




 本文深入浅出地介绍了机器学习的三大核心任务:聚类、回归和分类。详细阐述了聚类作为无监督学习的典型应用,回归分析的“由果索因”归纳思想,以及分类算法在实际应用中的广泛使用。同时,文中还探讨了分类器的评估指标——召回率和精确率。
本文深入浅出地介绍了机器学习的三大核心任务:聚类、回归和分类。详细阐述了聚类作为无监督学习的典型应用,回归分析的“由果索因”归纳思想,以及分类算法在实际应用中的广泛使用。同时,文中还探讨了分类器的评估指标——召回率和精确率。
第1章 机器学习是什么
Table of Contents
1.1 聚类 clustering
聚类是一种典型的“无监督学习”,是把物理对象或抽象对象的集合分组为由彼此类似的对象组成的多个类的分析过程。
“聚类”的思维方式:特征形态的相同或近似划在一个概念下,特征形态不同的划在不同的概念下。
常用聚类算法:K-Means、DBSCAN,基本思路:利用每个向量之间的“距离”——空间中的欧式距离或是曼哈顿距离,从远近判断是否从属于同一类别。
1.2 回归 regression
回归分为:线性回归和非线性回归
回归分析:“由果索因”的过程,是一种归纳思想;由大量的观测而来的向量(数字)是某种样态,设计一种假设描述它们之间蕴含的关系。
线性回归:观察和归纳样本的过程中认为向量和最终的函数值呈现线性的关系
-
w是指1*n的矩阵,x是指n*1的矩阵,wx指两个矩阵的内积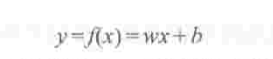


非线性回归类中,在机器学习领域应用最多的当属逻辑回归。在该模型中观察者假设的前提的y只有两种值:一种是1,一种是0,或者说“是”或“否”的判断。
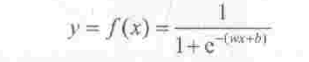
w是指1*n的矩阵,x是指n*1的矩阵,wx指两个矩阵的内积 ,如果设z=wx+b,则
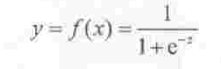
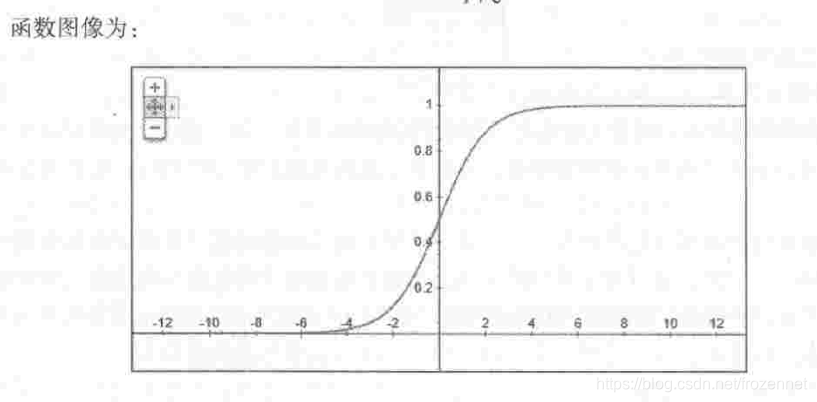
横轴是z,纵轴是y,一个多维的x经过两次映射,投射在y上是一个取值只有1和0的二项分布。
1.3 分类
分类是机器学习中使用最多的一类算法,通常将分类算法成为“分类器”。
构建分类器的学习过程,是建立一种输入到输出的映射逻辑,以及让它自己调整这种逻辑关系,使得逻辑更为合理,合理与否的判断依靠召回率和精确率两个指标。
召回率:检索出的相关样本和样本库(待测对象库)中所有的相关样本的比率,衡量的是分类器的查全率。
精确率:是检索出的相关样本数与检索出的样本总数的比率,衡量的是分类器的查准率。

分类的训练过程和回归的训练过程

参考
高扬,卫峥.白话深度学习与TensorFlow[M].机械工业出版社:北京,2017:2-14

















 17万+
17万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









