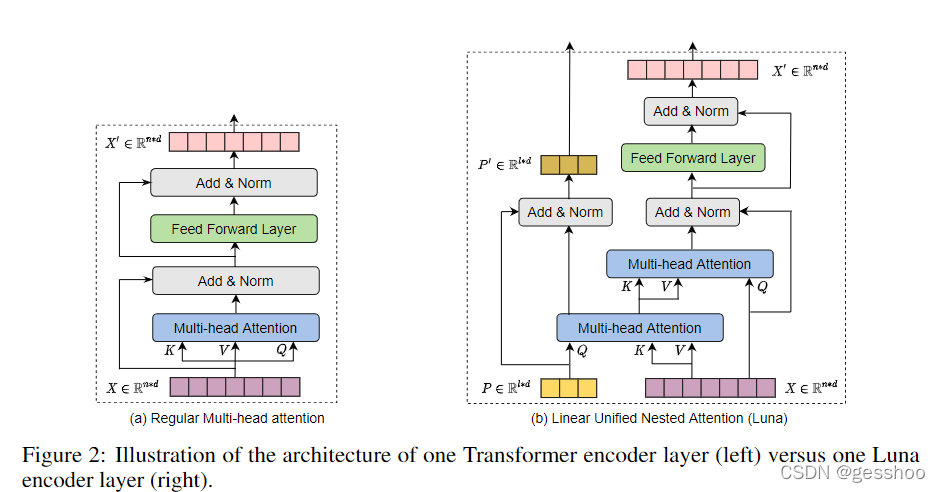
Luna的核心思想是将原本的注意力模块解耦成两个嵌套的线性的注意力操作。引入了一个额外的输入,是一个固定长度的序列。将这个额外的序列作为query序列,送入第一个注意力操作,“打包注意力”,将上下文序列打包成固定长度的序列。Pack attention将C打包成Yp(packed context)--是第一个attention操作的输出。
因为P的长度是常数l,所以打包注意的复杂度是O(Ln),它相对于n是线性的。
为了将序列解包回到原始序列长度n,Luna使用第二个注意力“解包注意力”。与包装注意类似,非包装注意的复杂度为O(Ln),且与n呈线性关系。
P
对于第一层,P是一个可学习的位置编码。
Reducing the Number of Parameters.
在每一层共享Wk、Wq。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 665
665

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









