



作业要求:
使用pytroch等深度学习框架,构建一个图像分类模型。本人使用的是minist数据集马飞老师发的图片版本。
加分项:提供训练时的数据增强,给出训练过程的Loss,训练准确率、验证准确率等变化曲线,使用更多的网络结构。
import torch
import torch.nn as nn
from torch.utils.data import TensorDataset, DataLoader
import os
import torch.optim as optim
from PIL import Image
import numpy as np
import matplotlib.pyplot as plt
'''
绘图,老伙计了,每一次都用这个
'''
def drawing(x,y,title):
plt.plot(x,y)
plt.title(title)
plt.show()
'''
根据名称整出来训练集、测试集和对应的标签
这也是老伙计了
'''
def load_images_and_split(folder):
train_images = []
test_images = []
test_labels = []
train_labels = []
for filename in os.listdir(folder):
if filename.endswith('.jpg'):
img_path = os.path.join(folder, filename)
try:
img = Image.open(img_path)
img_array = np.array(img)
label = filename[-5]
if 'test' in filename:
test_images.append(img_array)
try:
# 尝试将标签转换为整数
test_labels.append(int(label))
except ValueError:
print(f"Invalid label in {filename}: {label}. Skipping this image.")
elif 'training' in filename:
train_images.append(img_array)
try:
train_labels.append(int(label))
except ValueError:
print(f"Invalid label in {filename}: {label}. Skipping this image.")
except Exception as e:
print(f"Error loading {img_path}: {e}")
train_images = np.array(train_images)
test_images = np.array(test_images)
train_labels = np.array(train_labels)
test_labels = np.array(test_labels)
return train_images, train_labels, test_images, test_labels
'''
数据增强,数据增强还有旋转啥的,但是手写数据集要是旋转了6就变成9了,就是纯粹噪声了,所以只选取了平移和放大
'''
def augment_data(images, labels):
augmented_images = []
augmented_labels = []
for img, label in zip(images, labels):
# 原始图像
augmented_images.append(img)
augmented_labels.append(label)
# 水平向右平移
shift_right = 3
img_shifted_right = np.roll(img, shift_right, axis=1)
img_shifted_right[:, :shift_right] = 0 # 填充空白部分为 0
augmented_images.append(img_shifted_right)
augmented_labels.append(label)
# 水平向左平移
shift_left = 3
img_shifted_left = np.roll(img, -shift_left, axis=1)
img_shifted_left[:, :shift_right] = 0 # 填充空白部分为 0
augmented_images.append(img_shifted_left)
augmented_labels.append(label)
# 放大操作
scale_factor = 1.2 # 放大倍数
pil_img = Image.fromarray(img.astype(np.uint8))
width, height = pil_img.size
new_width = int(width * scale_factor)
new_height = int(height * scale_factor)
resized_img = pil_img.resize((new_width, new_height), Image.LANCZOS)
# 将放大后的图像转换回 numpy 数组
resized_img_np = np.array(resized_img)
# 确保放大后的图像尺寸与原图像尺寸一致,这里简单地进行裁剪
if resized_img_np.shape[0] > img.shape[0] and resized_img_np.shape[1] > img.shape[1]:
start_x = (resized_img_np.shape[0] - img.shape[0]) // 2
start_y = (resized_img_np.shape[1] - img.shape[1]) // 2
resized_img_np = resized_img_np[start_x:start_x + img.shape[0], start_y:start_y + img.shape[1]]
augmented_images.append(resized_img_np)
augmented_labels.append(label)
augmented_images = np.array(augmented_images)
augmented_labels = np.array(augmented_labels)
return augmented_images, augmented_labels
#这个是老师ppt上的东西
class LeNet(nn.Module):
def __init__(self):
super(LeNet, self).__init__()
self.conv1 = nn.Conv2d(1, 6, 5) # 输入通道数1,输出通道数6,卷积核大小5x5
self.relu1 = nn.ReLU()
self.pool1 = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.relu2 = nn.ReLU()
self.pool2 = nn.MaxPool2d(2, 2)
self.fc1 = nn.Linear(16 * 4 * 4, 120)
self.relu3 = nn.ReLU()
self.fc2 = nn.Linear(120, 84)
self.relu4 = nn.ReLU()
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.pool1(self.relu1(self.conv1(x)))
x = self.pool2(self.relu2(self.conv2(x)))
x = x.view(-1, 16 * 4 * 4)
x = self.relu3(self.fc1(x))
x = self.relu4(self.fc2(x))
x = self.fc3(x)
return x
# 创建 LeNet 模型实例
model = LeNet()
folder_path = 'mnist_jpg/mnist_jpg'
train_images, train_labels, test_images, test_labels = load_images_and_split(folder_path)
booll=bool(input("数据增强输入1.不增强输入0"))
if booll:
print("开始增强")
train_images, train_labels=augment_data(train_images , train_labels)
print("增强完毕")
# 数据预处理
# 转换为 PyTorch 张量并调整维度,指定张量的数据类型是32的浮点数
train_images = torch.tensor(train_images, dtype=torch.float32).unsqueeze(1) / 255.0
train_labels = torch.tensor(train_labels, dtype=torch.long)
test_images = torch.tensor(test_images, dtype=torch.float32).unsqueeze(1) / 255.0
test_labels = torch.tensor(test_labels, dtype=torch.long)
# 创建数据集和数据加载器
train_dataset = TensorDataset(train_images, train_labels)
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
test_dataset = TensorDataset(test_images, test_labels)
test_loader = DataLoader(test_dataset, batch_size=64, shuffle=False)
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
#optim是pytorch的优化算法模块,model.parameter返回模型中所有需要学习的参数
optimizer = optim.Adam(model.parameters(), lr=0.001)
y_loss=[]#记录损失来画图
'''
评估模型准确率
'''
y_acc=[]
#使用已经有的模型进行预测,torch.no_grad的意思是禁止pytorch进行梯度计算
def val_model():
model.eval() # 将模型设置成评估模式
correct = 0
total = 0
with torch.no_grad():
for images, labels in test_loader:
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
global y_acc
y_acc.append(100*correct/total)
print(f'Accuracy on test set: {100 * correct / total}%')
'''
训练模型
'''
x_row=[]
num_epochs = 10
for epoch in range(num_epochs):
x_row.append(epoch+1)
#把模型调整成训练模式
model.train()
#初始化损失
running_loss = 0.0
#遍历train_loader的每一个批次数据
#注:enumerate是将一个可迭代对象组合为一个带索引的枚举对象,可以同时获得索引和对应的值。在这个项目中就是获取图像和标签
for i, (images, labels) in enumerate(train_loader):
#把优化器中梯度清零,否则梯度会累计
optimizer.zero_grad()
#将数据丢到模型里得到输出
outputs = model(images)
#计算损失,criterion前面定义了,是交叉熵损失
loss = criterion(outputs, labels)
#反向传播
loss.backward()
#根据得到的梯度,使用优化器(前面定义了是Adam)更新模型参数
optimizer.step()
#累加损失
running_loss += loss.item()
#这个y_loss是一个数组,前面定义了,用于后面的画图
y_loss.append(running_loss / len(train_loader))
#这个函数在前面定义了,用于评测准确率
val_model()
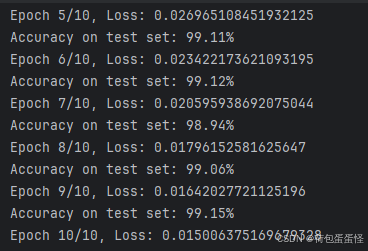
print(f'Epoch {epoch + 1}/{num_epochs}, Loss: {running_loss / len(train_loader)}')
#这一步是保存模型,保存数据增强和保存没增强的模型要注意换名字哦,要不然就白跑了,会被替换掉
torch.save(model,'augumented_data_model.pth')
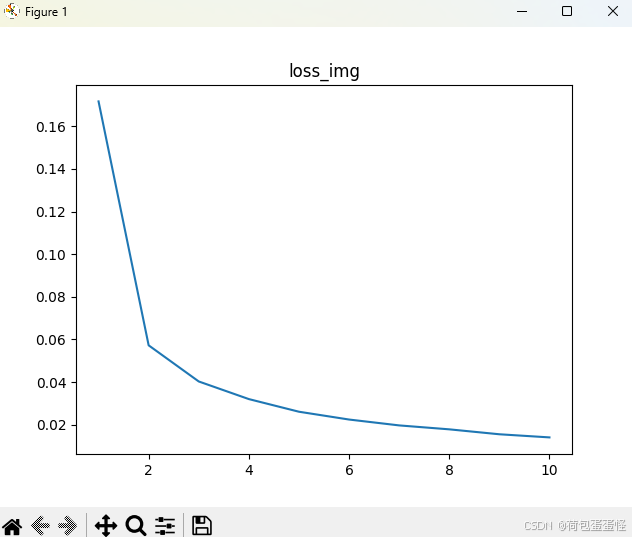
drawing(x_row,y_loss,'loss_img')
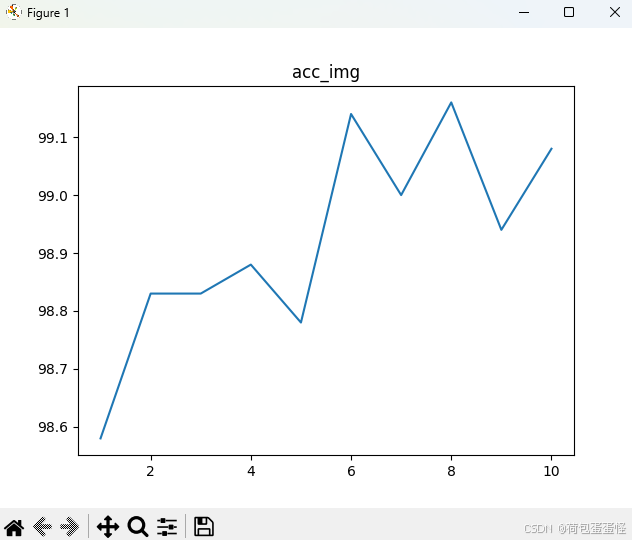
drawing(x_row,y_acc,'acc_img')
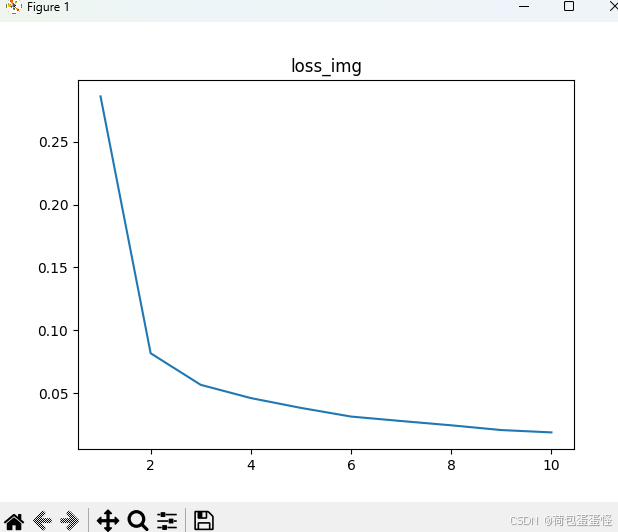
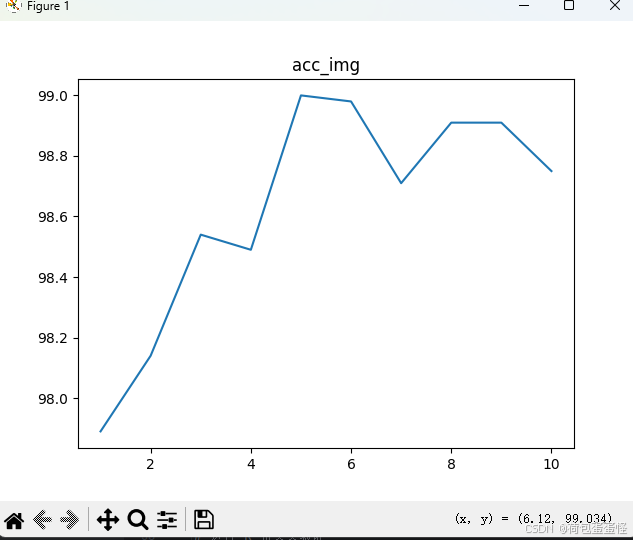
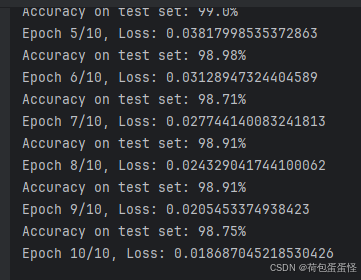
数据增强后,受制于还有四十分钟上课,就没跑到收敛了


















 2952
2952

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









