







 本文介绍了无监督学习中的聚类和降维算法,如K-Means和PCA。通过实例展示了如何使用K-Means进行数据聚类分析,并进行了可视化。此外,文章还提及了机器学习的基础,包括数据预处理、监督学习和深度学习的相关概念和应用。
本文介绍了无监督学习中的聚类和降维算法,如K-Means和PCA。通过实例展示了如何使用K-Means进行数据聚类分析,并进行了可视化。此外,文章还提及了机器学习的基础,包括数据预处理、监督学习和深度学习的相关概念和应用。
引子
当前交通大数据业务的需要,需要承担一部分算法工作(数据处理)
目标一:
- 学习机器学习基础:了解机器学习的定义、分类和基本原理。
- 掌握数据预处理:学习数据清洗、特征选择和特征工程的基本方法。
目标任务:使用机器学习算法对一个简单的数据集进行数据预处理。
目标二:
- 学习监督学习算法:重点学习K-邻近、决策树和朴素贝叶斯算法,并理解它们的应用场景和原理。
目标任务:使用监督学习算法对一个分类问题进行建模和训练。
目标三:
- 学习无监督学习算法:学习聚类和降维算法,如K-Means、PCA等。
目标任务:使用无监督学习算法对一个数据集进行聚类分析。
目标四:
- 学习深度学习基础:了解神经网络的基本结构、反向传播算法和激活函数等。
目标任务:使用深度学习算法构建一个简单的神经网络模型,并训练模型。
目标五:
- 学习深度学习框架:学习使用PyTorch或TensorFlow等深度学习框架。
目标任务:使用深度学习框架搭建一个更复杂的神经网络,并在一个数据集上进行训练和测试。
学习计划小贴士:
-
每天定期复习前几天的内容,巩固知识。
-
在学习过程中遇到问题及时查阅资料,或向论坛、社区寻求帮助。
-
尝试在学习过程中动手实践,通过编写代码来加深对算法和原理的理解。
-
学习过程中保持积极的学习态度和耐心,机器学习和深度学习是复杂的领域,需要持续学习和实践。
-
学习机器学习基础:了解机器学习的定义、分类和基本原理。
-
掌握数据预处理:学习数据清洗、特征选择和特征工程的基本方法。
准备一份草稿,后面更新
学习无监督学习算法:聚类和降维
在机器学习领域,无监督学习是一个重要的分支,它允许我们从数据中提取有用的信息,而无需预先标记的目标。本篇博客将重点介绍无监督学习中的两个核心技术:聚类和降维。
什么是无监督学习?
在无监督学习中,我们面对的是没有目标标签或预测值的数据集。相反,我们的任务是从数据中发现模式、结构和信息。这使得无监督学习成为了探索性数据分析的有力工具。
聚类算法
2.1 K-Means 聚类
K-Means 是最常见的聚类算法之一,它将数据点划分为 K 个不同的簇,其中 K 是用户指定的超参数。该算法的工作流程如下:
随机初始化 K 个聚类中心点。
计算每个数据点到每个聚类中心的距离。
将每个数据点分配给距离最近的聚类中心。
更新聚类中心,取每个簇中所有数据点的平均值。
重复上述两个步骤,直到收敛。
K-Means 聚类可用于将数据点划分为不同的群组,用于市场细分、图像分割等应用。
2.2 其他聚类算法
除了 K-Means,还有许多其他聚类算法,如层次聚类、DBSCAN 等。每种算法都适用于不同类型的数据和问题。
降维算法
3.1 主成分分析(PCA)
主成分分析是一种常用的降维技术,它的目标是通过线性变换将高维数据映射到低维空间,同时最大程度地保留原始数据的方差。PCA 的工作原理如下:
计算数据的协方差矩阵。
计算协方差矩阵的特征值和特征向量。
选择前 k 个特征值对应的特征向量,构建变换矩阵。
使用变换矩阵将数据映射到低维空间。
PCA 常用于数据可视化、去除冗余信息以及降低模型复杂度。
目标任务:聚类分析
为了将所学应用到实际,我们将执行以下任务:
任务: 使用无监督学习算法对一个数据集进行聚类分析。
在这个任务中,我们将选择一个数据集,并应用聚类算法,比如 K-Means,来将数据点分为不同的簇。通过这个任务,我们将深入了解聚类算法的实际应用,以及如何通过数据分析发现内在的模式和结构。
无监督学习实践:数据聚类分析+结果可视化
- 数据准备
首先,我们需要选择一个数据集并进行数据准备。对于本次任务,我们选择了一个包含客户购买数据的超市销售数据集。数据集包括客户ID以及其购买的商品信息。
导入必要的库
import pandas as pd
读取数据集
data = pd.read_csv("sales_data.csv")
查看数据集的前几行
print(data.head())
数据集的样本如下:
import pandas as pd
import random
# 生成示例数据
data = {
"CustomerID": range(101, 201), # 客户ID从101到200
"ProductA": [random.randint(0, 10) for _ in range(100)], # 随机生成购买数量
"ProductB": [random.randint(0, 10) for _ in range(100)],
"ProductC": [random.randint(0, 10) for _ in range(100)],
"ProductD": [random.randint(0, 10) for _ in range(100)]
}
# 创建数据框
df = pd.DataFrame(data)
# 保存数据为 CSV 文件
df.to_csv("sales_data.csv", index=False)
CustomerID ProductA ProductB ProductC ProductD
0 101 2 3 0 1
1 102 0 1 4 2
2 103 1 4 0 3
3 104 3 2 1 0
4 105 0 1 5 2
- 特征标准化
为了应用聚类算法,我们通常需要对特征进行标准化,以确保它们具有相同的尺度。在这个例子中,我们将使用 StandardScaler 来标准化特征。
from sklearn.preprocessing import StandardScaler
提取特征
X = data.drop("CustomerID", axis=1)
标准化特征
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
查看标准化后的特征
print(pd.DataFrame(X_scaled, columns=X.columns).head())
- 聚类分析
现在,我们可以应用 K-Means 聚类算法来将客户分为不同的簇。假设我们希望将客户分为 3 个簇。
from sklearn.cluster import KMeans
创建 K-Means 模型
kmeans = KMeans(n_clusters=3, random_state=42)
训练模型
kmeans.fit(X_scaled)
获取簇标签
cluster_labels = kmeans.labels_
将簇标签添加到原始数据集
data["Cluster"] = cluster_labels
查看每个簇的统计信息
cluster_info = data.groupby("Cluster").mean()
print(cluster_info)
- 结果可视化
最后,我们可以通过可视化来展示聚类结果,以更好地理解客户分布情况。
import matplotlib.pyplot as plt
绘制不同簇的散点图
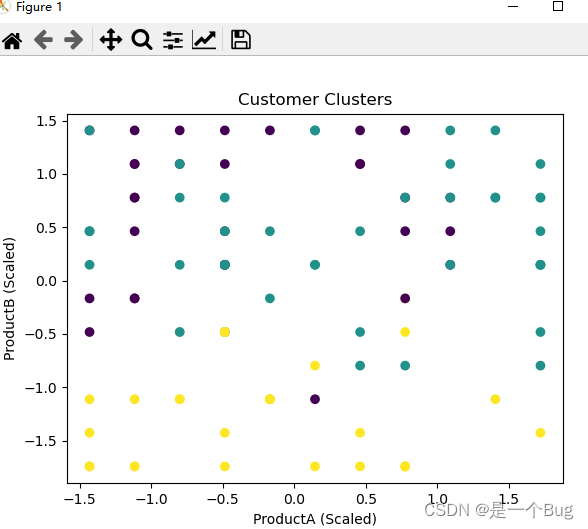
plt.scatter(X_scaled[:, 0], X_scaled[:, 1], c=cluster_labels, cmap="viridis")
plt.xlabel("ProductA (Scaled)")
plt.ylabel("ProductB (Scaled)")
plt.title("Customer Clusters")
plt.show()
通过上述步骤,我们成功地将客户分为不同的簇,并可视化了聚类结果。这个示例展示了如何使用无监督学习算法(K-Means)来探索和理解数据的内在结构,以及如何将无监督学习应用到实际业务问题中。
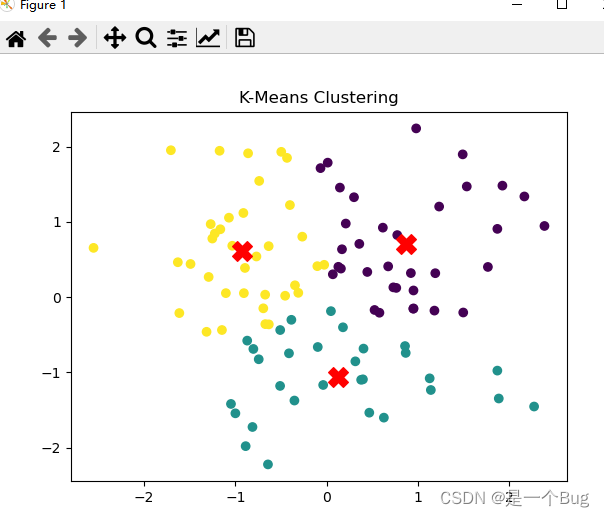
K-means可视化
import numpy as np
import matplotlib.pyplot as plt
# 生成随机数据作为示例
np.random.seed(0)
data = np.random.randn(100, 2)
# 定义 K-Means 参数
k = 3 # 聚类数
max_iterations = 100 # 最大迭代次数
# 随机初始化聚类中心
centers = data[np.random.choice(range(len(data)), k, replace=False)]
# 开始迭代
for i in range(max_iterations):
# 计算每个数据点到每个聚类中心的距离
distances = np.linalg.norm(data[:, np.newaxis] - centers, axis=2)
# 分配数据点到最近的聚类中心
labels = np.argmin(distances, axis=1)
# 更新聚类中心为每个簇的平均值
new_centers = np.array([data[labels == j].mean(axis=0) for j in range(k)])
# 检查聚类中心是否收敛
if np.all(centers == new_centers):
break
centers = new_centers
# 可视化聚类结果
plt.scatter(data[:, 0], data[:, 1], c=labels, cmap='viridis')
plt.scatter(centers[:, 0], centers[:, 1], c='red', marker='X', s=200)
plt.title('K-Means Clustering')
plt.show()


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









