







 本文探讨了一种新型的域适应场景——预测域适应(PDA),旨在处理零样本和增量环境下源域与目标域之间的数据分布差异。通过引入辅助域及元数据,提出AdaGraph算法,构建域间关系图,实现跨域模型参数预测。
本文探讨了一种新型的域适应场景——预测域适应(PDA),旨在处理零样本和增量环境下源域与目标域之间的数据分布差异。通过引入辅助域及元数据,提出AdaGraph算法,构建域间关系图,实现跨域模型参数预测。
文章目录
自适应图:一统零样本、增量域适应问题
| 定义 | 源域 | 目标域 | 辅助域 |
|---|---|---|---|
| domain adaptation | 标注数据 | 无标注数据 | 无 |
| predictive domain adaptation | 标注数据 | 无数据 | 有 |
| continuous domain adaptation | 连续接收 |
从标题来看,我把predictive和continuous分别理解成,零样本和增量场景。
请描述一下source, target和 auxiliary的关系?从定义看,目标域不必属于源域。
元数据在训练阶段以及测试阶段如何使用?元数据是作为源域和目标域的先验知识来使用的。
摘要
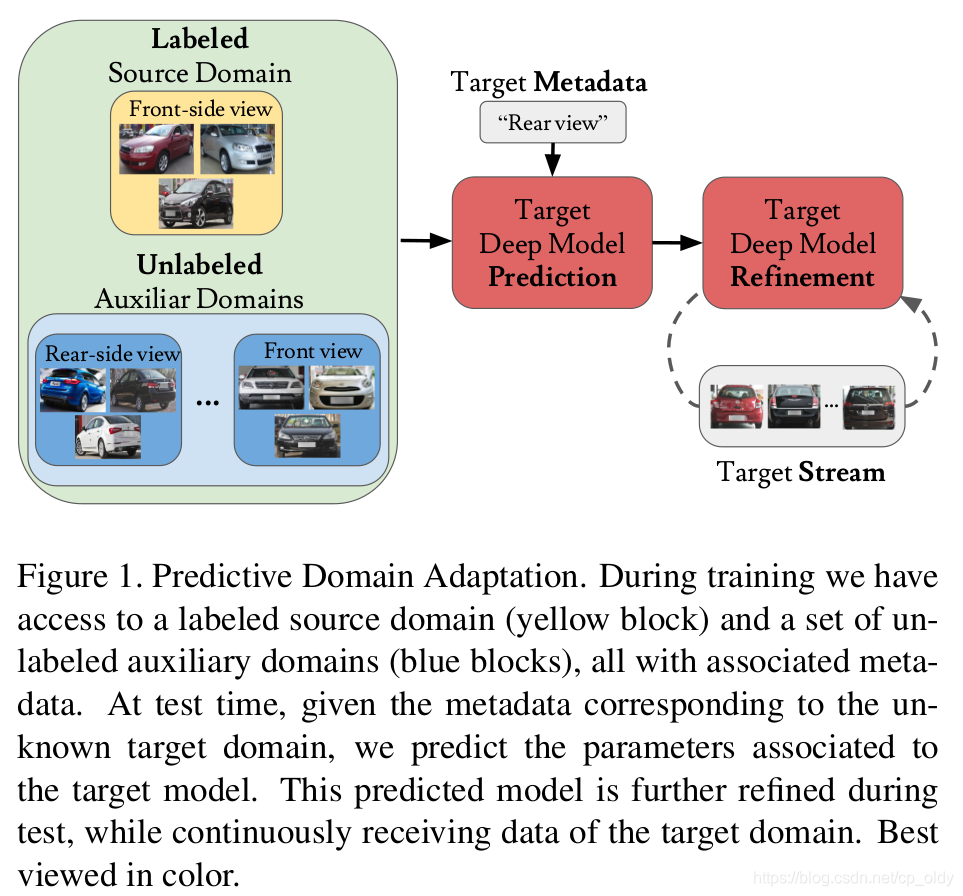
论文定义了域适应的一种场景,预测域适应 PDA,没有目标域数据,系统需要从标注的源域数据和辅助域带有元数据的无标注样本。
问题来了?
什么是辅助域?在PDA当中有多个源域,本文中的辅助域指的是没有标注数据的源域。
样本的元数据是什么?答:对应的图片时间戳或者对应的相机姿势等。在数据集Comprehensive Cars中,指的是拍摄角度和车的生产年份。
从图1来看,辅助域就是传统域适应里的目标域的图片,但是还没有搞清楚,这里的“目标域”和辅助域之间的关系。元数据就是通过这些样本得到的图。这些图代表了一些先验信息,使得在测试阶段给定目标域的元数据的时候,可以对目标域很好的预测。
我们理一下训练阶段和测试阶段都有什么?
- 训练阶段:目标域标注样本及其元数据,辅助域无标注样本及其元数据
- 测试阶段:目标域无标注数据及其元数据,在“增量情况下”目标域数据及其元数据在增长
引言
域适应的本质问题是什么?
现象是在一个数据集上效果很好的模型,在另一个数据集上效果不好。原因是光照变化、视角变化等变化导致的在视觉数据(图像、视频)中的外观变化。视觉数据中的外观变化产生了域漂移问题,也就是说模型的判别准则是和视觉变化是有莫大关系。那域适应目标就是要克服这些视觉变化,让模型能够更好的识别目标。其实,抽象一点来说,就是需要模型能够提取更高层的语义信息、减少对底层信息的依赖,适应不同视觉变化下的目标。也就是学习所谓的,域不变表示,domain invariant representation。
域适应解决的是源域和目标域分布不匹配的问题,目的是为目标域训练一个精准的预测模型。在无监督域适应中,目标域只有无标注的数据。但是,在实际当中,并不是所有的目标域都能收集到无标注数据。所以,为了更实际的情况,我们旨在得到能够泛化到新的之前没有见过的目标域。
DA -> unsupervised DA -> predictive DA (PDA)
predictIve DA类似于ZSL。两者的情况都是目标域没有任何数据。
ZSL中有GZSL,那么PDA是否对源域样本也进行测试?
辅助域的图是如何构建的?
图是建立在辅助域的元数据和辅助样本上,这些图描述了域之间的依赖关系。
节点:表示一个域;
边:表示域之间的关系。
相关工作
1. 无监督深度域适应
无
监
督
深
度
域
适
应
{
对
齐
策
略
:
学
习
域
不
变
表
示
对齐网络
对
抗
策
略
:
学
习
域
不
知
表
示
GAN-based
{
生
成
像
目
标
域
的
源
域
样
本
生
成
像
源
域
的
目
标
域
样
本
无监督深度域适应 \begin{cases} 对齐策略:学习域不变表示& \text{对齐网络}\\ 对抗策略:学习域不知表示& \text{ GAN-based$ \begin{cases} 生成像目标域的源域样本\\ 生成像源域的目标域样本 \end{cases}$} \end{cases}
无监督深度域适应⎩⎪⎨⎪⎧对齐策略:学习域不变表示对抗策略:学习域不知表示对齐网络 GAN-based{生成像目标域的源域样本生成像源域的目标域样本
许多方法使用多个源域来解决DA问题,即multi-source DA。本文的方法,也使用了多源,但是只有一个源有标注数据。
2. 无目标域数据的域适应
对于没有目标域数据的域适应,一般有两种策略,一种是利用不断到来的目标域数据,一种是利用描述可能的未来的目标域的辅助信息。
第一种,也就是continuous or online DA,即在线DA。
第二种,PDA。
其他相近概念,zero-shot domain adaptation, domain generalization。不同的是,在zero-shot DA中,会用到域无关的双域配对数据;在domain generalization中会用到多个源域的数据,但是是数据是有标注的,而在PDA中辅助集数据是没有标注的。
方法
概览
源域和目标域的基础框架一样,针对不同的域微调框架参数。文中拿分类任务举例。
对分类任务,文中建立了一个统一的神经网络模型。该模型有卷积层,全连接层和正则化层(batch-normalization layer)组成。作者认为,对每个域,卷积层和全连接层的参数是一样的。对不同的域,正则化层的参数不一样。所以1. 探求域与正则化层参数之间的关系。2.利用该关系调整目标域的参数
数据
- 已知域
K
\mathcal{K}
K,元数据
m
k
m_k
mk
- 源域 S \mathcal{S} S,有标记数据
- 辅助域 A = { A 1 , A 2 , ⋯   , A n } \mathcal{A}=\{ A_1,A_2,\cdots,A_n \} A={A1,A2,⋯,An},无标记数据 - 目标域为 T \mathcal{T} T,元数据 m t m_t mt,训练阶段数据不可见
AdaGraph: Graph-based Predictive DA
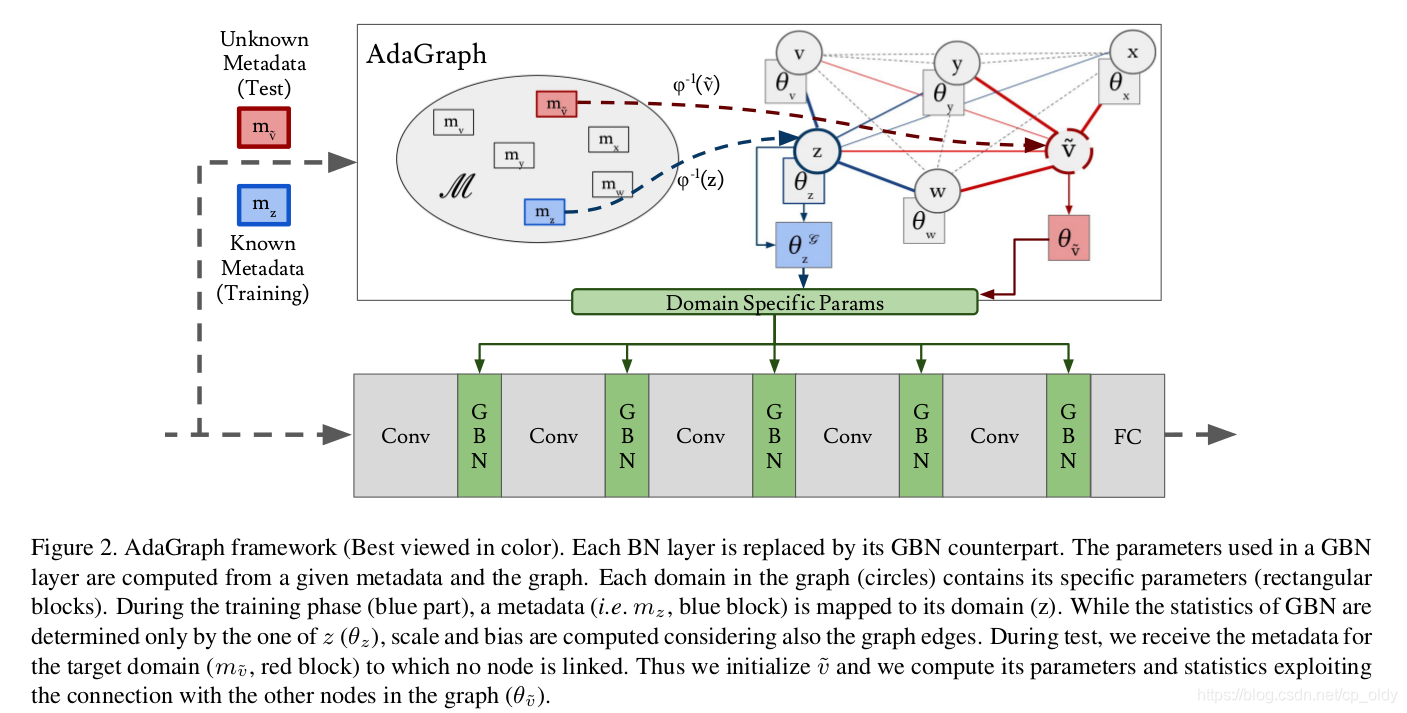
用图连接域
记已知域集合
K
=
{
k
1
,
k
2
,
⋯
 
,
k
n
}
\mathcal{K}=\{ k_1,k_2,\cdots,k_n \}
K={k1,k2,⋯,kn},元数据
m
k
∈
M
m_k \in \mathcal{M}
mk∈M.
定义图
G
=
(
V
,
ε
)
\mathcal{G}=(\mathcal{V},\varepsilon)
G=(V,ε),其中点集
V
\mathcal{V}
V是域,边
(
v
1
,
v
2
)
∈
ε
(v_1,v_2) \in \varepsilon
(v1,v2)∈ε代表域
v
1
,
v
2
v_1,v_2
v1,v2之间的关系。
文中定义了两个映射:
ϕ
:
K
→
M
\phi : \mathcal{K} \to \mathcal{M}
ϕ:K→M,将一个域映射为一个元数据
ψ
:
K
→
Θ
\psi: \mathcal{K} \to \Theta
ψ:K→Θ ,将一个域映射为一组模型参数
组合:
ψ
∘
ϕ
−
1
:
M
→
Θ
\psi\circ \phi^{-1}: \mathcal{M} \to \Theta
ψ∘ϕ−1:M→Θ ,通过元数据得到一组模型的参数
给定两个域
v
1
,
v
2
v_1,v_2
v1,v2,求它们边的权重:
w
(
v
1
,
v
2
)
=
e
−
d
(
ϕ
(
v
1
)
,
ϕ
(
v
2
)
)
w(v_1,v_2)=e^{-d(\phi(v_1),\phi(v_2))}
w(v1,v2)=e−d(ϕ(v1),ϕ(v2))
给定一个新的域(目标域
T
\mathcal{T}
T)要求它的模型参数:
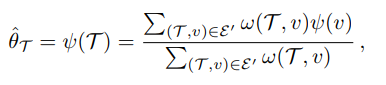
给定一张新的图片
x
x
x,求一组属于它的模型参数
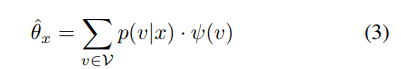
其中
p
(
v
∣
x
)
p(v|x)
p(v∣x)是指,样本
x
x
x属于域
v
v
v的概率
可学习的参数
我们将模型的参数分为两种:
ψ
(
k
)
=
{
θ
α
,
θ
k
s
}
\psi(k)=\{ \theta^{\alpha} , \theta^s_k \}
ψ(k)={θα,θks}
一种对每个域来说都一样,比如卷积层、全连接层。由源域数据做有监督的训练得到
一种是每个域都不一样的参数:正则化层的参数
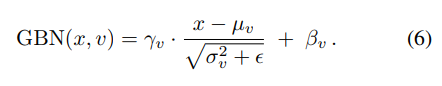
Experiments
扒开迷雾见青山,终于见到了元数据。
数据集
论文有三个数据集:Comprehensive Cars (CompCars), the Century of Portraits and the CarEvolution.
Comprehensive Cars: 136,726张图片,产自2004到2015年。论文选定了一个子集,24,151张图片,4种车型(MPV,SUV,sedan,hatchback),生产年份从2009年到2014年,5种视角(前方、侧前方、侧面、后方、侧后方)。把视角和生产年份作为独立的域,一共有5x6=30种域。其中,1个域作为源域,1个域作为目标域,剩下的28个域作为
元数据是二维向量, 车辆生产年份、拍照角度。
[
y
e
a
r
v
i
e
w
p
o
i
n
t
]
\left[ \begin{array}{ccc} year \\ view point \end{array} \right]
[yearviewpoint]
Century of Portraits:
元数据是三维向量,年代、南北方、东西。
[
d
e
c
a
d
e
l
a
t
i
t
u
d
e
e
a
s
t
−
w
e
s
t
p
o
s
i
t
i
o
n
]
\left[ \begin{array}{ccc} decade \\ latitude \\ east-west position \end{array} \right]
⎣⎡decadelatitudeeast−westposition⎦⎤

















 5188
5188

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









