




 DINO是一种基于DETR-like架构的目标检测模型,它解决了传统DETR模型收敛速度慢和query意义模糊的问题。通过引入对比去噪训练、混合query选择方法及向前看两次的策略,DINO不仅提高了模型的精度,还增强了模型对于大型backbone和大规模数据集的适用性。
DINO是一种基于DETR-like架构的目标检测模型,它解决了传统DETR模型收敛速度慢和query意义模糊的问题。通过引入对比去噪训练、混合query选择方法及向前看两次的策略,DINO不仅提高了模型的精度,还增强了模型对于大型backbone和大规模数据集的适用性。
通过使用一个对比的方式为了去噪训练,一个混合的query选择方法为了anchor初始化,和一个向前看两次的方案为了box预测。
DINO在模型大小和数据大小上表现出良好的可扩展性,用SwinL backbone在Object365大数据集预训练,达到了COCO val2017 63.2AP 和 test-dev 63.3AP。SOTA in 2022.3
Introduction
DETR的主要问题是收敛慢和query的意义是不明确的。
目前在最好的检测器当前还是经典的检测器,Dyhead、HTC等。为什么? 1.以前的DETR-like模型不如改进的经典检测器;比较经典的研究很多年被很好的优化。 2.DETR-like的模型的可扩展性还没有被很好的研究,还没有人将其扩展到大backbone和大体量数据集上。 本文解决了这两个担忧。
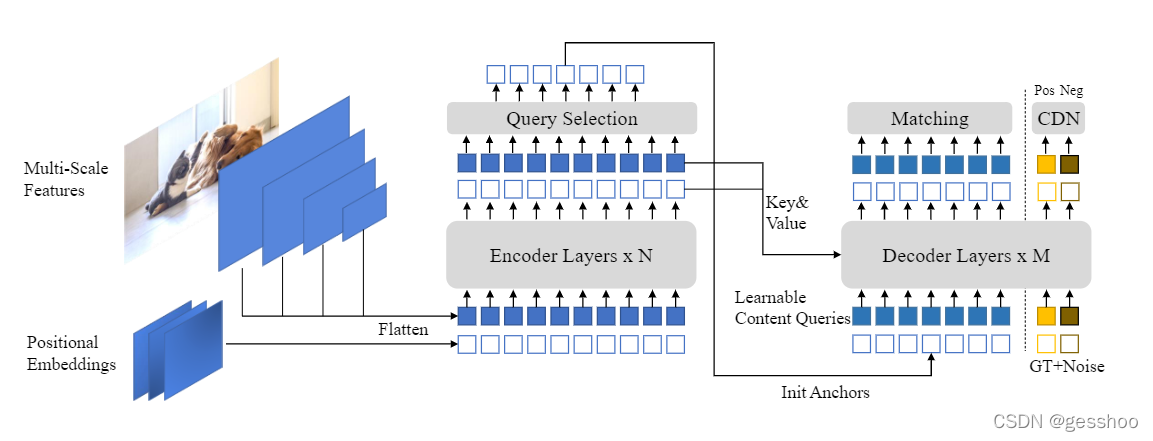
DINO模型在decoder显示制定了query作为动态anchor box(4D锚框坐标表征)并通过decoder多层一步一步精细化他们,像DAB-DETR;在decoder各个层在groud-truth label和box中加入噪声去帮助训练中二分图匹配的稳定,像DN-DETR;还采用了deformable attention为了提高效率。另外,提出了三个新方法。
1.为了提高一对一匹配,提出了对比去噪训练,通过在同一时间加入同一个grond-truth的正、负样本。在给同一个ground-truth box加入两个不同噪声后,我们标记有小噪声的box作为正样本,其他就为负样本。对比去噪训练可以帮助模型避免同一目标的多次输出。 2.query的动态锚盒指定将DETR-like的模型与经典的两阶段模型联系起来。因此,我们提出了一种混合的query选择方法,帮助更好的初始化query。我们从编码器的输出中选择初始锚框作为位置查询。然而,我们让内容查询像以前一样是可以学习的,从而鼓励第一个解码层将重点放在空间先验上。 3.为了利用来自上一层的精细化的box信息去帮助优化相邻的早期层的参数,我们提出一种新的两次前瞻方案,利用后层的梯度来修正更新后的参数。
Method

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









