






简要介绍图中的优化算法,编程实现并2D可视化
1. 被优化函数 

a.SGD
11.4. 随机梯度下降 — 动手学深度学习 2.0.0 documentation (d2l.ai)
随机梯度下降法(stochastic gradient descent,SGD)-优快云博客

随机梯度下降法(SGD)是一种用于支持向量机、逻辑回归等凸损失函数下的线性分类器学习的简单而有效的方法,也成功应用于文本分类和自然语言处理中的大规模稀疏机器学习问题。
该算法通过随机抽取一组样本进行训练,并根据梯度更新模型参数,因此在大规模样本情况下可能不需要训练完所有样本即可获得满意的模型。其特点包括每次迭代使用一组样本以及样本打乱以减小参数更新抵消问题。
相比于梯度下降法,SGD的步长较小,并且使用近似梯度,这使得它不容易陷入局部最优解,但同时也导致准确度下降、可能收敛到局部最优以及不易并行实现等缺点。
此外,SGD算法还有三种不同的应用方式,包括SGD、Batch-SGD和Mini-Batch SGD,它们分别使用单个样本、全部样本和一小批样本进行参数更新,各自具有特定的优缺点。
更新公式:

from nndl.op import Op
import torch
import numpy as np
from matplotlib import pyplot as plt
from nndl.opitimizer import SimpleBatchGD
# 被优化函数
class OptimizedFunction(Op):
def __init__(self, w):
super(OptimizedFunction, self).__init__()
self.w = w
self.params = {'x': 0}
self.grads = {'x': 0}
def forward(self, x):
self.params['x'] = x
return torch.matmul(self.w.T, torch.tensor(torch.square(self.params['x']), dtype=torch.float32))
def backward(self):
self.grads['x'] = 2 * torch.multiply(self.w.T, self.params['x'])
# SGD梯度更新
import copy
def train_f(model, optimizer, x_init, epoch):
x = x_init
all_x = []
losses = []
for i in range(epoch):
all_x.append(copy.copy(x.numpy()))
loss = model(x)
losses.append(loss)
model.backward()
optimizer.step()
x = model.params['x']
print(all_x)
return torch.tensor(all_x), losses
# 可视化
class Visualization(object):
def __init__(self):
"""
初始化可视化类
"""
# 只画出参数x1和x2在区间[-5, 5]的曲线部分
x1 = np.arange(-5, 5, 0.1)
x2 = np.arange(-5, 5, 0.1)
x1, x2 = np.meshgrid(x1, x2)
self.init_x = torch.tensor([x1, x2])
def plot_2d(self, model, x, fig_name):
"""
可视化参数更新轨迹
"""
fig, ax = plt.subplots(figsize=(10, 6))
cp = ax.contourf(self.init_x[0], self.init_x[1], model(self.init_x.transpose(0, 1)),
colors=['#e4007f', '#f19ec2', '#e86096', '#eb7aaa', '#f6c8dc', '#f5f5f5', '#000000'])
c = ax.contour(self.init_x[0], self.init_x[1], model(self.init_x.transpose(0, 1)), colors='black')
cbar = fig.colorbar(cp)
ax.plot(x[:, 0], x[:, 1], '-o', color='#000000')
ax.plot(0, 'r*', markersize=18, color='#fefefe')
ax.set_xlabel('$x1$')
ax.set_ylabel('$x2$')
ax.set_xlim((-2, 5))
ax.set_ylim((-2, 5))
plt.savefig(fig_name)
plt.show()
def train_and_plot_f(model, optimizer, epoch, fig_name):
"""
训练模型并可视化参数更新轨迹
"""
# 设置x的初始值
x_init = torch.tensor([3, 4], dtype=torch.float32)
print('x1 initiate: {}, x2 initiate: {}'.format(x_init[0].numpy(), x_init[1].numpy()))
x, losses = train_f(model, optimizer, x_init, epoch)
print(x)
losses = np.array(losses)
# 展示x1、x2的更新轨迹
vis = Visualization()
vis.plot_2d(model, x, fig_name)
# 固定随机种子
torch.manual_seed(0)
w = torch.tensor([0.2, 2])
model = OptimizedFunction(w)
opt = SimpleBatchGD(init_lr=0.2, model=model)
train_and_plot_f(model, opt, epoch=20, fig_name='opti-vis-para.pdf')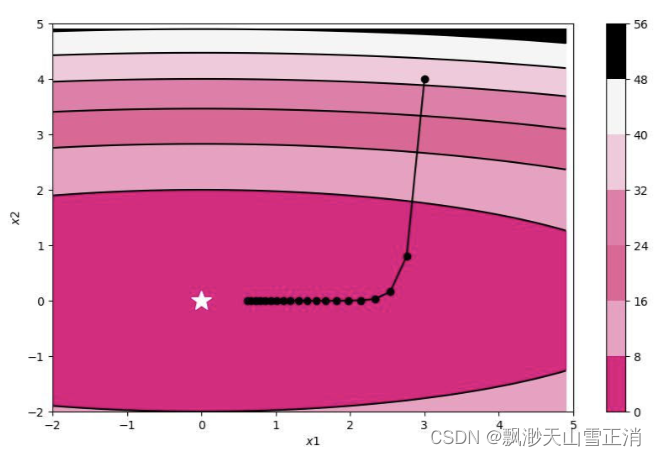
b.Adagrad
11.7. AdaGrad算法 — 动手学深度学习 2.0.0 documentation (d2l.ai)
【快速理解Adagrad】通俗解释Adagrad梯度下降算法-优快云博客

Adagrad 的核心想法就是,如果一个参数的梯度一直都非常大,那么其对应的学习率就变小一点,防止震荡,而一个参数的梯度一直都非常小,那么这个参数的学习率就变大一点,使得其能够更快地更新,这就是Adagrad算法加快深层神经网络的训练速度的核心。
Adagrad优化算法就是在每次使用一个 batch size 的数据进行参数更新的时候,算法计算所有参数的梯度,那么其想法就是对于每个参数,初始化一个变量 s 为 0,然后每次将该参数的梯度平方求和累加到这个变量 s 上,然后在更新这个参数的时候,学习率就变为:

如上为Adagrad算法的公式
首先η为初始学习率,这里的 ϵ是为了数值稳定性而加上的,因为有可能 s 的值为 0,那么 0 出现在分母就会出现无穷大的情况,通常 ϵ 取 10的负10次方,这样不同的参数由于梯度不同,他们对应的 s 大小也就不同,所以上面的公式得到的学习率也就不同,这也就实现了自适应的学习率。
我们使用自适应的学习率就可以帮助算法在梯度大的参数方向减缓学习速率,而在梯度小的参数方向加快学习速率,这就可以促使神经网络的训练速度的加快。
class Adagrad(Optimizer):
def __init__(self, init_lr, model, epsilon):
"""
Adagrad 优化器初始化
输入:
- init_lr: 初始学习率
- model:模型,model.params存储模型参数值
- epsilon:保持数值稳定性而设置的非常小的常数
"""
super(Adagrad, self).__init__(init_lr=init_lr, model=model)
self.G = {}
for key in self.model.params.keys():
self.G[key] = 0
self.epsilon = epsilon
def adagrad(self, x, gradient_x, G, init_lr):
"""
adagrad算法更新参数,G为参数梯度平方的累计值。
"""
G += gradient_x ** 2
x -= init_lr / torch.sqrt(G + self.epsilon) * gradient_x
return x, G
def step(self):
"""
参数更新
"""
for key in self.model.params.keys():
self.model.params[key], self.G[key] = self.adagrad(self.model.params[key],
self.model.grads[key],
self.G[key],
self.init_lr)
torch.manual_seed(0)
w = torch.tensor([0.2, 2])
model = OptimizedFunction(w)
opt = Adagrad(init_lr=0.5, model=model, epsilon=1e-7)
train_and_plot_f(model, opt, epoch=50, fig_name='opti-vis-para2.pdf')
plt.show()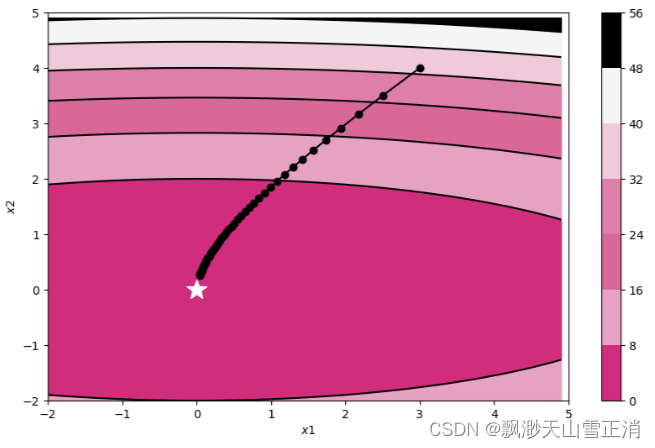
c.RMSprop
11.8. RMSProp算法 — 动手学深度学习 2.0.0 documentation (d2l.ai)


class RMSprop(Optimizer):
def __init__(self, init_lr, model, beta, epsilon):
"""
RMSprop优化器初始化
输入:
- init_lr:初始学习率
- model:模型,model.params存储模型参数值
- beta:衰减率
- epsilon:保持数值稳定性而设置的常数
"""
super(RMSprop, self).__init__(init_lr=init_lr, model=model)
self.G = {}
for key in self.model.params.keys():
self.G[key] = 0
self.beta = beta
self.epsilon = epsilon
def rmsprop(self, x, gradient_x, G, init_lr):
"""
rmsprop算法更新参数,G为迭代梯度平方的加权移动平均
"""
G = self.beta * G + (1 - self.beta) * gradient_x ** 2
x -= init_lr / torch.sqrt(G + self.epsilon) * gradient_x
return x, G
def step(self):
"""参数更新"""
for key in self.model.params.keys():
self.model.params[key], self.G[key] = self.rmsprop(self.model.params[key],
self.model.grads[key],
self.G[key],
self.init_lr)
# 固定随机种子
torch.manual_seed(0)
w = torch.tensor([0.2, 2])
model = OptimizedFunction(w)
opt = RMSprop(init_lr=0.1, model=model, beta=0.9, epsilon=1e-7)
train_and_plot_f(model, opt, epoch=50, fig_name='opti-vis-para3.pdf')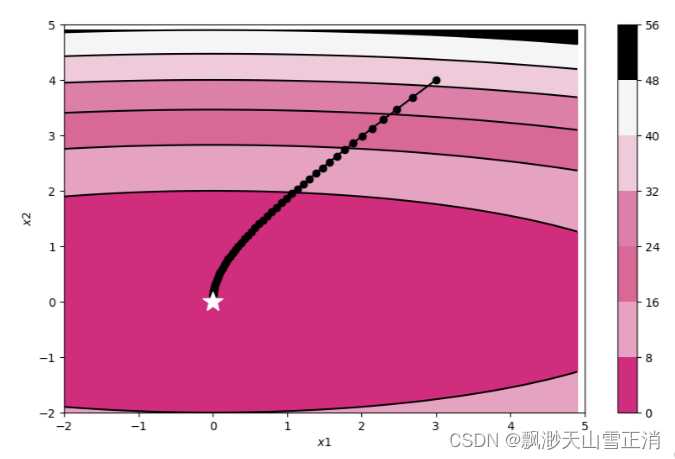
e.Momentum
11.6. 动量法 — 动手学深度学习 2.0.0 documentation (d2l.ai)

该算法将一段时间内的梯度向量进行了加权平均,分别计算得到梯度更新过程中 w和 b的大致走向,一定程度上消除了更新过程中的不确定性因素(如摆动现象),使得梯度更新朝着一个越来越明确的方向前进。
class Momentum(Optimizer):
def __init__(self, init_lr, model, rho):
"""
Momentum优化器初始化
输入:
- init_lr:初始学习率
- model:模型,model.params存储模型参数值
- rho:动量因子
"""
super(Momentum, self).__init__(init_lr=init_lr, model=model)
self.delta_x = {}
for key in self.model.params.keys():
self.delta_x[key] = 0
self.rho = rho
def momentum(self, x, gradient_x, delta_x, init_lr):
"""
momentum算法更新参数,delta_x为梯度的加权移动平均
"""
delta_x = self.rho * delta_x - init_lr * gradient_x
x += delta_x
return x, delta_x
def step(self):
"""参数更新"""
for key in self.model.params.keys():
self.model.params[key], self.delta_x[key] = self.momentum(self.model.params[key],
self.model.grads[key],
self.delta_x[key],
self.init_lr)
# 固定随机种子
torch.manual_seed(0)
w = torch.tensor([0.2, 2])
model = OptimizedFunction(w)
opt = Momentum(init_lr=0.01, model=model, rho=0.9)
train_and_plot_f(model, opt, epoch=50, fig_name='opti-vis-para4.pdf')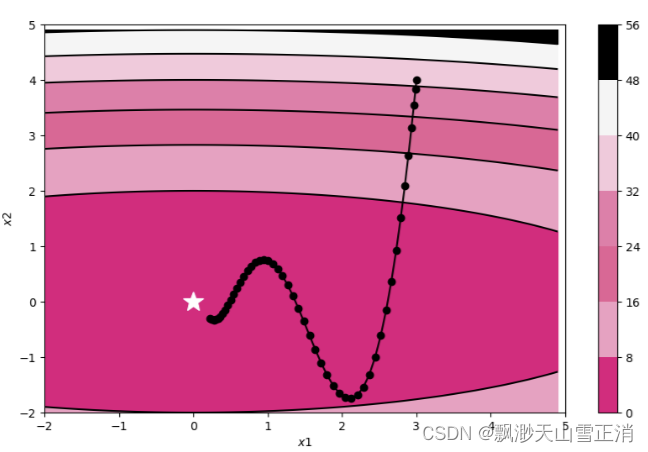
f.Adam
(1 封私信) 如何理解Adam算法(Adaptive Moment Estimation)? - 知乎 (zhihu.com)
11.10. Adam算法 — 动手学深度学习 2.0.0 documentation (d2l.ai)
Adam算法 (Kingma and Ba, 2014)将所有这些技术汇总到一个高效的学习算法中。 不出预料,作为深度学习中使用的更强大和有效的优化算法之一,它非常受欢迎。


class Adam(Optimizer):
def __init__(self, init_lr, model, beta1, beta2, epsilon):
"""
Adam优化器初始化
输入:
- init_lr:初始学习率
- model:模型,model.params存储模型参数值
- beta1, beta2:移动平均的衰减率
- epsilon:保持数值稳定性而设置的常数
"""
super(Adam, self).__init__(init_lr=init_lr, model=model)
self.beta1 = beta1
self.beta2 = beta2
self.epsilon = epsilon
self.M, self.G = {}, {}
for key in self.model.params.keys():
self.M[key] = 0
self.G[key] = 0
self.t = 1
def adam(self, x, gradient_x, G, M, t, init_lr):
"""
adam算法更新参数
输入:
- x:参数
- G:梯度平方的加权移动平均
- M:梯度的加权移动平均
- t:迭代次数
- init_lr:初始学习率
"""
M = self.beta1 * M + (1 - self.beta1) * gradient_x
G = self.beta2 * G + (1 - self.beta2) * gradient_x ** 2
M_hat = M / (1 - self.beta1 ** t)
G_hat = G / (1 - self.beta2 ** t)
t += 1
x -= init_lr / torch.sqrt(G_hat + self.epsilon) * M_hat
return x, G, M, t
def step(self):
"""参数更新"""
for key in self.model.params.keys():
self.model.params[key], self.G[key], self.M[key], self.t = self.adam(self.model.params[key],
self.model.grads[key],
self.G[key],
self.M[key],
self.t,
self.init_lr)
# 固定随机种子
torch.manual_seed(0)
w = torch.tensor([0.2, 2])
model = OptimizedFunction(w)
opt = Adam(init_lr=0.2, model=model, beta1=0.9, beta2=0.99, epsilon=1e-7)
train_and_plot_f(model, opt, epoch=20, fig_name='opti-vis-para5.pdf')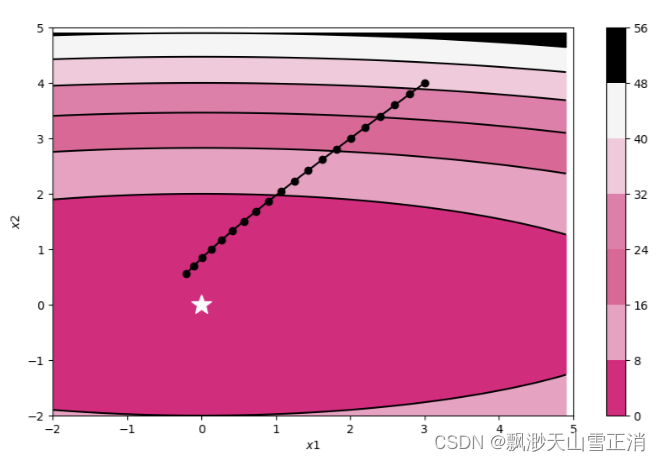
2. 被优化函数 

# coding: utf-8
import numpy as np
import matplotlib.pyplot as plt
from collections import OrderedDict
class SGD:
"""随机梯度下降法(Stochastic Gradient Descent)"""
def __init__(self, lr=0.01):
self.lr = lr
def update(self, params, grads):
for key in params.keys():
params[key] -= self.lr * grads[key]
class Momentum:
"""Momentum SGD"""
def __init__(self, lr=0.01, momentum=0.9):
self.lr = lr
self.momentum = momentum
self.v = None
def update(self, params, grads):
if self.v is None:
self.v = {}
for key, val in params.items():
self.v[key] = np.zeros_like(val)
for key in params.keys():
self.v[key] = self.momentum * self.v[key] - self.lr * grads[key]
params[key] += self.v[key]
class Nesterov:
"""Nesterov's Accelerated Gradient (http://arxiv.org/abs/1212.0901)"""
def __init__(self, lr=0.01, momentum=0.9):
self.lr = lr
self.momentum = momentum
self.v = None
def update(self, params, grads):
if self.v is None:
self.v = {}
for key, val in params.items():
self.v[key] = np.zeros_like(val)
for key in params.keys():
self.v[key] *= self.momentum
self.v[key] -= self.lr * grads[key]
params[key] += self.momentum * self.momentum * self.v[key]
params[key] -= (1 + self.momentum) * self.lr * grads[key]
class AdaGrad:
"""AdaGrad"""
def __init__(self, lr=0.01):
self.lr = lr
self.h = None
def update(self, params, grads):
if self.h is None:
self.h = {}
for key, val in params.items():
self.h[key] = np.zeros_like(val)
for key in params.keys():
self.h[key] += grads[key] * grads[key]
params[key] -= self.lr * grads[key] / (np.sqrt(self.h[key]) + 1e-7)
class RMSprop:
"""RMSprop"""
def __init__(self, lr=0.01, decay_rate=0.99):
self.lr = lr
self.decay_rate = decay_rate
self.h = None
def update(self, params, grads):
if self.h is None:
self.h = {}
for key, val in params.items():
self.h[key] = np.zeros_like(val)
for key in params.keys():
self.h[key] *= self.decay_rate
self.h[key] += (1 - self.decay_rate) * grads[key] * grads[key]
params[key] -= self.lr * grads[key] / (np.sqrt(self.h[key]) + 1e-7)
class Adam:
"""Adam (http://arxiv.org/abs/1412.6980v8)"""
def __init__(self, lr=0.001, beta1=0.9, beta2=0.999):
self.lr = lr
self.beta1 = beta1
self.beta2 = beta2
self.iter = 0
self.m = None
self.v = None
def update(self, params, grads):
if self.m is None:
self.m, self.v = {}, {}
for key, val in params.items():
self.m[key] = np.zeros_like(val)
self.v[key] = np.zeros_like(val)
self.iter += 1
lr_t = self.lr * np.sqrt(1.0 - self.beta2 ** self.iter) / (1.0 - self.beta1 ** self.iter)
for key in params.keys():
self.m[key] += (1 - self.beta1) * (grads[key] - self.m[key])
self.v[key] += (1 - self.beta2) * (grads[key] ** 2 - self.v[key])
params[key] -= lr_t * self.m[key] / (np.sqrt(self.v[key]) + 1e-7)
def f(x, y):
return x ** 2 / 20.0 + y ** 2
def df(x, y):
return x / 10.0, 2.0 * y
init_pos = (-7.0, 2.0)
params = {}
params['x'], params['y'] = init_pos[0], init_pos[1]
grads = {}
grads['x'], grads['y'] = 0, 0
learningrate = [0.9, 0.3, 0.3, 0.6, 0.6, 0.6, 0.6]
optimizers = OrderedDict()
optimizers["SGD"] = SGD(lr=learningrate[0])
optimizers["Momentum"] = Momentum(lr=learningrate[1])
optimizers["Nesterov"] = Nesterov(lr=learningrate[2])
optimizers["AdaGrad"] = AdaGrad(lr=learningrate[3])
optimizers["RMSprop"] = RMSprop(lr=learningrate[4])
optimizers["Adam"] = Adam(lr=learningrate[5])
idx = 1
id_lr = 0
for key in optimizers:
optimizer = optimizers[key]
lr = learningrate[id_lr]
id_lr = id_lr + 1
x_history = []
y_history = []
params['x'], params['y'] = init_pos[0], init_pos[1]
for i in range(30):
x_history.append(params['x'])
y_history.append(params['y'])
grads['x'], grads['y'] = df(params['x'], params['y'])
optimizer.update(params, grads)
x = np.arange(-10, 10, 0.01)
y = np.arange(-5, 5, 0.01)
X, Y = np.meshgrid(x, y)
Z = f(X, Y)
# for simple contour line
mask = Z > 7
Z[mask] = 0
# plot
plt.subplot(2, 3, idx)
idx += 1
plt.plot(x_history, y_history, 'o-', color="r")
# plt.contour(X, Y, Z) # 绘制等高线
plt.contour(X, Y, Z, cmap='gray') # 颜色填充
plt.ylim(-10, 10)
plt.xlim(-10, 10)
plt.plot(0, 0, '+')
# plt.axis('off')
# plt.title(key+'\nlr='+str(lr), fontstyle='italic')
plt.text(0, 10, key + '\nlr=' + str(lr), fontsize=20, color="b",
verticalalignment='top', horizontalalignment='center', fontstyle='italic')
plt.xlabel("x")
plt.ylabel("y")
plt.subplots_adjust(wspace=0, hspace=0) # 调整子图间距
plt.show()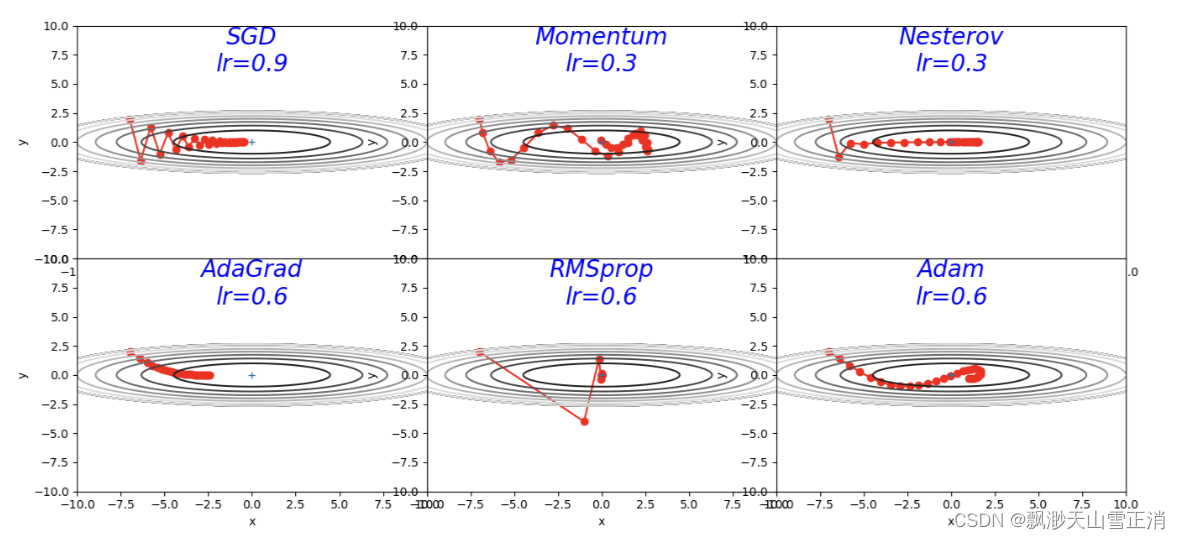
3. 解释不同轨迹的形成原因,分析各个算法的优缺点
深度学习最全优化方法总结比较(SGD,Adagrad,Adadelta,Adam,Adamax,Nadam) - 知乎 (zhihu.com)
11.7. AdaGrad算法 — 动手学深度学习 2.0.0 documentation (d2l.ai)
轨迹形成原因
- SGD: 因为y方向变化很大,x方向变化很小,导致“之”字形的轨迹,效率较低。
- AdaGrad: 利用历史梯度信息自适应地调整学习率,能够更好地处理不同参数之间的差异,从而提高了训练效率和模型的性能。
- RMSprop: 使用指数加权移动平均来计算历史梯度平方和,可以更有效地收敛到损失函数的最小值。
- Momentum: 收敛路径以一种有所抑制的振荡模式接近最小值,引入了动量的概念,有助于加速收敛速度和减少震荡。
- Nesterov: 是对动量法的改进,根据当前动量在预期的未来位置计算梯度,能够更快地收敛到最优解,减少参数更新的振荡。
- Adam: 结合了动量法和RMSprop算法,具有自适应学习率和收敛速度快的特点。
算法优缺点
-
SGD:
- 优点:计算开销小,适用于大规模数据集,易于实现。
- 缺点:收敛速度相对较慢,抖动,需要调整学习率,不利于处理稀疏数据。
-
AdaGrad:
- 优点:自适应学习率,适用于稀疏数据,泛化性能好,易于实现。
- 缺点:学习率下降太快,不适用于非凸函数。
-
RMSprop:
- 优点:自适应学习率,适用于非凸函数,泛化性能好,易于实现。
- 缺点:需要调节超参数,可能会出现震荡。
-
Momentum:
- 优点:加速收敛,减少震荡,适用于高曲率的情况,容易跳出局部最小值。
- 缺点:可能会超调,需要调优学习率和动量参数,可能受到噪声影响。
-
Nesterov:
- 优点:更快的收敛速度,减少参数更新的振荡,更好的参数更新估计,更容易跳出局部最小值。
- 缺点:需要调节学习率和动量参数,计算复杂度略高。
-
Adam:
- 优点:自适应学习率,快速收敛,对稀疏梯度适应性强,不需要手动调节学习率参数。
- 缺点:对小批量样本敏感,对超参数敏感,内存消耗较大。
REF:图灵社区-图书 (ituring.com.cn)
深度学习入门:基于Python的理论与实现




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









