






 本文综述了三项16倍超分辨率技术,包括CIPLab提出的U-Net判别器与ESRGAN生成器改进;RFB-ESRGAN利用感受野模块提升特征提取能力;真实世界损失核估计技术,通过核估计和噪声注入提高真实场景下的超分效果。
本文综述了三项16倍超分辨率技术,包括CIPLab提出的U-Net判别器与ESRGAN生成器改进;RFB-ESRGAN利用感受野模块提升特征提取能力;真实世界损失核估计技术,通过核估计和噪声注入提高真实场景下的超分效果。
三篇竞赛相关,该竞赛针对的似乎是16倍超分,提供数据。
一.CIPLab
- 文章:Investigating Loss Functions for Extreme Super-Resolution
- 链接:https://openaccess.thecvf.com/content_CVPRW_2020/papers/w31/Jo_Investigating_Loss_Functions_for_Extreme_Super-Resolution_CVPRW_2020_paper.pdf
- 文章贡献:
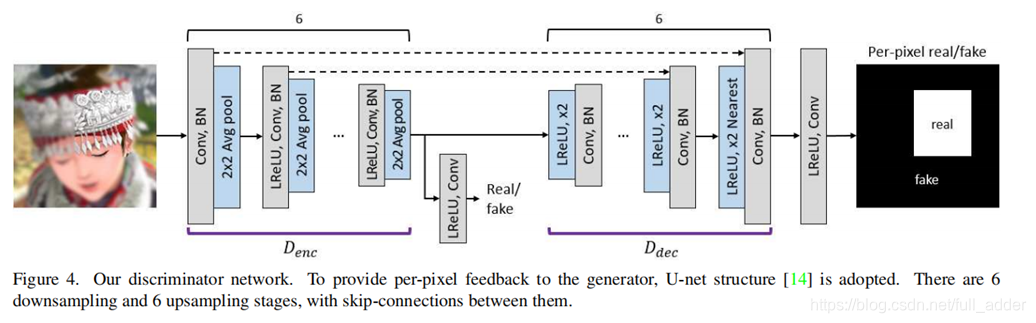
1.U-Net判别器,超分像素级指标
2.两次ESRGAN叠加的16倍超分生成器
3.LPIPS Loss直接用于训练 - 生成器网络结构
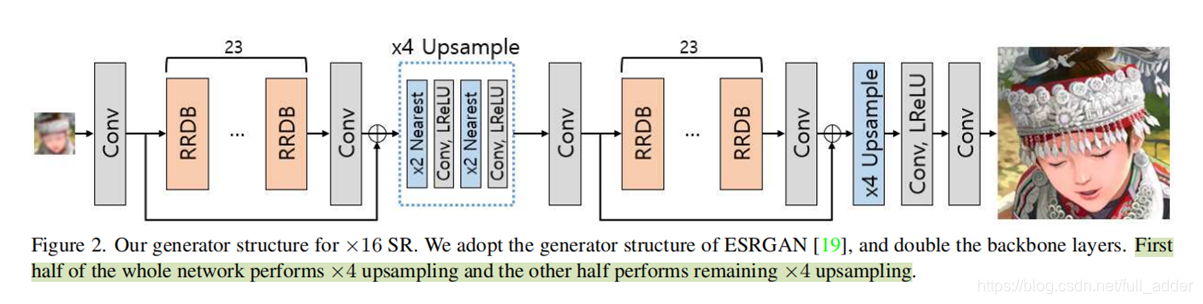
- 判别器网络结构
- Loss
1.生成器Loss
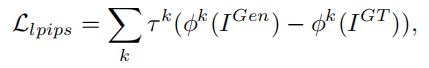
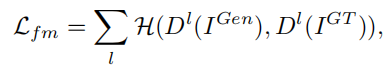

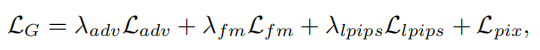
四部分,对抗,感知,判别器特征,L1
2.判别器Loss
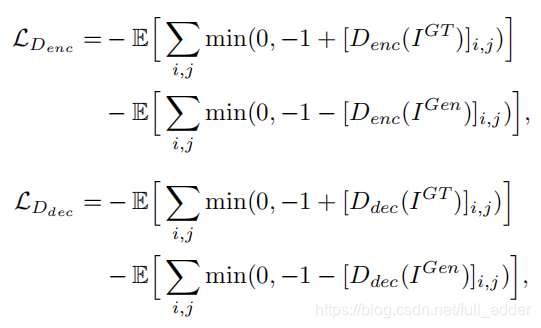
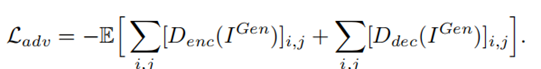
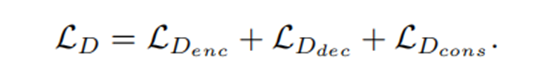
编码解码和对抗三部分
另外每个Loss不是在整个训练中都有效的,从代码看训练分为两部分,先前只有Pixel Loss【L1】,只训练了生成器。后续才开始共同训练
二. RFB-ESRGAN
- 文章:Perceptual Extreme Super Resolution Network with Receptive Field Block
- 链接:https://arxiv.org/abs/2005.12597
- 主要针对问题:不同图像的纹理细节差别非常大,单个图像的感知极端超分辨率非常困难
- 解决方法:感受野
- 文章贡献:
1.为了提取多尺度信息并增强特征的可识别性,将感受野(RFB)应用于超分辨率
2.在RFB中没有使用大卷积核,而不是在多尺度感受野中使用一些小核,能够提取详细的特征,降低计算复杂度
3.在上采样阶段交替使用不同的上采样方法,以降低高计算复杂度,并仍然保持令人满意的性能
4.使用10个不同迭代模型的集合来提高模型的鲁棒性,降低每个模型引入的噪声 - 网络结构:
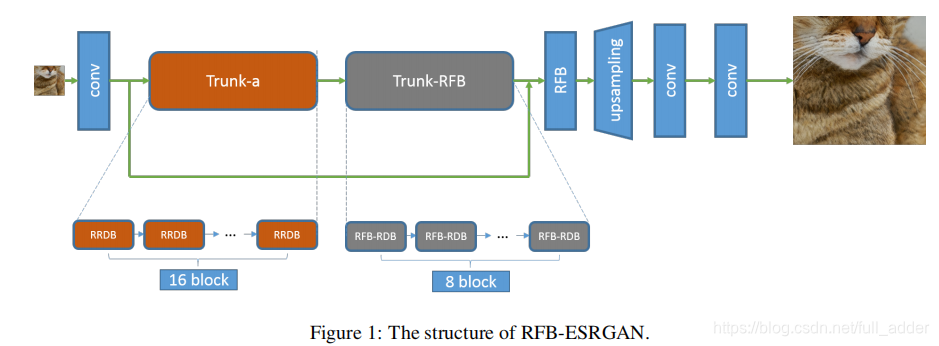
网络结构基于ESRGAN,分为五个部分:第一卷积模块,Trunk-a模块,Trunk-RFB模块,上采样模块与最终卷积模块。【奇怪的起名方式增加了.jpg】,具体结构如下:
第一卷积模块:3*3卷积
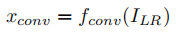
Trunk-a模块:16个RRDB模块[Residual Dense Block]
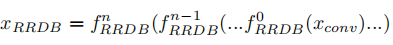
Trunk-RFB模块:8个RFB-RDB模块,即加了感受野的RRDB模块,其结构对比如下
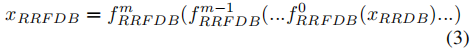
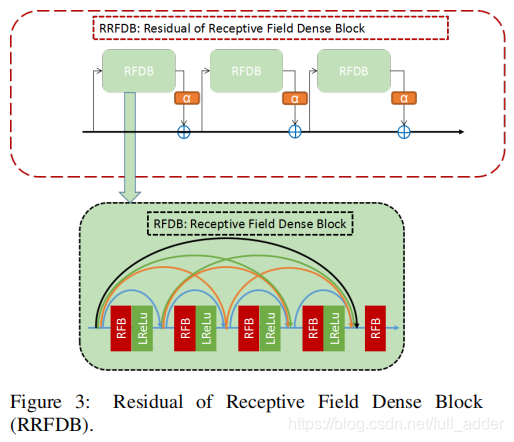
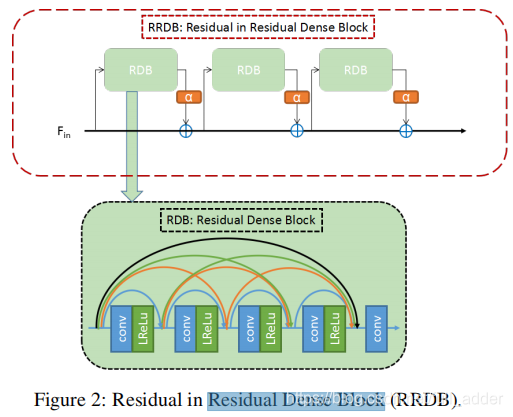
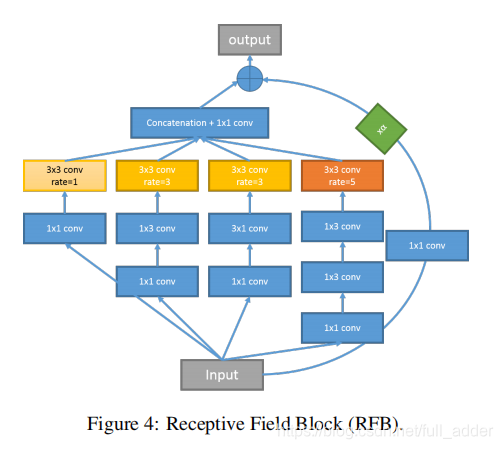
也就是把模块中的卷积层替换为RFB结构,该结构由不同尺寸的卷积滤波器构成,应当是来源于Googlenet,其具体结构如下:
上采样模块:RFB+最近邻插值与亚像素卷积,后两者交替进行
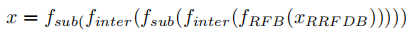
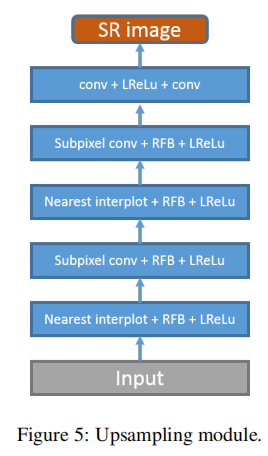
最终卷积模块:两层卷积,3*3
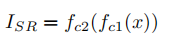
-
损失函数设计:
1.生成器损失函数:VGG Loss,对抗loss,L1 Loss
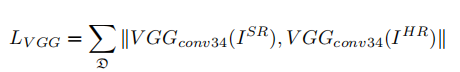
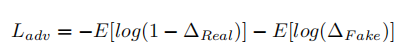
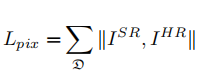
2.判别器损失函数:Real Loss, Fake Loss
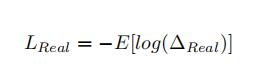
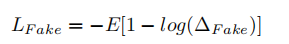
-
集成方法
10个感知最好的GAN网络
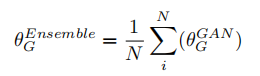
-
结果

三.真实世界损失核估计
-
文章:Real-World Super-Resolution via Kernel Estimation and Noise Injection
-
链接:https://openaccess.thecvf.com/content_CVPRW_2020/papers/w31/Ji_Real-World_Super-Resolution_via_Kernel_Estimation_and_Noise_Injection_CVPRW_2020_paper.pdf
-
主要针对问题:固定下采样核难以应对真实世界情况
-
解决方法:估它!

-
贡献
1.提出一种新的基于真实环境下的下采样框架
2.通过探索不同的核与噪声,研究了模糊和噪声对图像造成的具体变化
3.证明了该方法在RealSR上的先进 -
网络结构
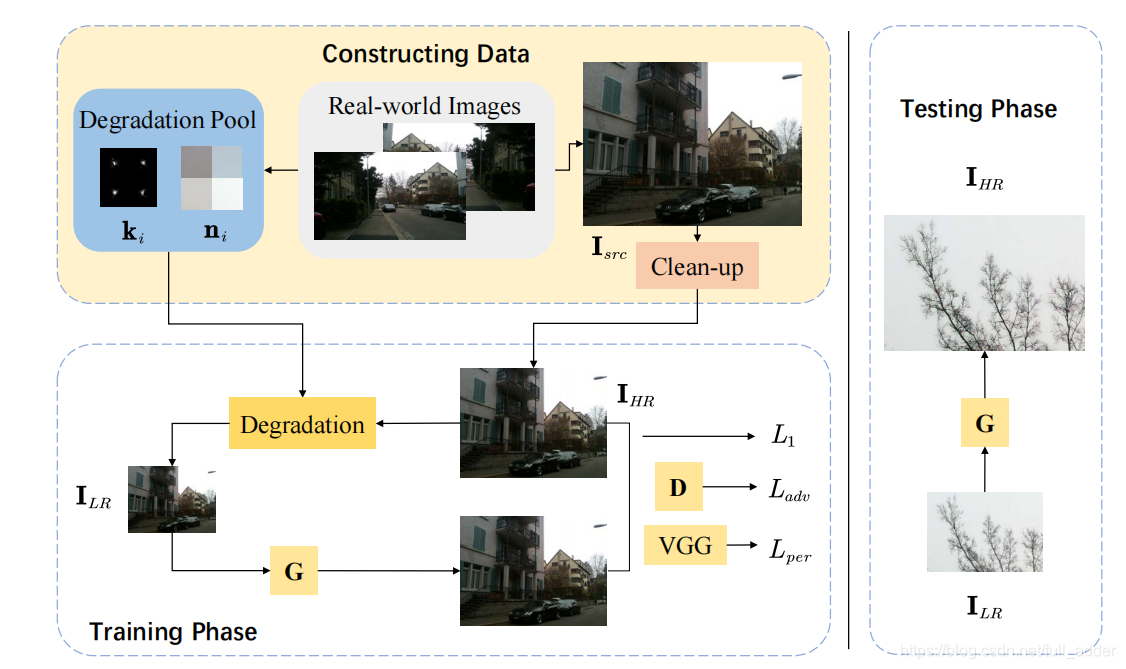
两部分,先生成真实的低分辨率图像集,再训练超分网络 -
真实下采样图像的生成
本文方法基于核估计与噪声注入,其假定真实世界下采样过程方程为
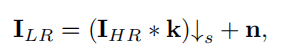
k,n分别代表核与噪声。是故核心思想就是估计k和生成n,本文算法的具体流程如下:

用于估计核的方程4如下:
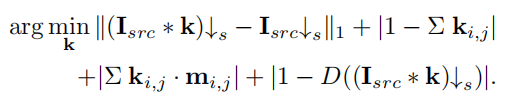
也就是对LR图像进行进一步下采样处理。第一项最小化估计核与传统核的下采样结果的区别,鼓励保留低频信息。第二项正则化,约束核参数的和为1。第三项约束k的边界,使其不会过大,第四项引入鉴别网络,确保其真实性。
用于解噪声的方程7如下,为LR图像加噪声的核心思想为收集HR图像的噪声。下方程即为收集的规则,将噪声范围进行了限制。
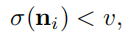
噪声注入过程是通过从噪声池中随机裁剪斑块来进行:
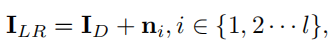
-
损失函数:L1,感知,对抗
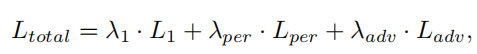
-
结果

参考
【1】https://zhuanlan.zhihu.com/p/149322505

















 987
987

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









