



Agent RL 智能体强化学习 实战
通过 Agent RL(智能体强化学习) ,我们可以让智能体在环境中自动学习最优策略,从而实现自动优化。
本文从实战角度出发,通过 Agent-Lightning 框架对 SQL-Agent (也适用于其他Agent)进行强化学习,提升其在自然语言到 SQL 转换任务中的准确率。(附源码)
项目架构梳理
在进行 Agent RL (基于 veRL + Agent-Lightning) 强化学习实战之前,我们先来梳理项目的整体架构和运行逻辑。
架构设计
整个系统采用了 运行与训练分离 的设计思想,也就是将 Agent 的实际执行逻辑(即如何生成、执行与修正 SQL 语句)与强化学习训练过程(即如何计算奖励、更新模型参数)进行解耦。从而实现 可扩展、可维护 的训练流程。
具体而言,系统分为两大 核心模块 :
- 运行模块(Agent 运行脚本):
该部分由 SQL-Agent 负责,实现从自然语言问题到 SQL 执行结果的完整推理流程。此模块重点在于让 Agent 具备可观测、可追踪的行为,从而为后续强化学习提供高质量的数据轨迹。 - 训练模块(Agent 训练脚本):
这一部分主要依托 Agent-Lightning 框架与 veRL (Volcengine Reinforcement Learning) 训练系统完成。其作用是利用运行模块产生的行为轨迹,对底层基座模型进行基于 GRPO (Group Relative Policy Optimization) 算法的优化,从而实现策略提升与能力迁移。
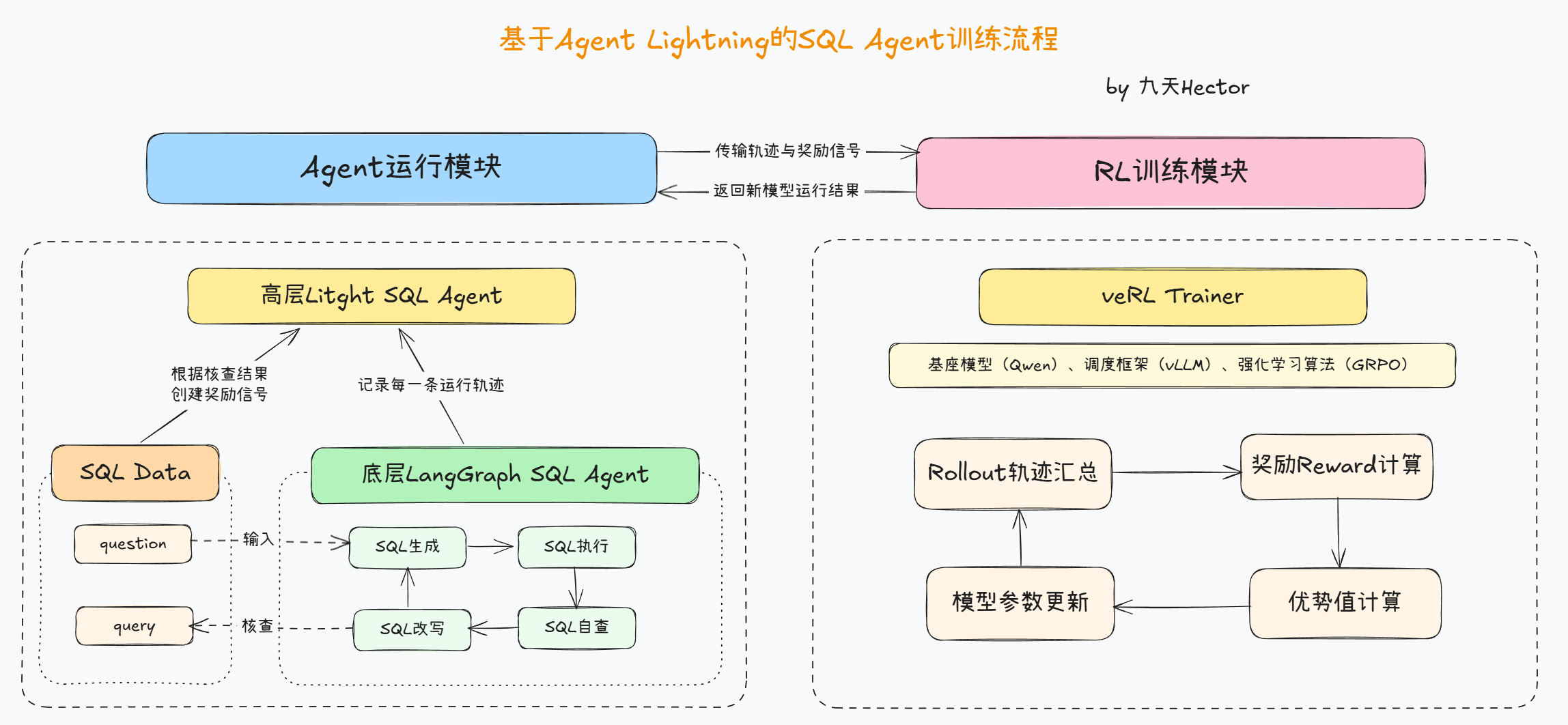
其中 运行模块 专注于生成和记录,训练模块 专注于分析与更新,两者之间通过轨迹数据(trajectory)和奖励信号(reward signal)进行衔接。
换言之,运行脚本产出数据,训练脚本消费数据。
运行模块:SQL Agent 的设计逻辑
这部分我们使用 LangGraph 实现 SQL Agent 的运行逻辑。
在 SQL Agent 中,LangGraph 的节点主要包括:
- write_query(生成 SQL 语句):模型根据输入的问题及数据库模式(schema)生成初步 SQL 查询;
- execute_query(执行 SQL):调用 SQL 执行工具 (QuerySQLDatabaseTool) 在数据库上运行查询;
- check_query(判断 SQL 正确性):模型根据执行结果判断 SQL 是否合理;
- rewrite_query(重写 SQL):若上一步判断为错误,则重新生成更合理的 SQL;
- END(结束节点):当 Agent 确认 SQL 无误时,停止流程。
LangGraph 天然支持 状态持久化与轨迹记录。
每一次执行、判断与重写都会被记录为一条“状态-动作-反馈”数据,这正是强化学习算法所需要的经验数据(Experience Trajectory)。
训练模块:基于 veRL 的 GRPO 强化学习逻辑
训练模块是整个系统的优化核心,其主要任务是根据 Agent 执行产生的轨迹与奖励,更新底层语言模型参数,使其行为策略(policy)趋向于生成更优的 SQL 语句。
veRL (Volcengine Reinforcement Learning) 是由 字节跳动 开源的强化学习训练框架,支持多种算法,包括 PPO、DPO、GRPO 等。其中 GRPO(Group Relative Policy Optimization) ,能够在无需 critic 网络的情况下实现高效的策略更新,特别适合大语言模型(LLM)的 RL 训练。
在本项目中, train 脚本主要通过 veRL 调用 GRPO 算法来实现训练,其底层逻辑如下:
- Rollout 阶段:
训练器(Trainer) 会调度多个并行进程,每个进程加载一个 LangGraph Agent 实例,并分配不同的训练样本(自然语言问题)。每个 Agent 根据当前模型策略生成 SQL 、执行、反馈,形成 rollout 轨迹。 - Reward 计算:
训练器调用 evaluate_query 对每个 Agent 的输出进行评分。若执行结果正确,则给出正向奖励,否则为 0。所有样本的 reward 值将与模型生成的 log prob 概率一同送入 GRPO 优化器。 - Advantage 估计与策略更新:
GRPO 算法根据组内样本的相对表现计算 advantage(优势函数),不依赖额外 critic 网络。表现较优的样本获得更大权重,劣质样本权重降低,从而实现“优胜劣汰”的参数更新。 - 参数同步与保存:
训练器更新模型参数后,会定期保存检查点(checkpoint),供下一轮 rollout 使用。新参数会替换旧参数,使下一轮 Agent 行为更优。
整个过程形成一个典型的 on-policy 强化学习闭环:执行 → 反馈 → 优化 → 再执行,每个循环都会让 Agent 的策略更趋近理想状态。
训练模块:Agent-Lightning 的封装逻辑
我们通过 Agent-Lightning 框架在运行脚本上进行封装 ,使得 SQL Agent 具备了强化学习所需的接口与记录能力。这种封装的主要目的有三点:
-
轨迹采集(Trajectory Collection):
Agent-Lightning 在每次 Agent 执行过程中自动记录输入问题、生成的 SQL、执行结果、反馈内容及执行日志。这些轨迹数据被打包成 rollout 样本,供后续 RL 算法使用。 -
奖励信号传递(Reward Propagation):
运行脚本在每次 Agent 完成一个任务后,会调用 evaluate_query 函数对结果进行评分。若生成的 SQL 与标准答案一致(或执行结果正确),则 reward = 1;否则 reward = 0。这一奖励信号是 GRPO 算法计算梯度的重要依据。 -
可扩展接口(Training Interface):
Agent-Lightning 在运行层面提供了标准化接口,使得训练模块可以直接通过 rollout 调用 Agent 执行。例如,在 train 脚本中可以统一调用 agent.rollout(task, resources, rollout) 而不必关心 Agent 内部结构。这种解耦式设计使整个系统具有极强的可扩展性,可以轻松替换 Agent 或模型。
Agent-Lightning 的封装 相当于为 Agent 加上了一个 可观测接口,把原本封闭的推理过程开放为可追踪的训练数据流。

Agent运行 与 强化学习训练 的闭环逻辑
理解完运行与训练模块后,我们可以从系统层面总结其运行逻辑。整个强化学习微调流程可以用以下闭环描述:
- SQL Agent 根据输入问题生成 SQL;
- 执行 SQL 并获取执行结果;
- Agent-Lightning 封装记录轨迹并计算奖励;
- veRL 收集轨迹与奖励,使用 GRPO 算法更新模型策略;
- 更新后的模型重新投入下一轮 rollout 执行。
在此循环中,每一轮 Agent 的 SQL 生成能力都会得到提升。初期 Agent 可能频繁生成错误 SQL,经过数轮优化后,模型逐渐学会识别正确的字段、表结构和查询模式,生成更符合语义的 SQL 语句。这就是 Agentic RL 的强大之处—— 通过实际执行结果指导模型学习,使其具备真实世界任务的自适应能力。
该架构 并不局限于 SQL 任务。只要 定义了 Agent 的执行流程, Agent-Lightning 提供了 rollout 封装, veRL 即可用于强化学习训练。
基于 Agent-Lightning 的 SQL Agent 强化学习训练实战
1. 基础环境配置与相关库安装
-
实验环境说明:本实验在Ubuntu 22.04、H800(80G)显卡服务器上运行,推荐使用CUDA 12.8,完整运行需要12个小时,如采用LoRA微调,则可以压缩至2小时完成。
-
创建基础虚拟环境
conda create --name al python=3.12
conda init
conda activate al
# conda install jupyterlab
# conda install ipykernel
# python -m ipykernel install --user --name al --display-name "Python al"
- 安装Agent Lightning库
pip install --upgrade agentlightning

- 安装SQL-Agent强化学习训练基础库
# 注意需要安装openai 2.0以上版本,可以通过pip show openai进行版本查看
pip install openai
pip install agentlightning[apo]
# 注意需要CUDA 12.8版本
pip install torch==2.8.0 torchvision==0.23.0 --index-url https://mirrors.huaweicloud.com/repository/pypi/simple
pip install flash-attn --no-build-isolation
pip install vllm==0.10.2 --index-url https://mirrors.huaweicloud.com/repository/pypi/simple
pip install verl==0.5.0 --index-url https://mirrors.huaweicloud.com/repository/pypi/simple
# 手动完成verl安装后可以输入如下命令进行验证
# pip install agentlightning[verl]

- 安装SQL Agent基础库
pip install "langgraph<1.0" "langchain[openai]<1.0" "langchain-community" "langchain-text-splitters<1.0" "sqlparse" "nltk" --index-url https://mirrors.huaweicloud.com/repository/pypi/simple
- Qwen 2.5 coder模型下载:https://www.modelscope.cn/models/Qwen/Qwen2.5-Coder-1.5B-Instruct
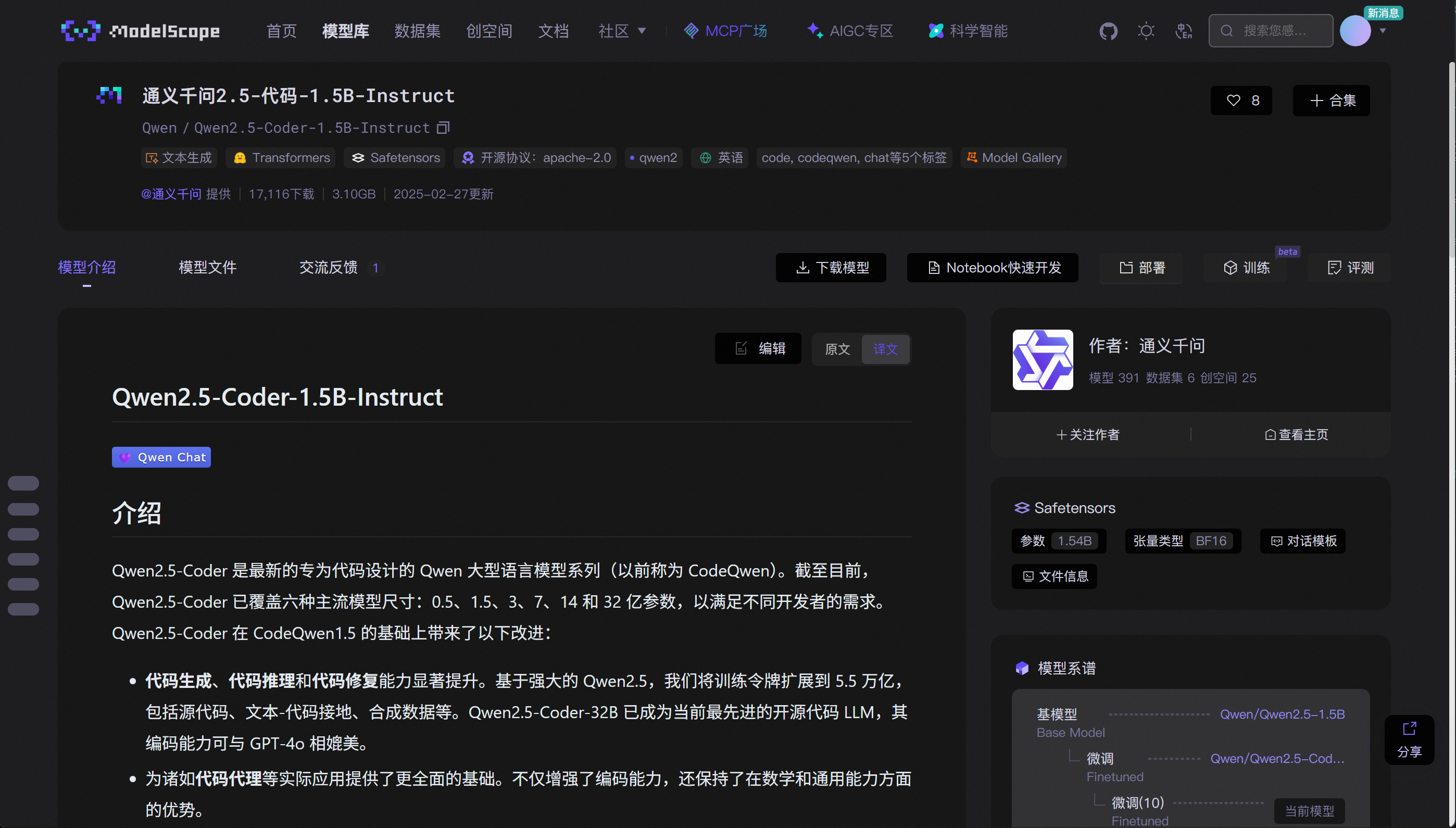
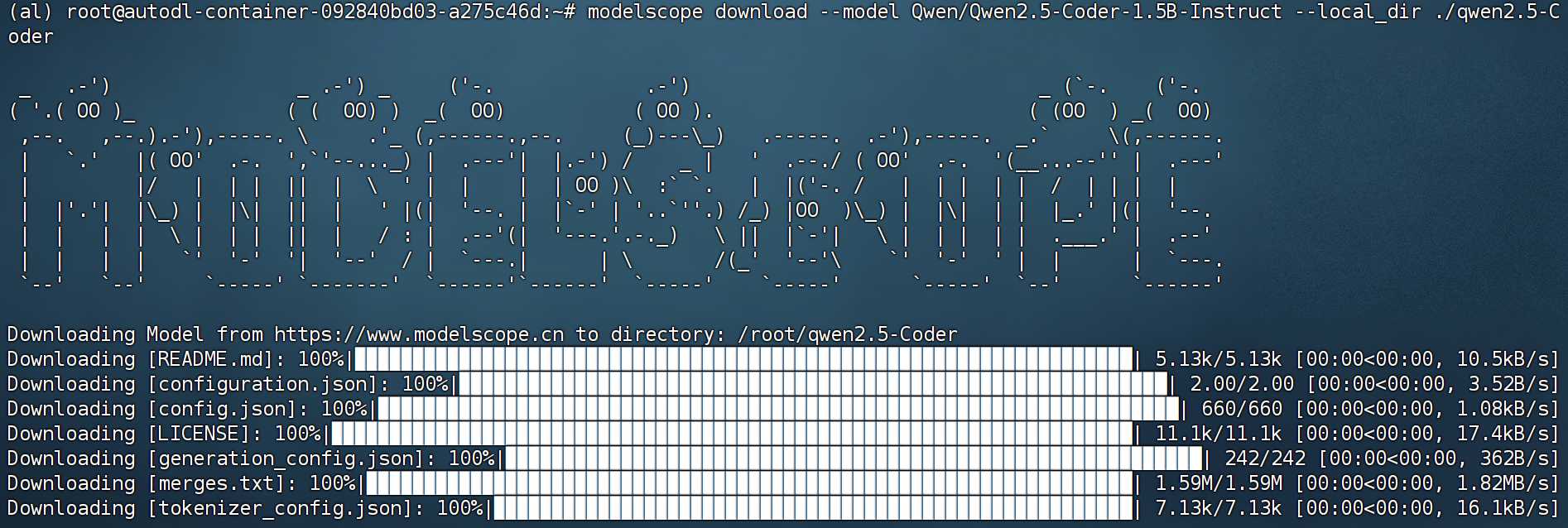
pip install modelscope
# cd /root/autodl-tmp
mkdir ./qwen2.5-Coder
modelscope download --model Qwen/Qwen2.5-Coder-1.5B-Instruct --local_dir ./qwen2.5-Coder
- SQL数据集准备
Spider 数据集是一个大规模跨域文本到SQL数据集,专门用于训练和评估自然语言到SQL查询的转换能力。这个数据集来自耶鲁大学的研究项目,可以从 Yale LILY Spider 官方网站获取.

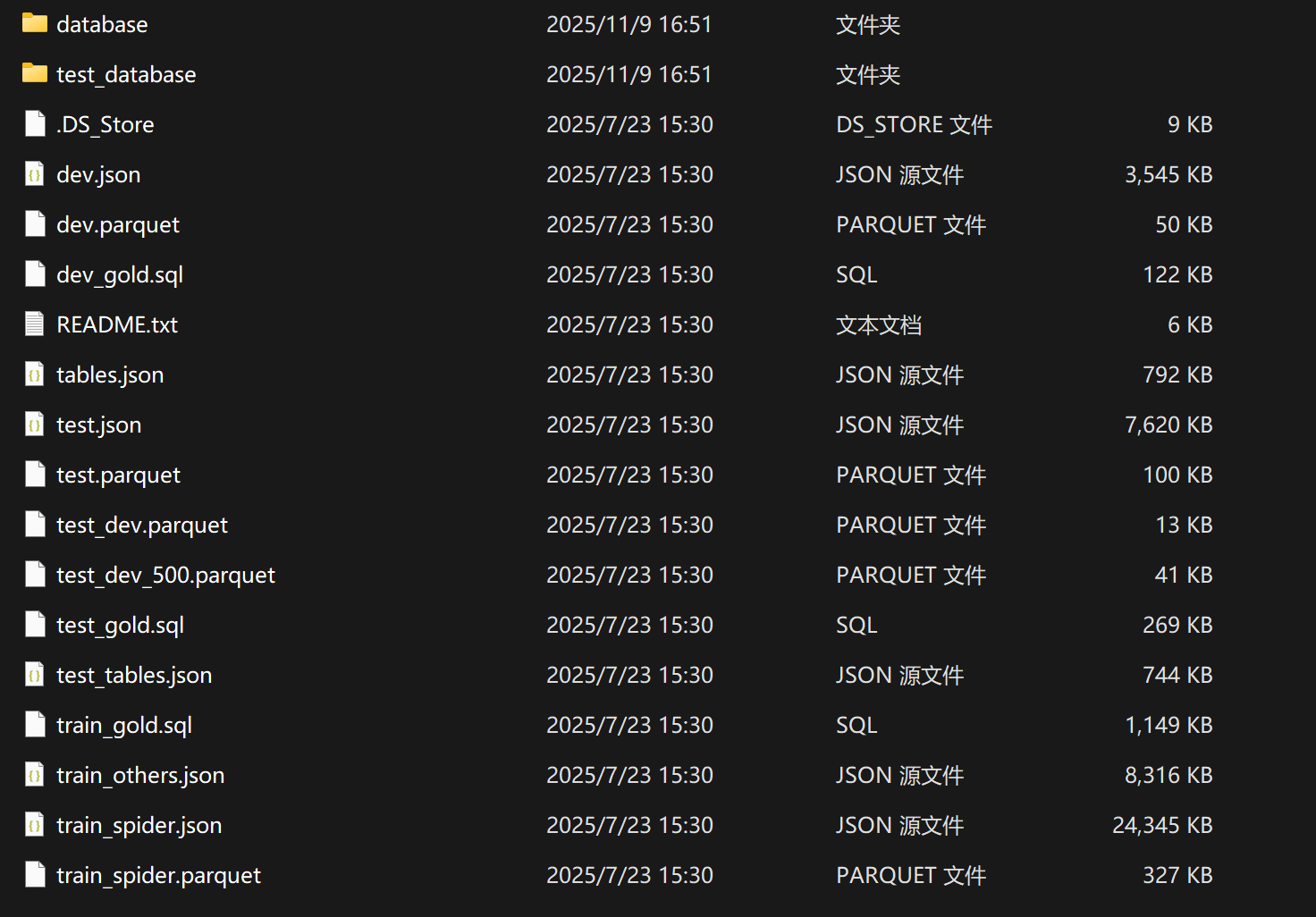
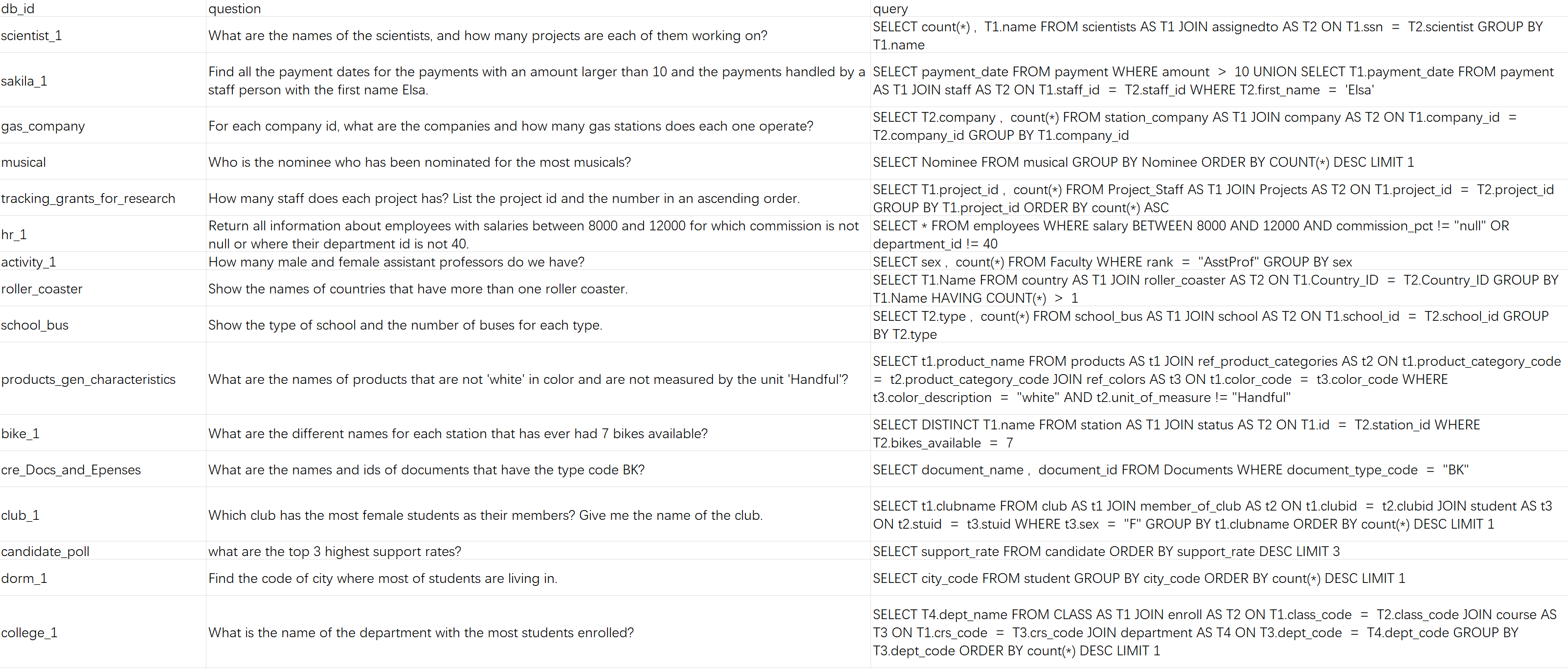
其中本项目核心要用到的是三个 Parquet 文件:
train_spider.parquet: 训练数据集,包含约 8,000 个样本test_dev_500.parquet: 验证数据集的子集,包含 500 个样本test_dev.parquet: 完整的开发/测试数据集
每个 Parquet 文件包含以下字段:
question: 自然语言问题(例如:“Show all concert names and their singers”)db_id: 数据库标识符(例如:“concert_singer”)query: 标准答案 SQL 查询(ground truth)db_path: 数据库文件的相对路径
数据集领取: 加 小助理 免费领取
总的来说,数据集包含约 200 个不同的 SQLite 数据库,每个数据库代表一个特定的业务场景。我们需要这些数据库文件存储在 data/database/ 目录下,按照数据库名称组织。例如:
data/database/concert_singer/concert_singer.db- 音乐会和歌手数据库data/database/college_2/college_2.db- 大学信息数据库data/database/flight_2/flight_2.db- 航班信息数据库
每个数据库都是一个完整的 SQLite 文件,包含多个表和真实的业务数据。需要注意的是,
- Spider 数据集是跨域的,意味着它包含多个不同业务领域的数据库,这使得训练出的模型具有更好的泛化能力
- 数据集中的每个问题都有唯一的标准答案 SQL 查询,但可能存在多种等价的 SQL 写法都能得到相同的结果
- SQLite 数据库的使用使得整个系统零配置,不需要安装和配置独立的数据库服务器
- 在 CI 测试中,数据集的准备是自动化的,确保了测试环境的一致性
查看数据集:
# 如果要运行如下代码,建议单独创建环境,以免部分库如numpy版本和agent lightning冲突
pip install -U "pandas==2.2.2" "pyarrow==17.0.0" "fastparquet==2024.5.0" "numpy==1.26.4"
然后在Jupyter中运行如下代码,即可查看数据集基本情况:
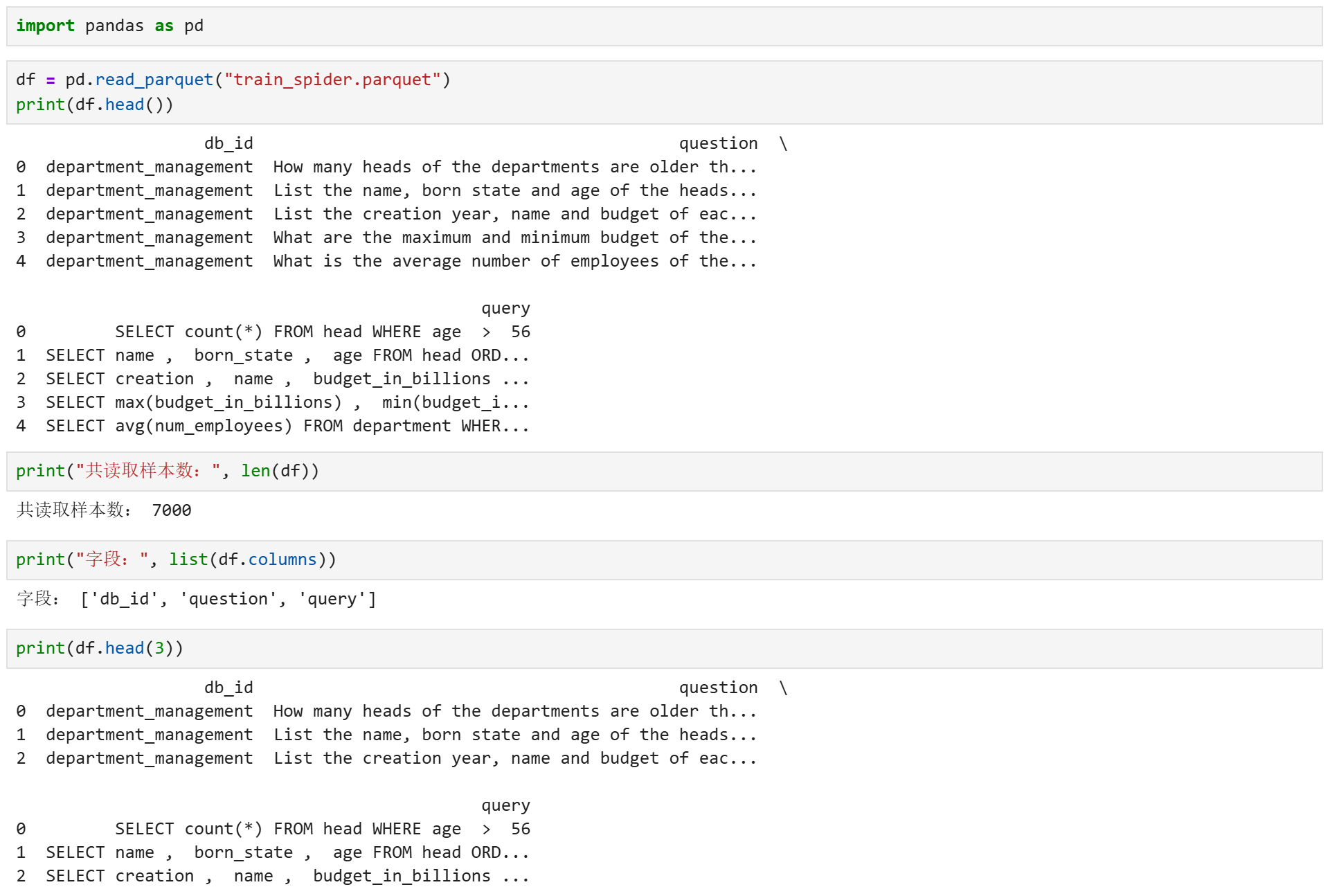
import pandas as pd
df = pd.read_parquet("train_spider.parquet")
print("共读取样本数:", len(df))
print("字段:", list(df.columns))
print(df.head(3))
- wandb安装流程
在大规模模型训练中,我们往往需要监控和分析大量的训练数据,而WandB可以帮助我们实现这一目标。它提供了以下几个重要的功能:
实时可视化:WandB可以实时展示训练过程中关键指标的变化,如损失函数、学习率、训练时间等。通过这些可视化数据,我们能够直观地了解模型的训练进展,快速发现训练中的异常或瓶颈。
自动记录与日志管理:WandB会自动记录每次实验的参数、代码、输出结果,确保实验结果的可追溯性。无论是超参数的设置,还是模型的架构调整,WandB都能够帮助我们完整保留实验记录,方便后期对比与调优。
支持中断与恢复训练:在长时间的预训练任务中,系统中断或需要暂停是常见的情况。通过WandB的checkpoint功能,我们可以随时恢复训练,从上次中断的地方继续进行,避免数据和时间的浪费。
多实验对比:当我们尝试不同的模型配置或超参数时,WandB允许我们在多个实验之间轻松进行对比分析,帮助我们选择最优的模型配置。
团队协作:WandB还支持团队协作,多个成员可以共同查看实验结果,协同调试模型。这对研究和项目开发中团队的合作非常有帮助。
wandb官网:https://wandb.ai/site
然后即可在令行中输入如下代码安装wandb:
pip install wandb
接下来在unsloth微调前,我们即可设置wandb进行微调记录,并可在对应网站上观察到训练过程如下:
2.项目创建与运行流程
首先创建基本项目结构如下:
SQL-Agent-RL/
├── data/ # 存放数据集
├── model/ # 存放下载的模型权重
└── spider/ # 存放核心脚本
data/主要放置 Spider 数据集相关文件,包括:
train_spider.parquet
test_dev_500.parquet
test_dev.parquet
database/ # 每个数据库一个子目录,内含 .sqlite 和 schema.sql
数据集领取:加 小助理 免费领取

确保路径与脚本中保持一致,比如在 train_sql_agent.py 中的配置:
"train_files": "data/train_spider.parquet",
"val_files": "data/test_dev_500.parquet",
以及 SQLAgent 调用时会读取:
original_db_path = os.path.join(self.spider_dir, "database", task["db_id"], task["db_id"] + ".sqlite")
所以 data/database/... 子目录必须存在,否则训练时会提示数据库路径错误。
model/则是本地下载的模型权重(Qwen2.5-Coder)。 推荐结构如下:
model/
└── Qwen2.5-Coder-1.5B-Instruct/
├── config.json
├── tokenizer.json
├── model.safetensors
└── ...
然后在训练脚本 train_sql_agent.py 中,把配置改为本地路径:
"actor_rollout_ref": {
"model": {
"path": "/root/SQL-Agent-RL/model/Qwen2.5-Coder-1.5B-Instruct",
},
}
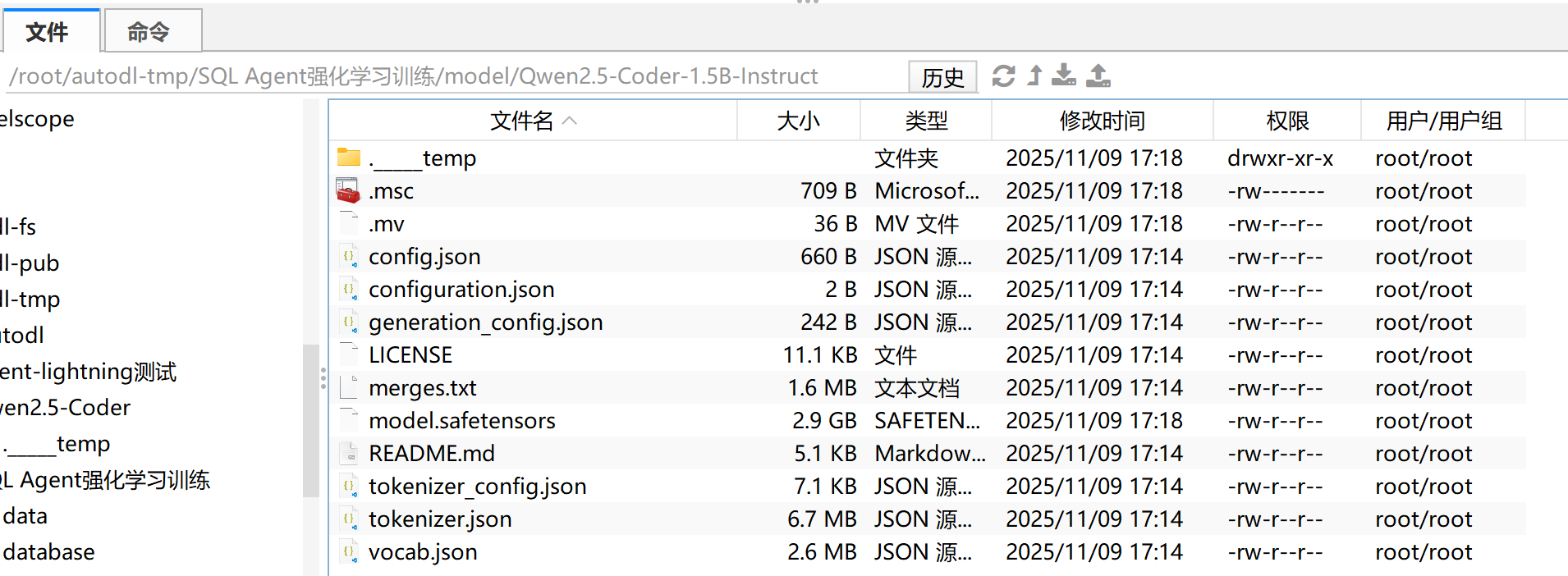
这样就不会再联网从 Hugging Face 下载了。

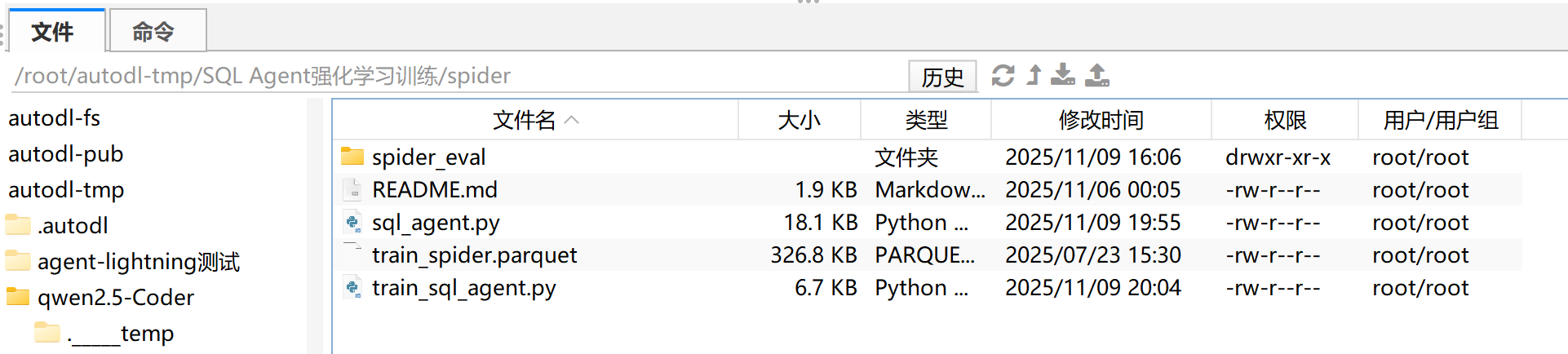
然后 spider/则用于存放项目核心代码脚本
spider/
├── sql_agent.py # 运行模块: SQL Agent
├── train_sql_agent.py # 训练模块:veRL + Agent-Lightning
├── spider_eval/ # 官方提供的 SQL 评估函数
│ └── exec_eval.py
│ └── 其他各项py文件
└── __init__.py
Agent RL 实战源码 加入 赋范空间 免费领取
3. SQL Agent运行与调用流程
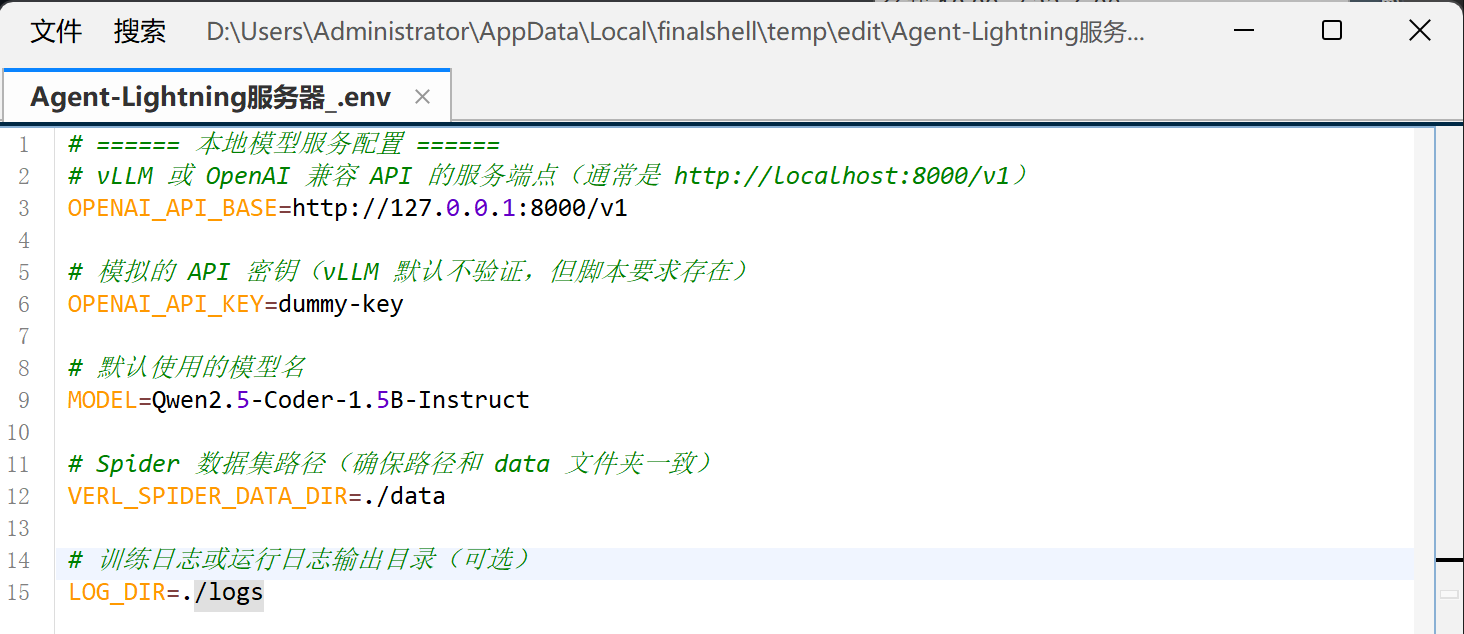
- 创建.env文件
- 启动vLLM服务
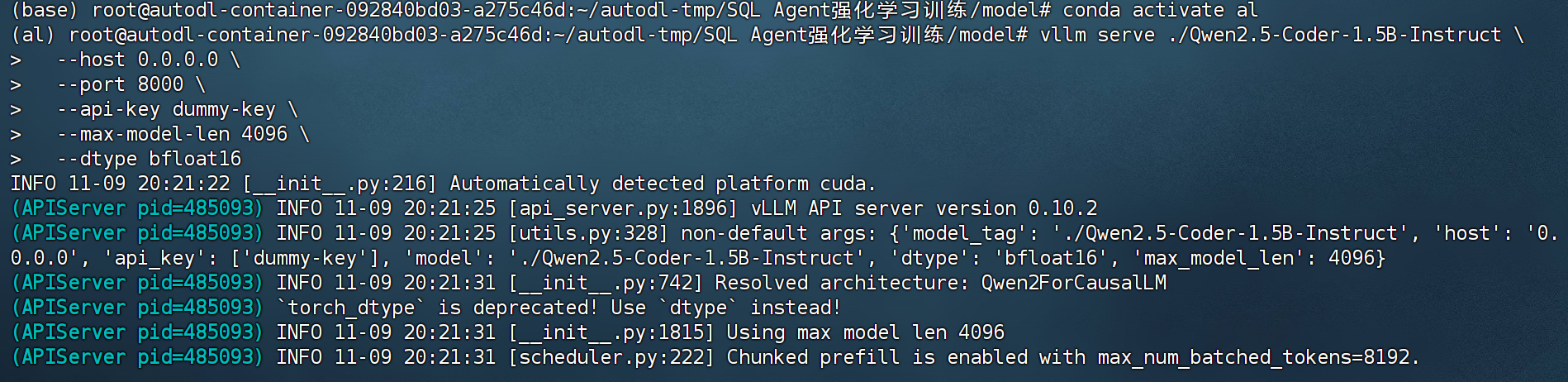
cd "/root/autodl-tmp/SQL Agent强化学习训练/model"
vllm serve ./Qwen2.5-Coder-1.5B-Instruct \
--host 0.0.0.0 \
--port 8000 \
--max-model-len 4096 \
--dtype bfloat16
- 运行SQL Agent
cd root/autodl-tmp/SQL Agent强化学习训练/spider
# export $(grep -v '^#' .env | xargs)
python sql_agent.py
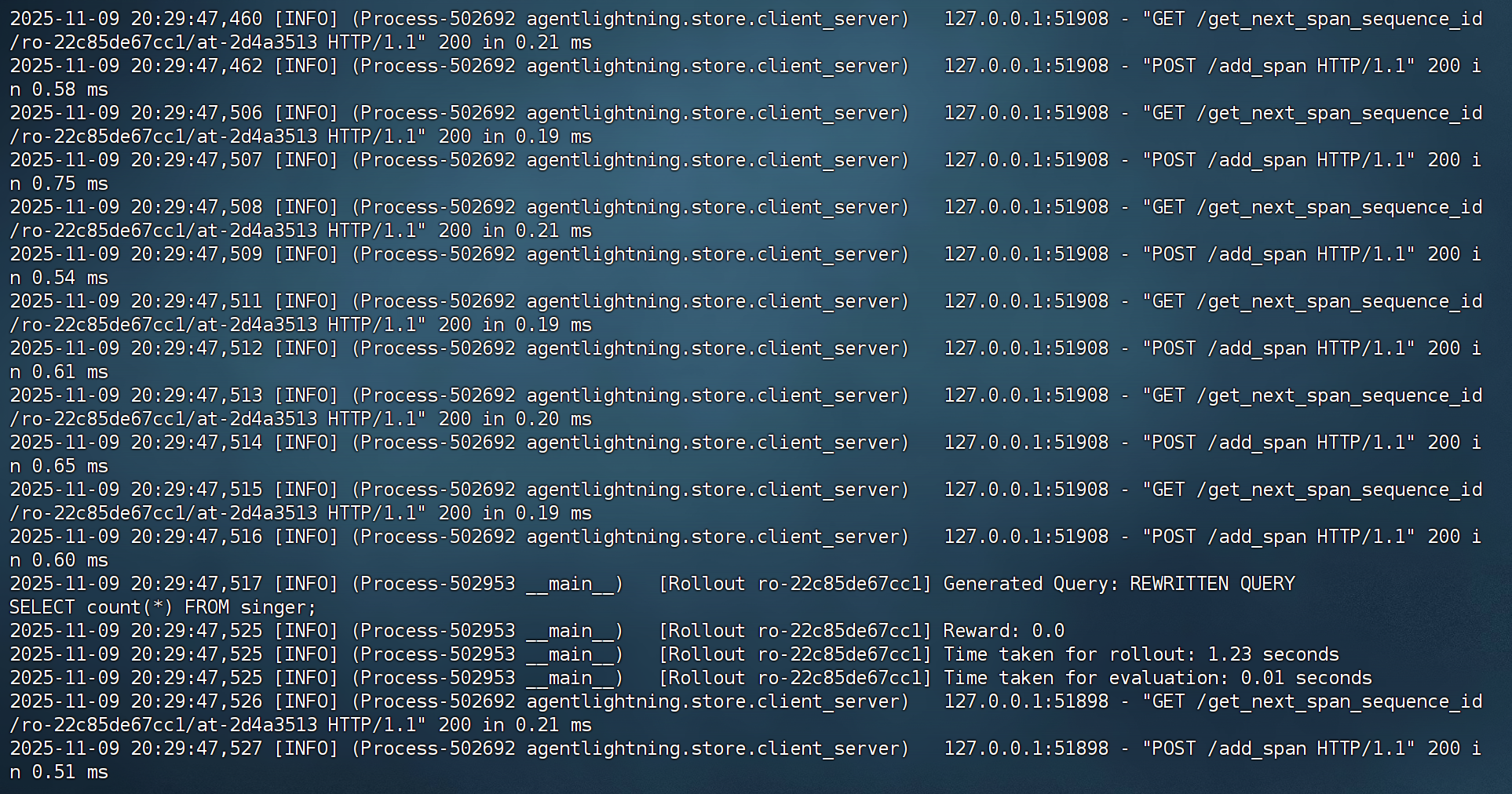
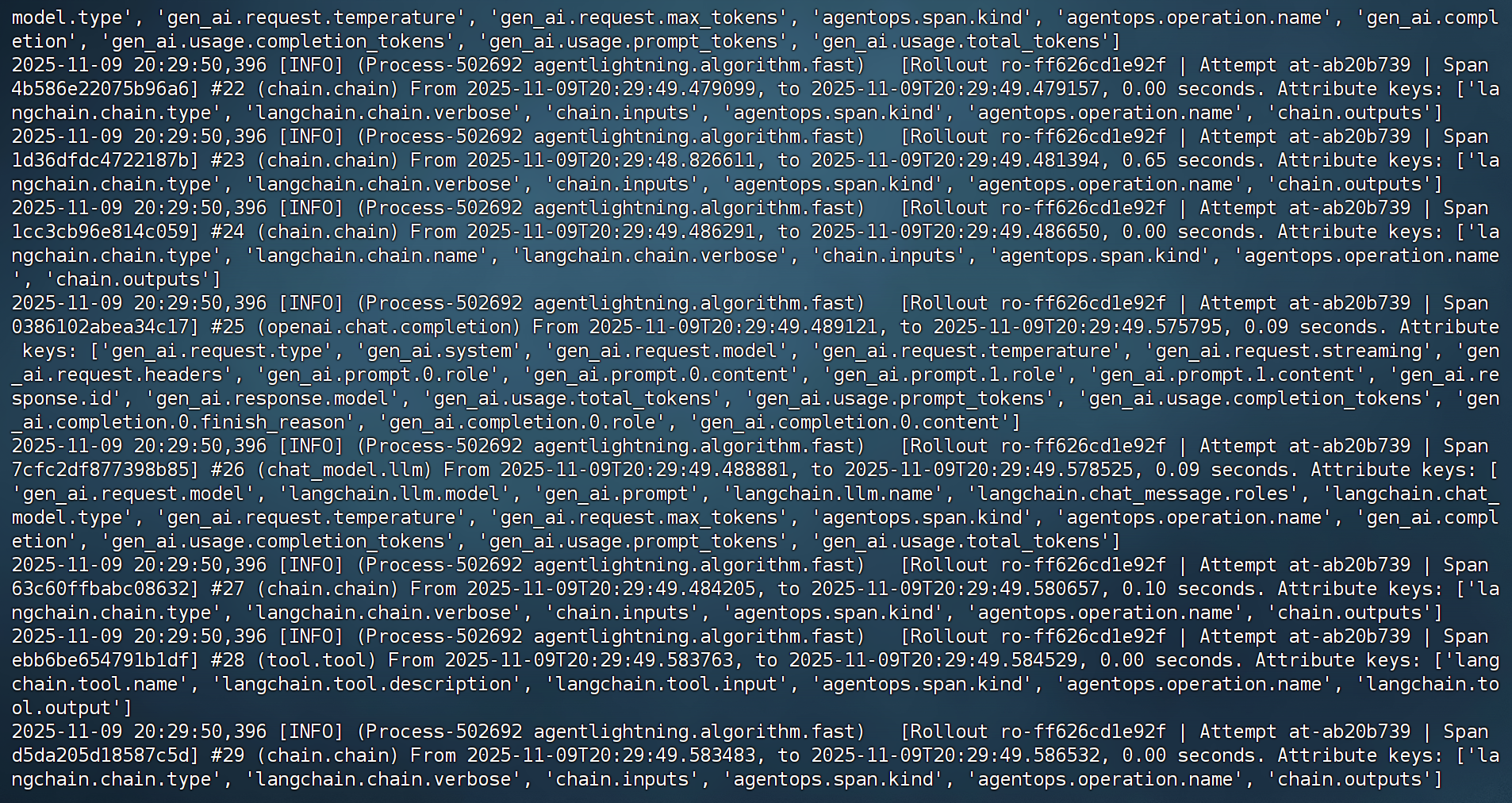
而运行如下代码则会开始进行训练:
python train_sql_agent.py qwen
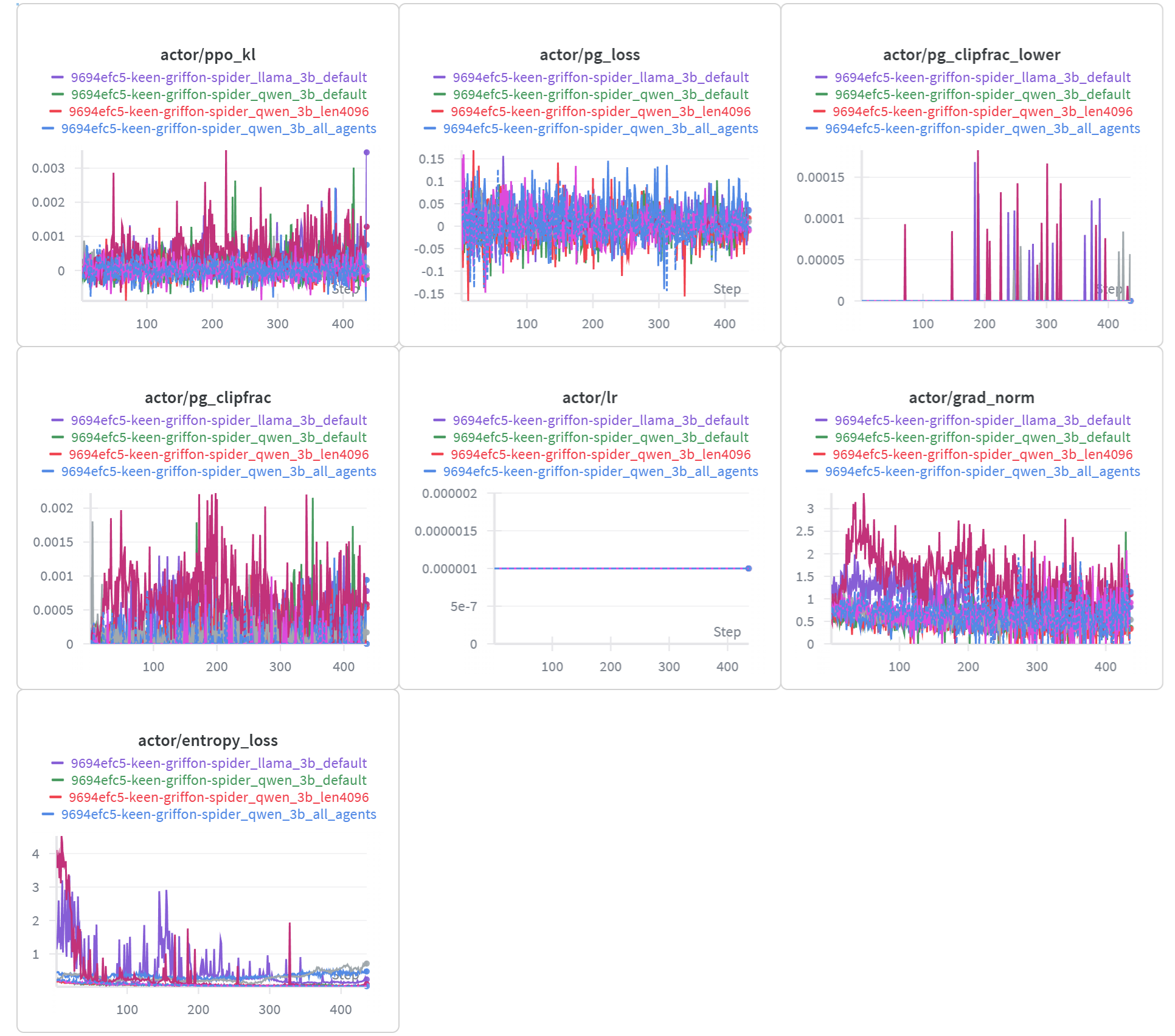
实际运行效果如下所示:

- 最终运行指标:
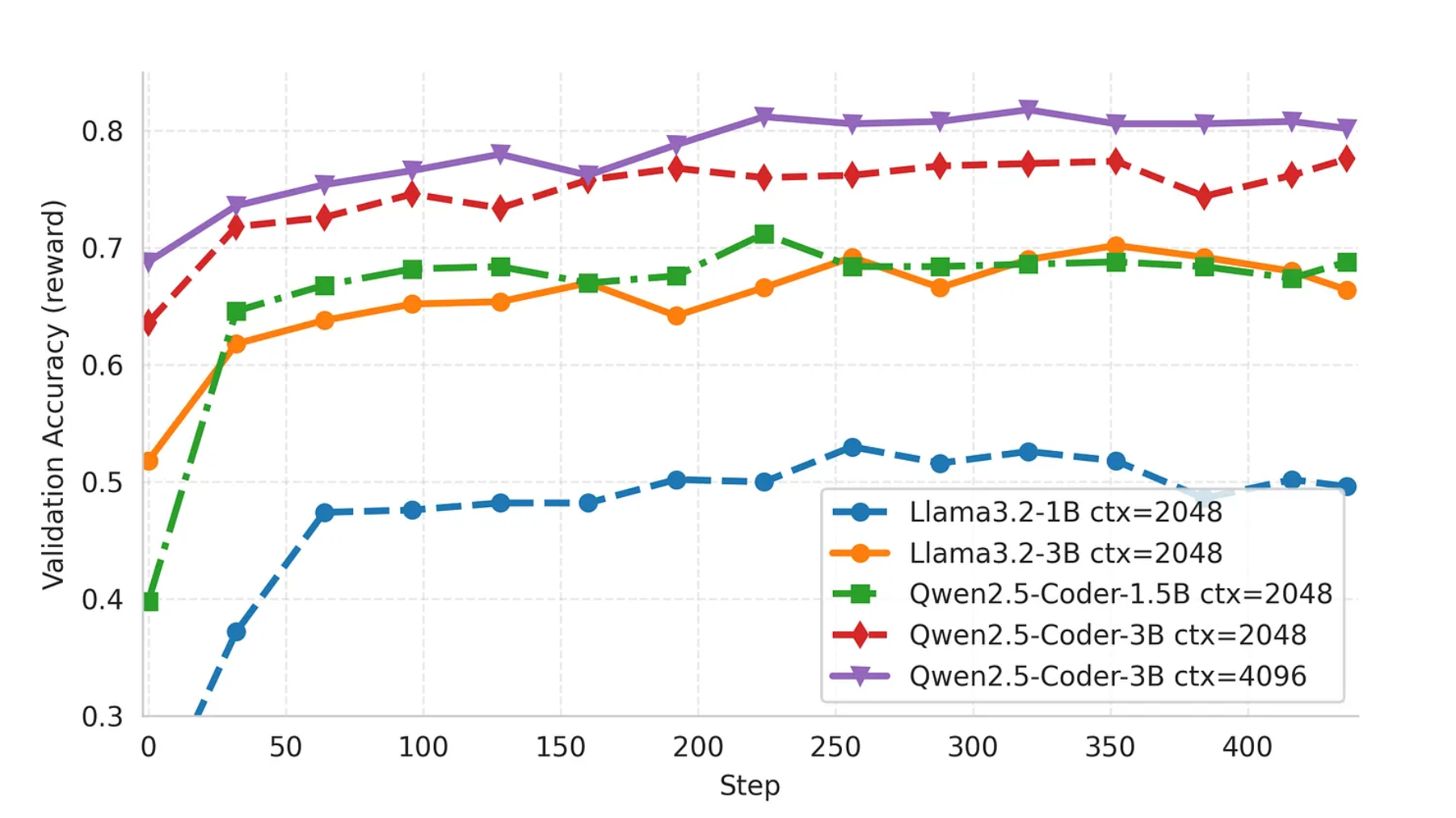
4. 强化学习微调效果说明
最后我们对 SQL-Agent 强化学习微调的实验结果进行系统性总结与分析。
本次实验以 Qwen2.5-Coder 系列模型为核心,通过 Agent-Lightning 框架配合 veRL 的 GRPO 强化学习算法,对基于 LangGraph 构建的 SQL-Agent 进行了全流程的 Agentic RL 训练与评估。以下结论基于多组训练实验的真实数据统计与性能表现。
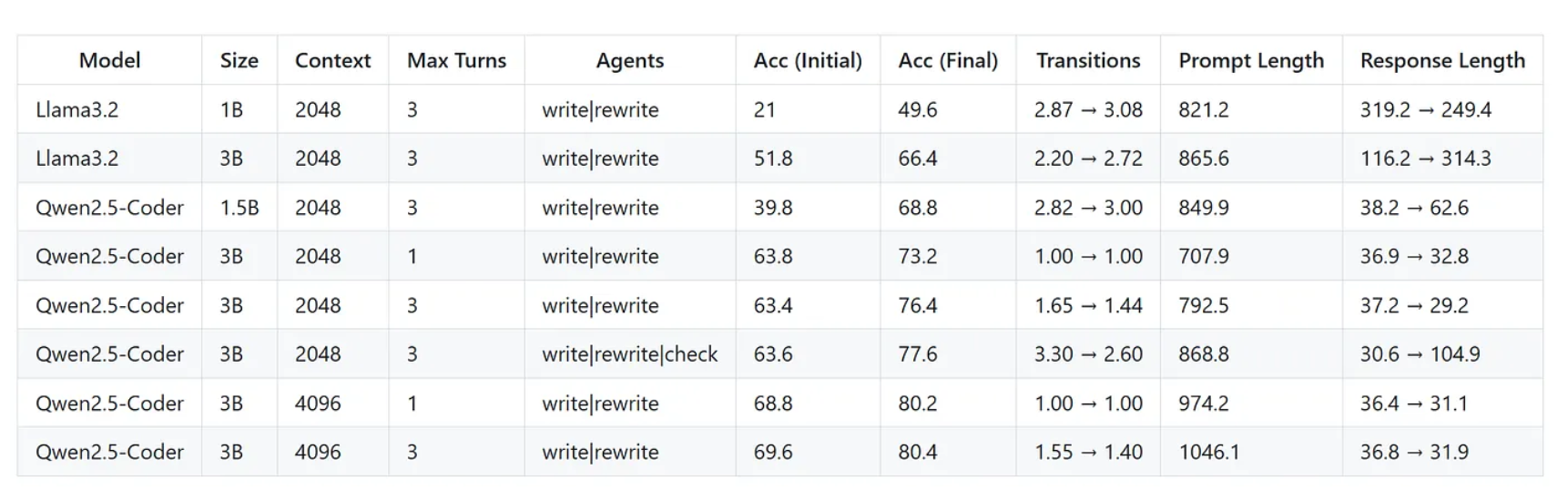
4.1 强化学习显著提升模型性能
实验结果表明,经过 RL 训练后,所有模型的 SQL 生成准确率均较初始状态显著提升。尤其在 Qwen2.5-Coder-3B 模型上,经过 GRPO 训练后,在三轮推理交互(Three Turns)设置下,最终准确率达到 80.4%;即便在单轮推理(One Turn)下,也能保持 80.2% 的高准确率。这充分说明了强化学习能够有效提升 Agent 的策略能力,使模型不仅“生成得出答案”,更“生成得更正确”
4.2 上下文长度对性能的直接影响
实验对比发现,上下文长度(context length) 的提升对模型性能具有明显正向作用。以 Qwen2.5-Coder-3B 为例,当上下文从 2048 tokens 扩展至 4096 tokens 时,三轮推理下的最终准确率由 76.4% 提升至 80.4%,单轮推理下的准确率则从 73.2% 提升至 80.2%。这一变化反映出更长的上下文窗口能够帮助模型在多轮 SQL 生成与反馈中更好地保持逻辑一致性,减少语义丢失。
4.3 交互轮次的边际收益
从交互次数(turns)维度来看,更多的推理轮次在部分设置下确实能带来性能提升,但提升幅度有限。在 2048 context 下,Qwen2.5-Coder-3B 从单轮到三轮的准确率从 73.2% 提升到 76.4%; 然而当上下文提升到 4096 时,单轮与三轮的准确率几乎持平(80.2% vs 80.4%)。这说明在更强大的模型与更充足的上下文环境下,模型在单轮推理中已经能够完成自我校正与最优生成。
4.4 显式“检查”机制的收益与代价
实验中增加了一个“显式检查(check)”训练步骤,即让 Agent 在执行 SQL 生成后主动验证并修正结果。这一机制确实带来小幅性能提升 —— 以 Qwen2.5-Coder-3B 为例,准确率从 76.4% 提升至 77.6%;
但代价是训练时间几乎翻倍,更新周期明显增加。这表明,虽然显式检查能增强模型的自我纠错能力,但其训练成本较高,不适合轻量化场景。
详细的 Agent RL 原理及实战代码 加入 赋范空间 免费领取
校正与最优生成。
4.4 显式“检查”机制的收益与代价
实验中增加了一个“显式检查(check)”训练步骤,即让 Agent 在执行 SQL 生成后主动验证并修正结果。这一机制确实带来小幅性能提升 —— 以 Qwen2.5-Coder-3B 为例,准确率从 76.4% 提升至 77.6%;
但代价是训练时间几乎翻倍,更新周期明显增加。这表明,虽然显式检查能增强模型的自我纠错能力,但其训练成本较高,不适合轻量化场景。
详细的 Agent RL 原理及实战代码 加入 赋范空间 免费领取
还有更多免费的前沿技术解读、Agent开发实战等资源等你来拿~

















 524
524

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









