







 该文提出了一种新的深度学习语义分割方法,仅需目标边框标注,而非传统的像素级标注。通过候选区域法生成分割掩码,结合深度卷积神经网络进行训练,有效减少标注工作量,同时保持较高分割精度。实验表明,这种方法能够利用大量边框信息提高物体识别准确性,并优化网络训练。
该文提出了一种新的深度学习语义分割方法,仅需目标边框标注,而非传统的像素级标注。通过候选区域法生成分割掩码,结合深度卷积神经网络进行训练,有效减少标注工作量,同时保持较高分割精度。实验表明,这种方法能够利用大量边框信息提高物体识别准确性,并优化网络训练。
摘要:最近的语义分割方法都是基于像素级标注的深度卷积神经网络。像素级的标注需要大量的标注工作量并且阻碍了深度学习用更多的数据进行训练。本文提出一种只需要目标边框标注的方法并且可以得到较高的准确度。
1.概述
为什么大量的图像边框信息可以改进卷积神经网络?我们分析认为,边框监督的模型使用大量有效的边框提高了物体识别的准确性(物体内部的识别准确性),而对边界识别的贡献则是次要的。虽然边框信息不足以包含语义分割的细节信息,但是它提供了大量的用于训练神经网络的物体类别的实例,从而影响语义分割的结果。
2.相关工作
3.baseline
FCN网络的训练可以认为是一个单像素向真值的回归问题,其公式如下:
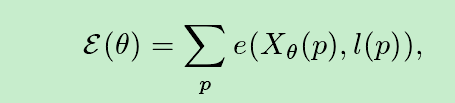
其中:p表示第p个像素,l(p)表示第p个像素的真值,x(p)第p个像素神经网络预测值,e()为损失函数
上面的公式要求有像素级的标注才能使用,并不适用于目标边框标注的方式。
4.方法介绍
4.1 分割方法
为了使用目标边框的标注,最好是从其中预测分割掩码。这是一个被广泛研究过的监督学习图像分割问题,可以通过GrabCut等方法解决。但是我们认为从GrabCut分割的图像不够精确,并且对于深度神经网络的训练来说是不够多的。
我们使用候选区域法(region proposal methods)(例如selective search)将图片分割成一系列的区域。首先,候选区域法有较高的召回率,其次,候选区域法生成大量不同的候选区域供神经网络进行训练。我们后面会通过实验展示这些特性带来的优势。
分割产生的候选区域用于更新卷积神经网络,神经网络得到的特征图又被用于选择更好的候选区域。这两个过程不断迭代,我们后面会把这个过程总结成一个目标函数。
需要注意的是,候选区域只被用于神经网络的训练。训练好的FCN网络用于生成像素级的预测。所以候选区域的分割并不影响模型的测试时间,(不影响模型效率)
4.2公式
我们将使用候选区域法生成分割掩码作为图片预处理。默认情况下是使用Multiscale Combinational Grouping(MCG),不过其他方式也被实验过。实验中,我们平均每张图片生成2000个候选区域。在整个训练过程中,候选区域是固定的。但是训练过程中,每个候选区域会被赋予一个标签,可以是一个前景类别,也可以是背景。训练中,赋予候选区域的标签会变化。
对于一张带有目标区域标注的图片,我们希望产生的候选区域可以覆盖尽可能多的目标区域,我们顶一个了一个公式来表示目标区域的覆盖程度:
![]()
s表示所有的候选区域集合,B表目标边框真值,IOU(B,S)在[0,1]之间,表示真实目标边框和候选区域组成区域的交并比,δ表示一个函数,如果给某个候选区域的娥标签和真实标签一直,其值为1,否则为0。N为候选区域的数量。当Iou大并且标签预测准确时,上式取最小值。对于一个真实的目标框,我们只允许存在一个非背景候选区域。在收敛的情况下,多个目标框重叠的区域被分配给最小的候选区域。
有了这些候选区域和它们的标签,我们就可以按照公式1来监督深度卷积网络的训练。通常我们使用以下目标函数
![]()
除了用于监督训练的目标区域外,这个函数和公式一是一样的
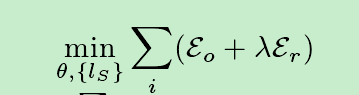
我们将两个函数合成一个目标函数,求和操作时求整个图像的目标函数之和,λ=3是一个固定的参数,可以改变的部分是神经网络的参数和候选区域的标签 ls。如果优化后只有Eo损失项,则演变为根据目标边框寻找iou最大的候选取,如果只有Er,则变的于FCN一样。(没看懂)我们提出的公式同时考虑了以上两项。


















 391
391

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









