



 本文介绍了一种将神经网络权重和激活值量化为8位整数的方案,以提高移动设备上的模型运行效率。该方法在训练时使用特殊量化策略,并在推断时转换为整数运算,有效减少了计算资源需求。
本文介绍了一种将神经网络权重和激活值量化为8位整数的方案,以提高移动设备上的模型运行效率。该方法在训练时使用特殊量化策略,并在推断时转换为整数运算,有效减少了计算资源需求。
论文地址:https://arxiv.org/pdf/1712.05877.pdf
主要内容
目前,将复杂的神经网络部署到小的移动设备上的主流方法有两种:一是设计一种体量小且高效的网络结构,如MobileNet、SqueezeNet、ShuffleNet和DenseNet等;另一种就是将网络的权重和激活值由原本的32位浮点数量化为低精度的定点数,即模型量化。
作者的主要贡献为:
- 提出一种量化方案,将权重和激活值量化为8bit的整数,而部分参数(如偏差向量)量化为32bit整数;
- 提出一种新的量化框架。
量化方案
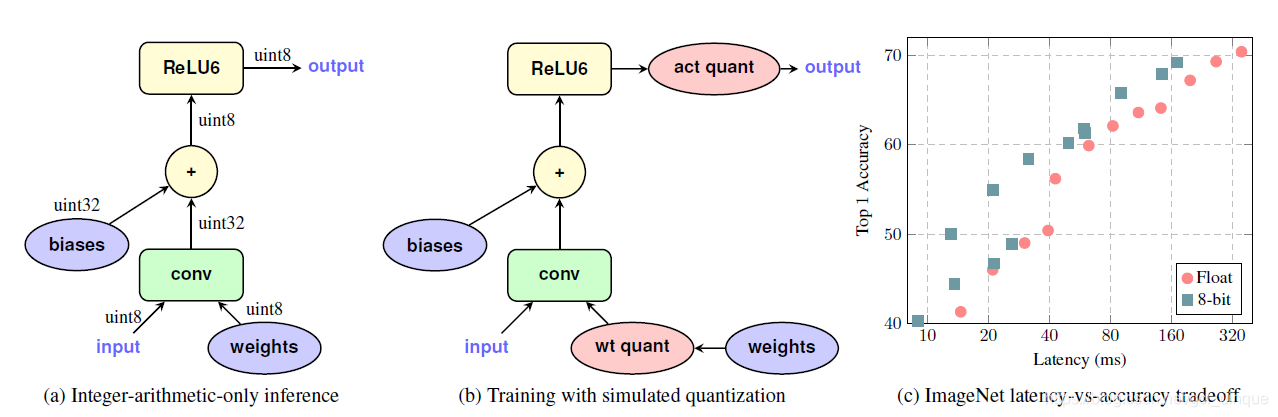
该方案是在推断时用整数运算,在训练时使用新的量化方法。如下图:
令r为实数,q为量化值,则量化公式为:

其中,常数S、Z是量化参数。S(scale)是正实数,通常为浮点数;Z(零点)和量化值q类型一样,实际上就是实数0对应的量化值。每一层采用相同的量化参数。
现在考虑N×NN \times NN×N矩阵r1,r2r_1,r_2r1,r2,令r3=r1r2r_3=r_1r_2r3=r1r2,由公式(1)可得:
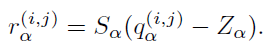
其中下标为1,2,3,上标表示对应矩阵中的元素。则有:
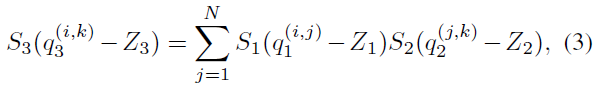
重写为:
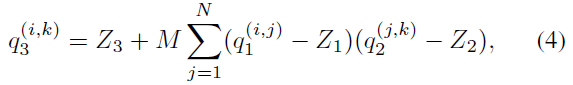
其中,

显然,M可直接由超参数S1,S2,S3S_1,S_2,S_3S1,S2,S3计算出。公式(4)除了M外全是整数,因此需要将M进行处理。根据经验M总是在区间(0,1)内,故此可由下式公式得出:

其中,M0M_0M0在区间[0.5,1)内,nnn为非负整数。举个例子,用int32表示M0M_0M0,因为M0≥0.5M_0 \geq 0.5M0≥0.5,所以int32表示的M0M_0M0范围为[230,231)[2^{30},2^{31})[230,231)。这样”乘以M“这一浮点运算就转化为整数运算和2−n2^{-n}2−n这一移位运算的合成。
为了减少运算次数,对公式(4)进行处理:
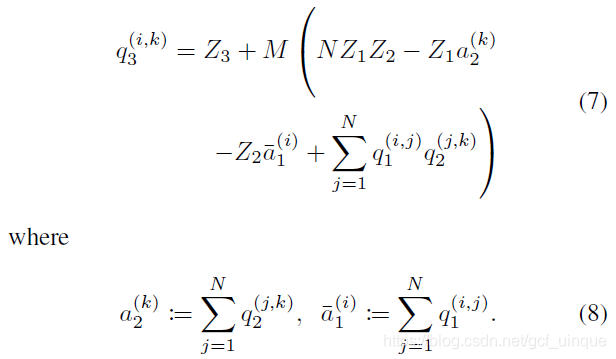
显然,公式(8)的运算次数为2N22N^22N2,剩余的运算(2N32N^32N3)全集中在下式:
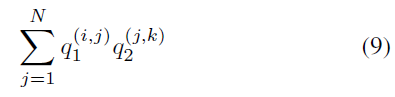
uint8的乘法的累积运算需要用uint32来存储:
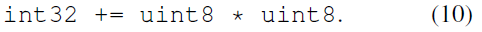
为了加入偏置,将其表示为int32,对应的量化参数为(用0作为零点):
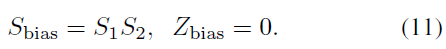
然后可以将rbias=Sbiasqbias=S1S2qbiasr_{bias}=S_{bias}q_{bias}=S_1S_2q_{bias}rbias=Sbiasqbias=S1S2qbias加到公式(3)的右边,接下来按上述步骤转化为类似公式(7)的形式,再将其截取到[0,255]范围,实现uint8的输出。在实践中,激活函数的作用被clamp(0,255)替代,故此不需要。
模拟量化训练
训练量化网络常用方法是先用浮点数训练,再量化权重。但是这种方法对于小型网络并不适用,会导致精度下降,究其原因,有:
- 每层的不同输出通道的权重差距很大(超过100倍);
- 异常的权重值会导致其他权重量化精度下降。
因此,作者提出了模拟量化方法:
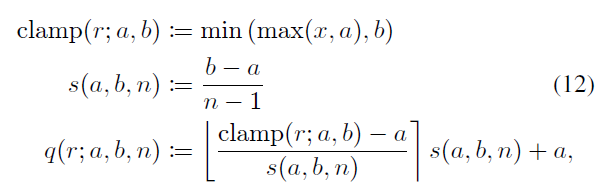
这和DoReFa-Net的quantize相反,先缩小取整再放大。
实验
作者还在不同的数据集上进行实验,验证量化方法的性能,有时间可以看看。

















 4172
4172

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









