






 本文详细解析了OkHttp中各种拦截器的工作流程,包括retryAndFollowUpInterceptor、bridgeInterceptor、CacheInterceptor、ConnectInterceptor和CallServerInterceptor。阐述了它们在请求处理中的作用,如管理网络连接、处理本地缓存及与服务器的通讯。
本文详细解析了OkHttp中各种拦截器的工作流程,包括retryAndFollowUpInterceptor、bridgeInterceptor、CacheInterceptor、ConnectInterceptor和CallServerInterceptor。阐述了它们在请求处理中的作用,如管理网络连接、处理本地缓存及与服务器的通讯。
按照执行的顺序,先看retryAndFollowUpInterceptor
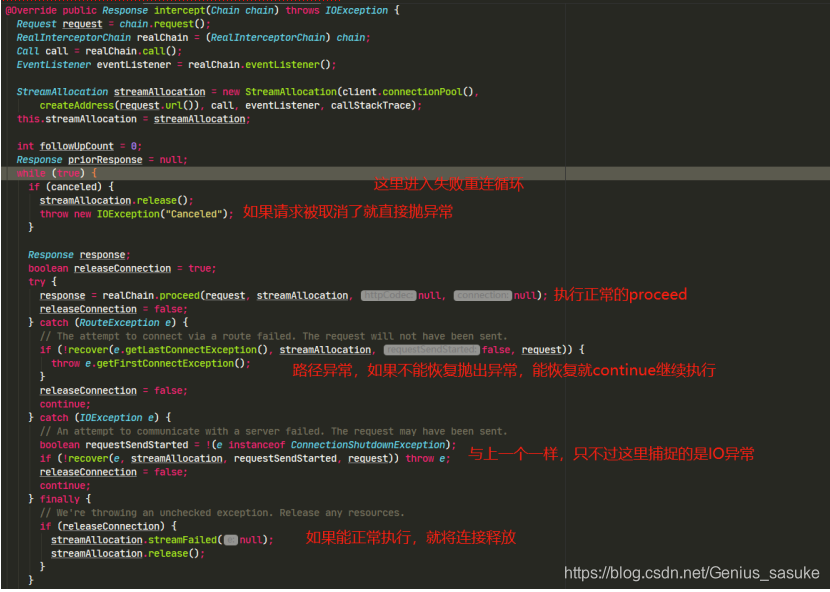
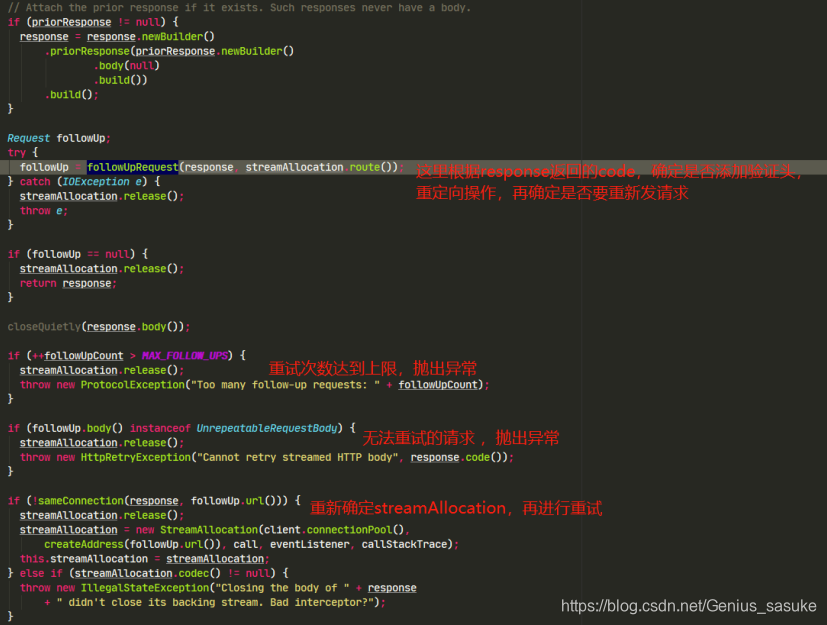
具体的流程在图中已经标明,那么streamAllocation是什么作用呢
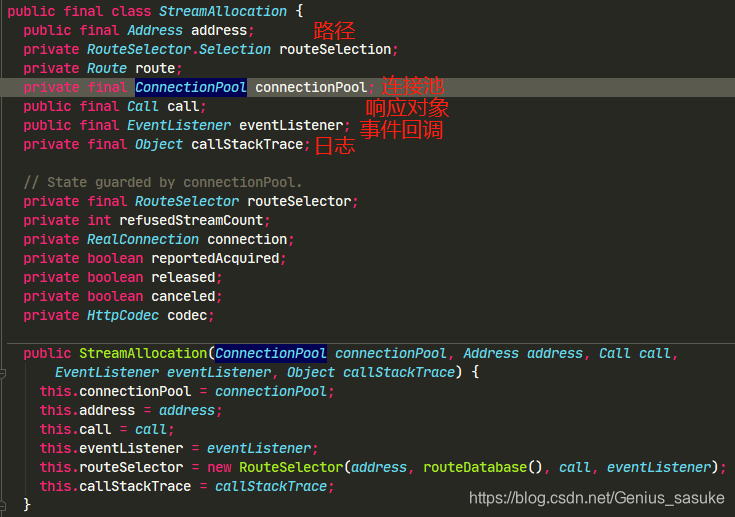
从成员变量看,这是个管理网络连接的类,具体的我们可以在ConnectInterceptor中再分析
接下来看bridgeInterceptor
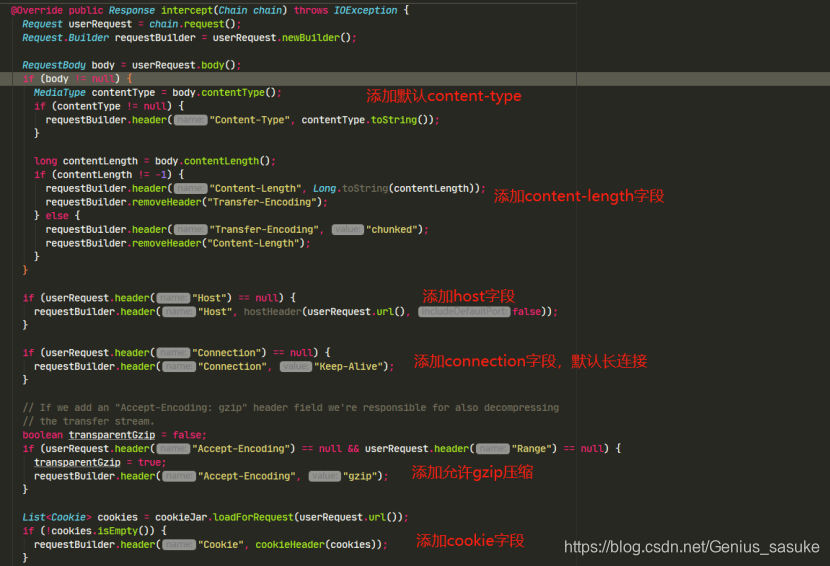
没啥好解释的,添加默认字段然后去执行proceed方法而已
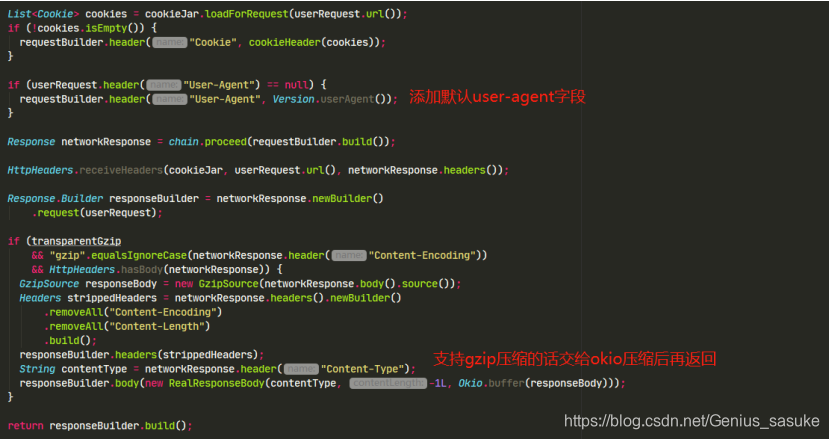
下一个!CacheInterptor
先看下这两个成员变量的意义
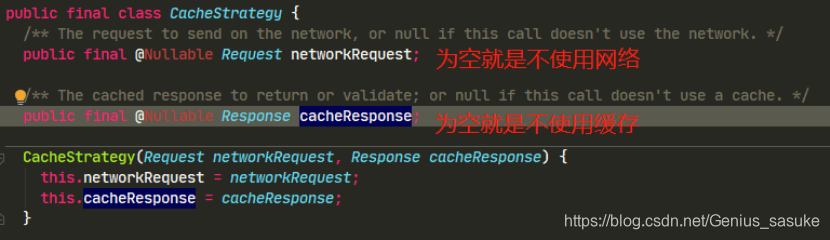
再理解下面这段具体的代码就容易了
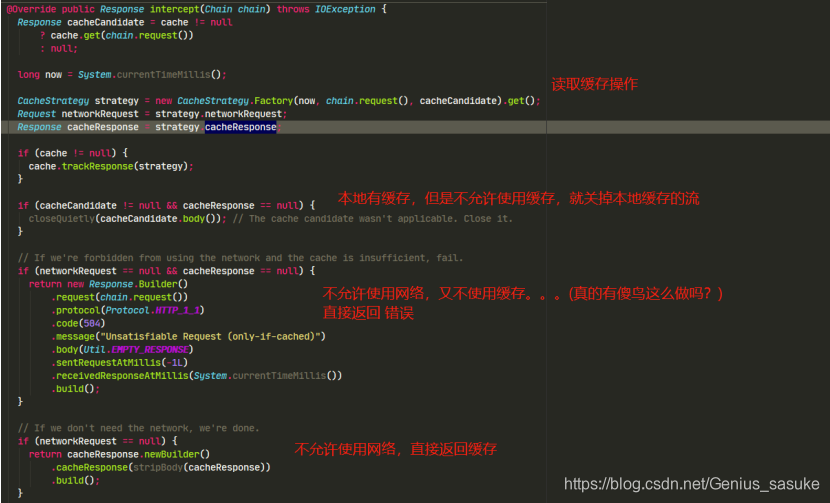

下面即走到本地缓存为空的情况
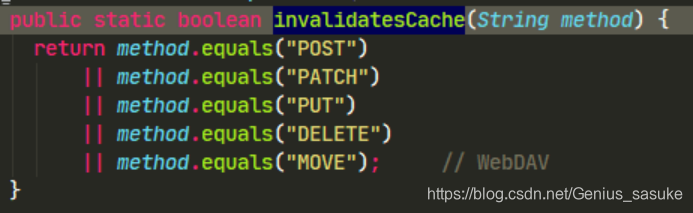
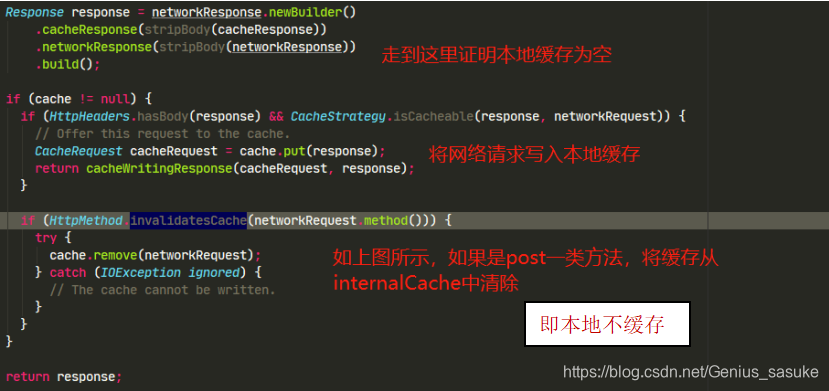
引申:为啥不允许post本地缓存呢?
答:GET后退/刷新无害,POST会导致重新提交数据。
GET书签可以被收藏,POST不可以。
GET编码application/x-www-form-url,POST为encodedapplication/x-www-form-urlencoded或multipart/form-data
GET历史参数保留在浏览器历史,POST不会
GET对数据长度有限制(url限制2048个字符),POST没有
GET只允许ASCII,POST没有
下一个!ConnectInterceptor
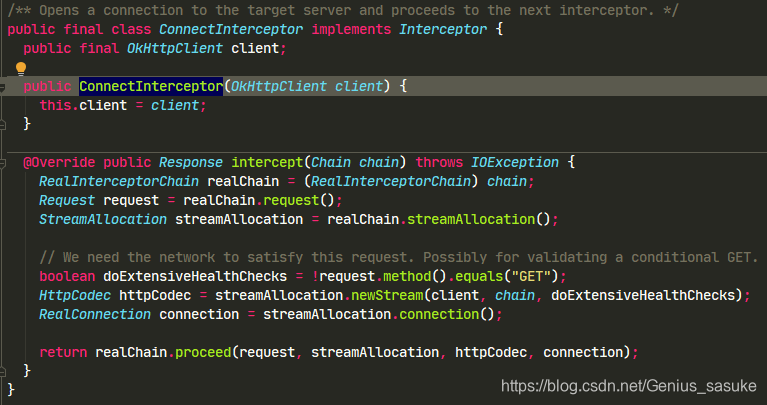
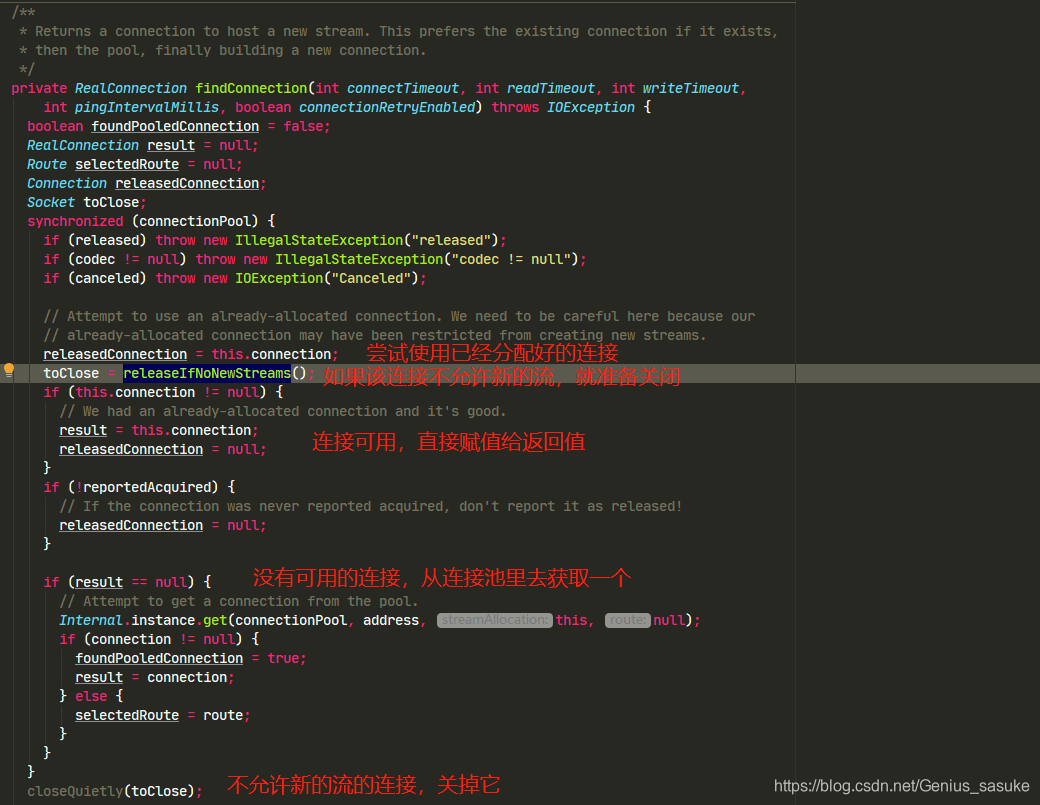
看class的注释,可以知道 ,这个类是用来开启服务器连接,其他并没有做什么操作,那么看看前面欠下的“债”,看看到底是怎么做连接的?
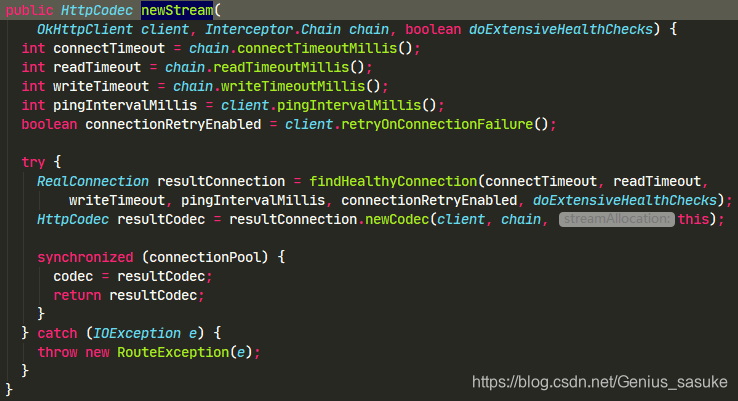
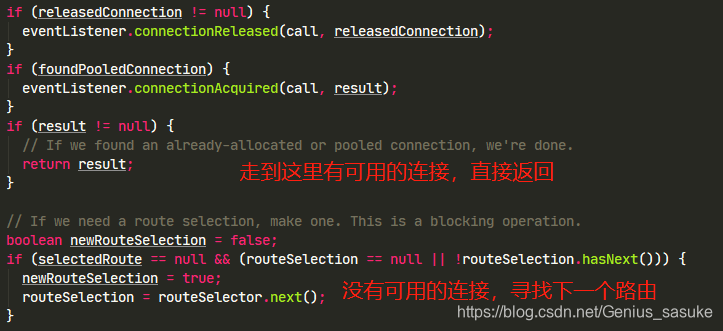
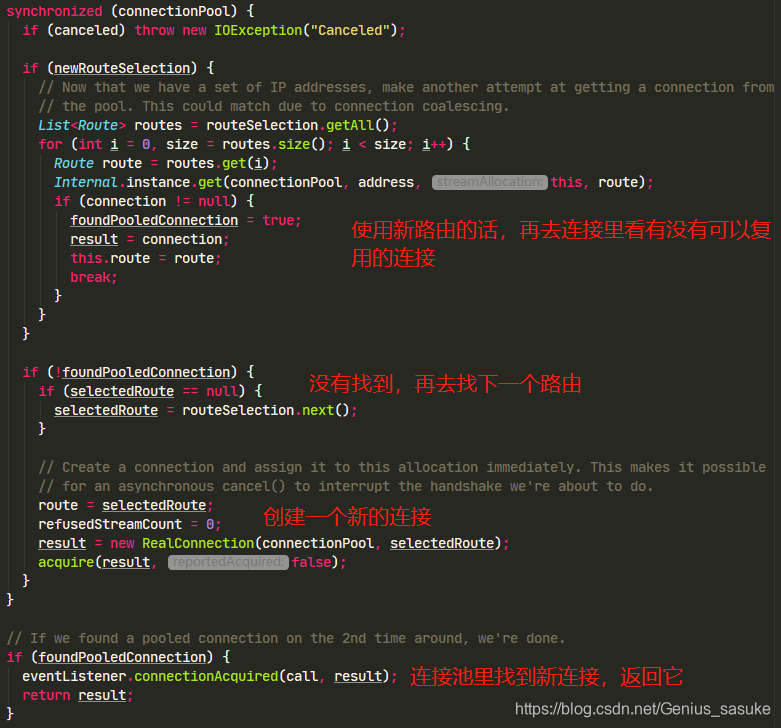
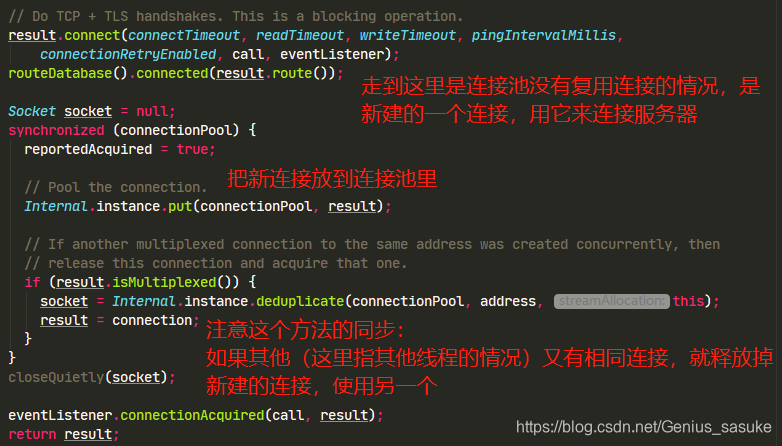
看来重点就是findHealthyConnection和newCodec这两个方法了,先看findHealthyConnection
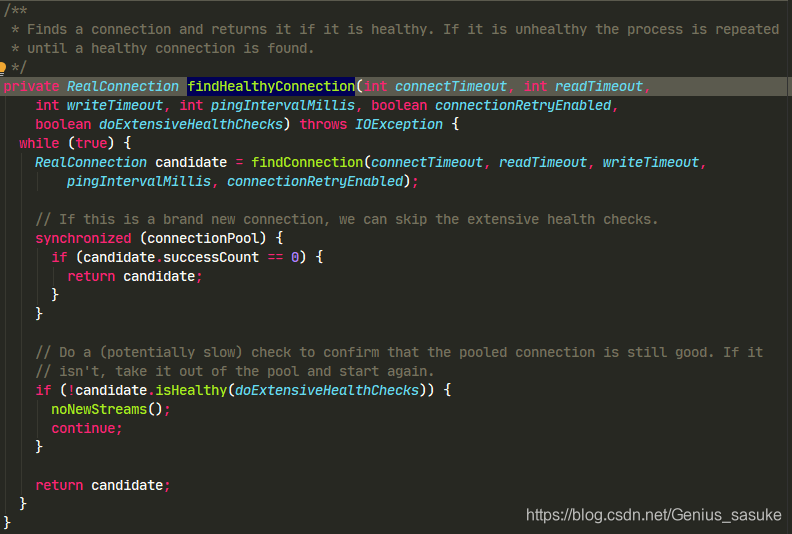
接下来,除了我们自定义的networkInterceptors之外,就只有最后一个CallServerInterceptor了
看名字。。。怎么好像这个才是真正进行连接服务器的interceptor。。。实际上,上一个是用来连接服务器,而这个,就是用来真正和服务器进行通讯了!

终于到last one了。。
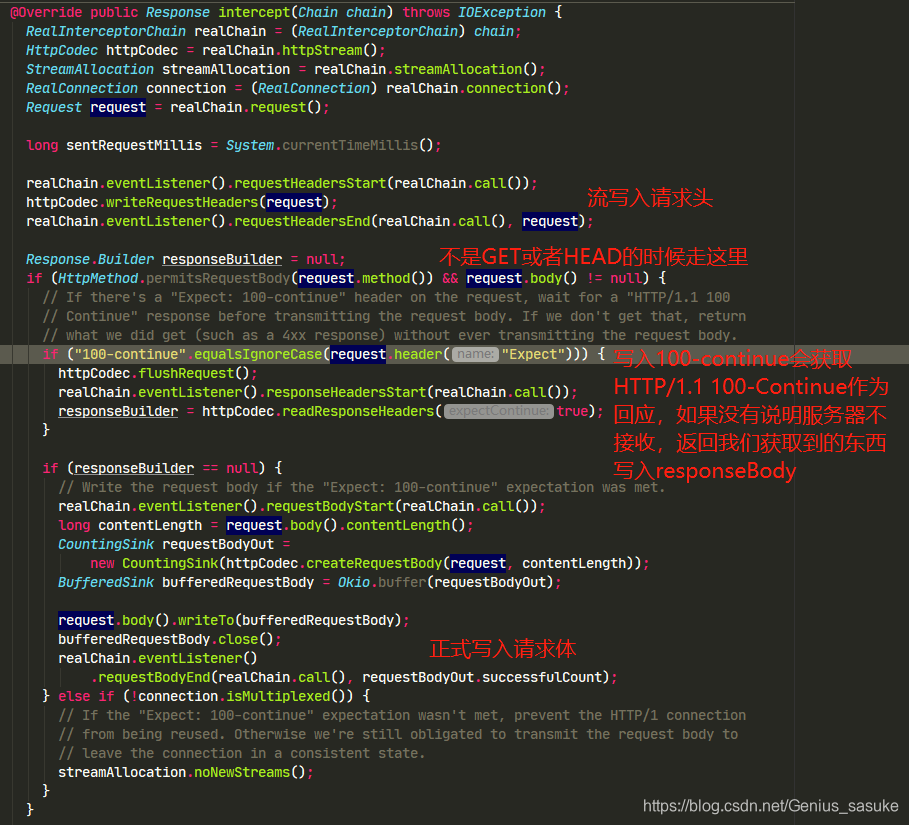

这里可以看到,GET或者HEAD请求方法是不需要写入100-continue的,因为这类请求不需要使用请求体的
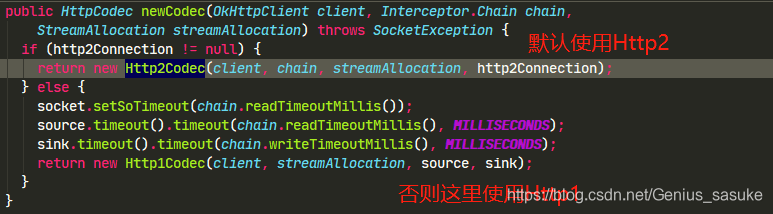
引申:http2和http1区别?
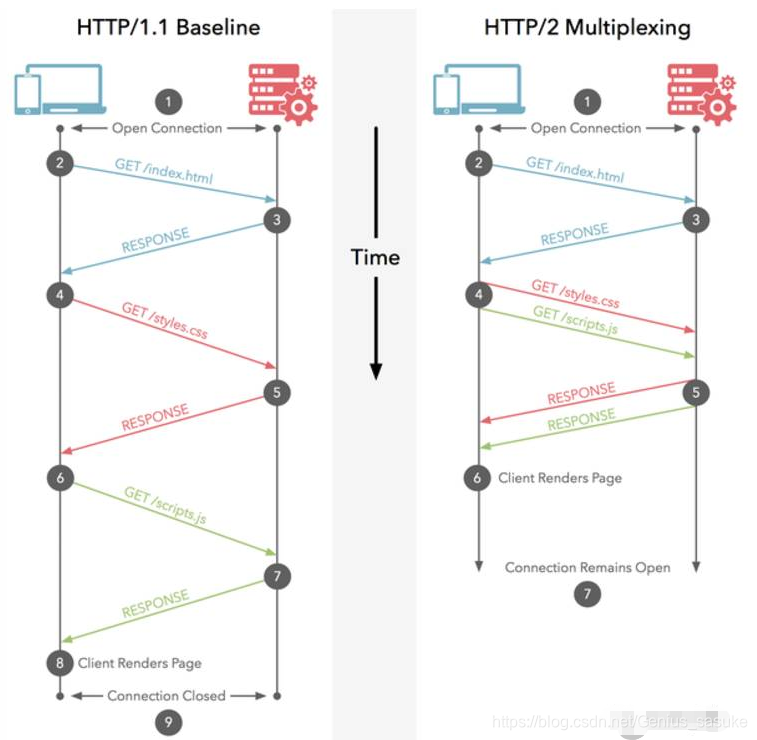
答:一张图,因为可以并行请求,所以速度更快
继续往下看:
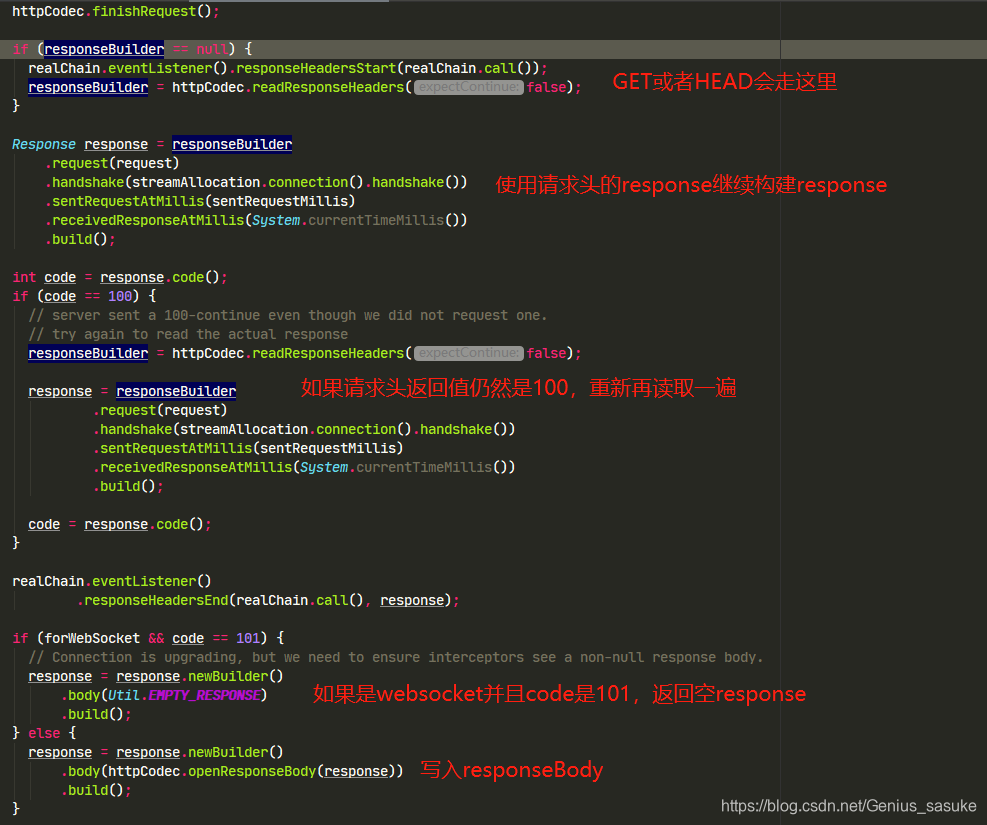
来看一下http2的openResponseBody做了啥

就是将流里面的内容写入responseBody!然后将整个response返回给我们就行了

















 3680
3680

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









