






 本文介绍了一款App的登录过程抓包分析方法,通过Fiddler工具捕获HTTP/HTTPS请求,详细解析了登录请求参数及响应内容,并给出了具体的Python代码实现。
本文介绍了一款App的登录过程抓包分析方法,通过Fiddler工具捕获HTTP/HTTPS请求,详细解析了登录请求参数及响应内容,并给出了具体的Python代码实现。
这是一款app,同样使用fiddler进行抓包,抓包之前需要配置手机代理,可自行找教程。
抓包前可以禁用其他app的wifi流量,这样确保所有请求都是该app发出的,当然fiddler只能抓取HTTP/HTTPS,如果要抓取TCP/UDP的需要WireShark。
当然这款app可以使用fiddler抓取。在手机上登陆后,按用户名全局搜索,如下图
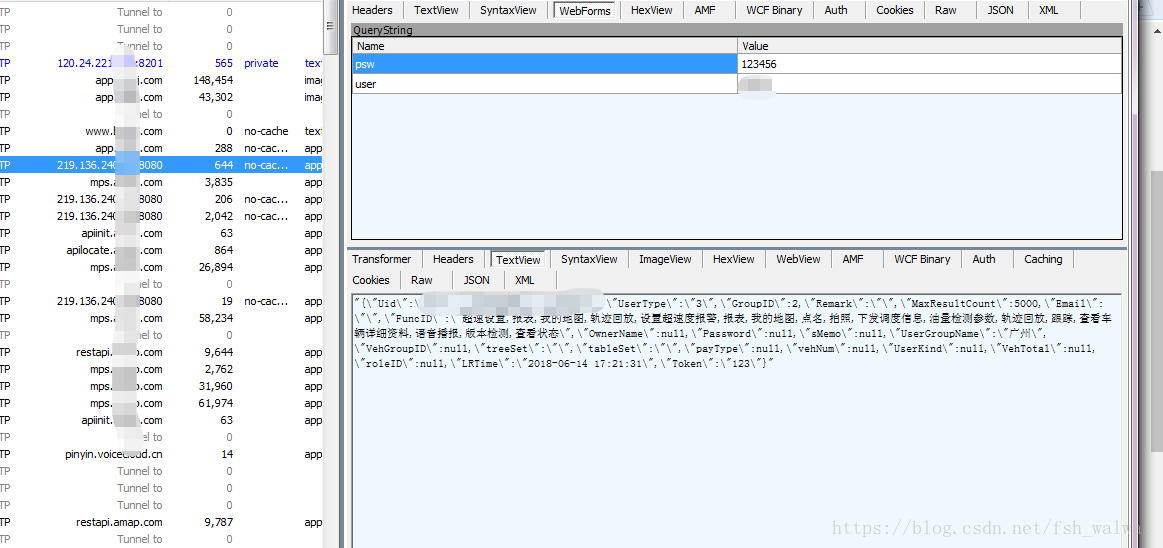
( ⊙ o ⊙ )!高亮咋没有了,算了,将就着看吧,选中的请求是第一个出现用户名的,可以看到响应内容明显是登陆成功后的,但是在app打开时出现的请求ip并不是这个,而且登陆时填写了三个参数,这个登陆请求只提交了两个,于是按照这个ip全局搜索。
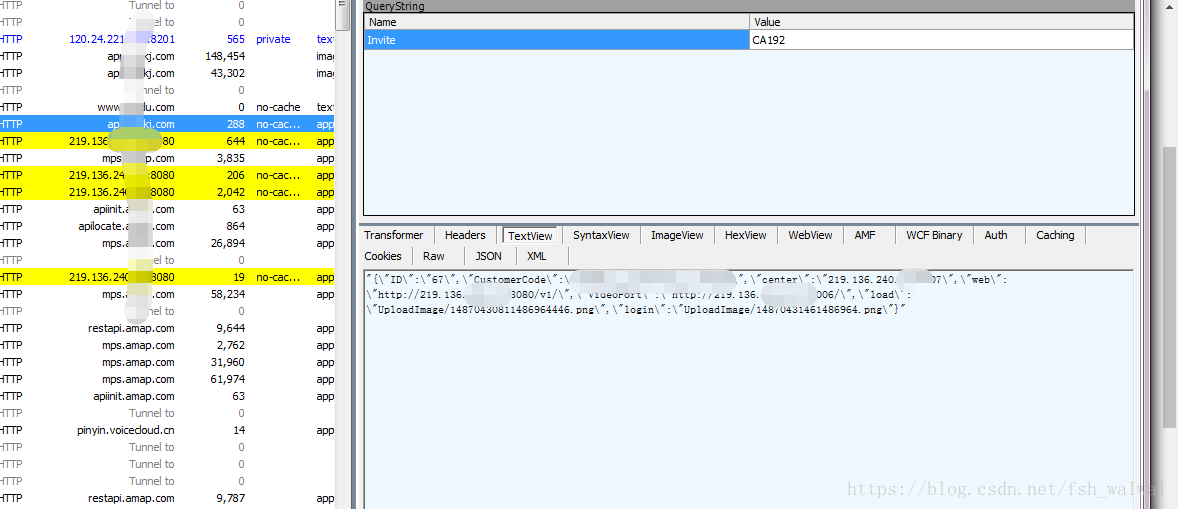
这次又高亮了,查看第一个高亮,发现响应内容中出现了那个ip,也有登陆填写的第三个参数。
于是可以写代码了:
self.session = self.gen_session() url = 'http://app.******.com/v1/Invite?Invite=%s' % self.invite headers = { "User-Agent": "Dalvik/2.1.0 (Linux; U; Android 5.0.2; CHE-TL00H Build/HonorCHE-TL00H)", "Connection": "Keep-Alive", "Accept-Encoding": "gzip", } r = self.session.get(url, headers=headers) r_dict = demjson.decode(demjson.decode(r.text)) self.web = r_dict.get('web') if not self.web: print ("error with get web url, %s" % r.text) exit() login_url = '%svalidate' % self.web params = { "psw": self.pass_word, "user": self.user_name, } r = self.session.get(login_url, params=params, headers=headers)上面的代码是登陆部分的,只是类里面的一个login方法


















 1524
1524

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









