







 博主分享了参与Quora Insincere Questions Classification竞赛的经验,通过Kaggle Kernel进行实践。文章探讨了文本特征、模型融合、词向量组合、参数调整、梯度分布处理、数据增强、后处理和模型复现等多个方面,总结了在预训练词向量、特征工程和模型优化上的尝试,包括使用fasttext、glove、paragram等词向量,以及应用dropout、batch normalization等技术。尽管取得了一定的进步,但线上得分仍面临挑战。
博主分享了参与Quora Insincere Questions Classification竞赛的经验,通过Kaggle Kernel进行实践。文章探讨了文本特征、模型融合、词向量组合、参数调整、梯度分布处理、数据增强、后处理和模型复现等多个方面,总结了在预训练词向量、特征工程和模型优化上的尝试,包括使用fasttext、glove、paragram等词向量,以及应用dropout、batch normalization等技术。尽管取得了一定的进步,但线上得分仍面临挑战。
博主大三,一月中旬期末考试结束之后都放在这个比赛上面了--Quora Insincere Questions Classification。
大半个月过来,做了很多尝试,线下成绩提高了不少,线上LB的成绩还是原地踏步 :)。
现在来总结一下自己做过的一些工作,给大家以及自己一些参考反思。如果各路大佬有更好的idea,欢迎骚扰交流~
该竞赛是个典型的文本二分类问题,用的是美国的知乎(quora),来评判这个帖子是不是水帖。竞赛中最关键的要求有三点:
1、只能使用 Kaggle Kernel 中生成的 submission.csv 来提交;
2、不能使用外部数据,也就是说 embedding 也只能用 Kernel 里提供的四个 embedding 文件;
3、Kernel 的 GPU 运行时间不能超过 120 分钟。
4、不能连接网络
目前我的LB得分是0.700,借鉴的是jetou大佬提供的pytorch 版本的代码。具体的模型结构图如下:
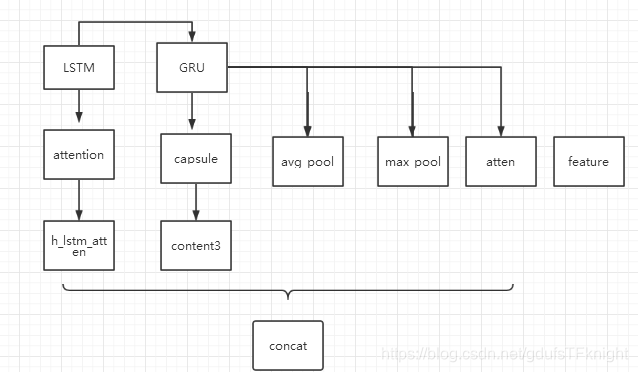
这个版本的kernel 得分已经很高了(铜牌区),再次感谢open source 。我也在这个代码的基础上做了一些改进:
一、输入特征方面:
在文本特征上面,我从数据集中抽取了以下几种:
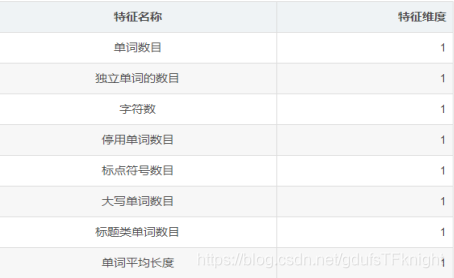
把以上八维的特征来做为新的text_feature 加入到原来的两维 ['caps_vs_length', 'words_vs_unique'] 里面去。public score:696
这里贴出觉得很赞的文本特征抽取代码:https://www.kaggle.com/kaggleczs/lgb-with-features-engineering
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









