






 本文介绍如何使用Fiddler进行抓包并分析登录请求,包括配置浏览器代理、清除抓包记录及利用过滤功能定位登录请求。文中还提供了Python代码示例,展示如何通过requests库模拟登录。
本文介绍如何使用Fiddler进行抓包并分析登录请求,包括配置浏览器代理、清除抓包记录及利用过滤功能定位登录请求。文中还提供了Python代码示例,展示如何通过requests库模拟登录。
登陆前打开fiddler,进行抓包,当然你需要先配置浏览器代理。
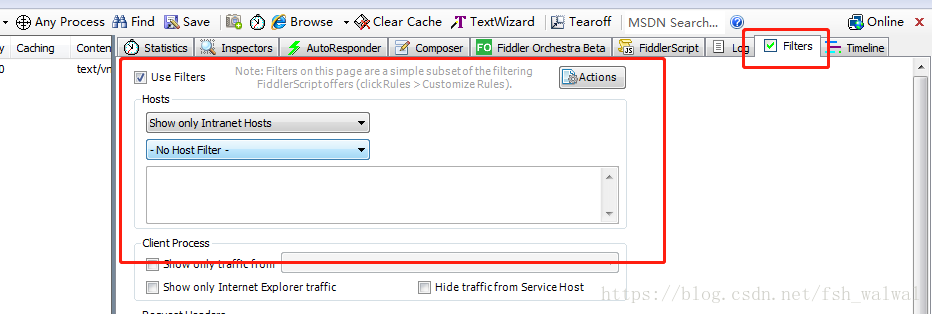
在点击登录前可以使用快捷键Ctrl+x清空fiddler抓取记录,这样可以更好的找到登陆的请求。同样你也可以使用fiddler的过滤功能,如下图:
至于如何确定那个是登陆的请求,一般使用Ctrl+f查找某些关键字,如用户名、密码
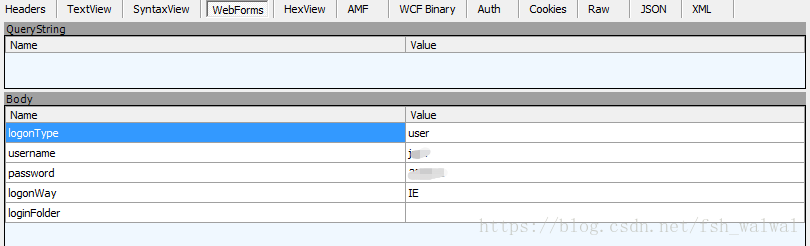
下图为一般登陆请求,使用post请求,用户名和密码为明文提交
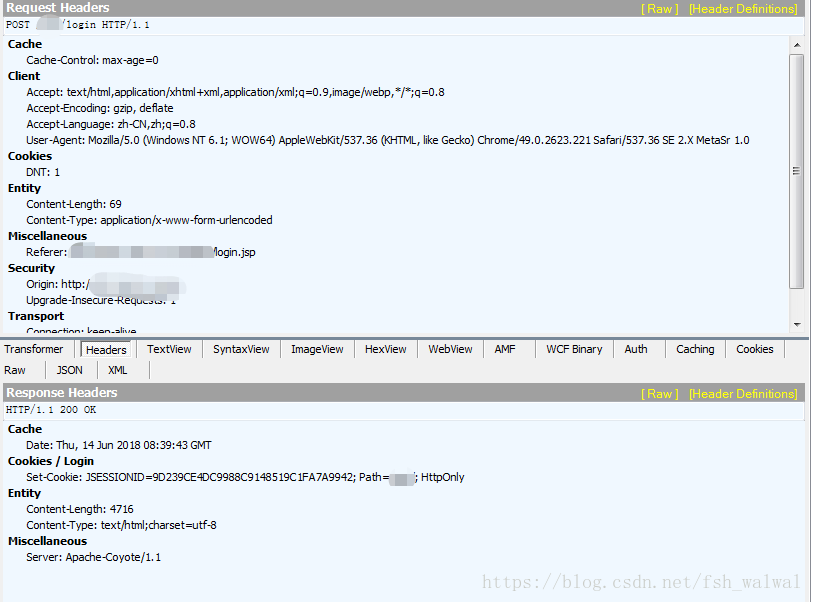
如下图为登陆的请求头和响应头信息,可见响应头中有set-cookie,但不一定登陆成功需要看响应内容才能确定时候登陆成功。
然后可以写代码了
self.session = self.gen_session() self.session.headers.update({ "User-Agent": "Dalvik/2.1.0 (Linux; U; Android 5.0.2; CHE-TL00H Build/HonorCHE-TL00H)", "Connection": "Keep-Alive", "Accept-Encoding": "gzip", "Content-Type": "application/x-www-form-urlencoded", }) params = { "userName": self.user_name, "pwd": self.pass_word, "userType": "0", } r = self.session.post(self.login_url, params=params)使用的是requests.session
理解登陆过程推荐看一下《图解HTTP》,顺便理解一下请求头和响应头中各个参数的作用,虽然我还没看完


















 577
577

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









