






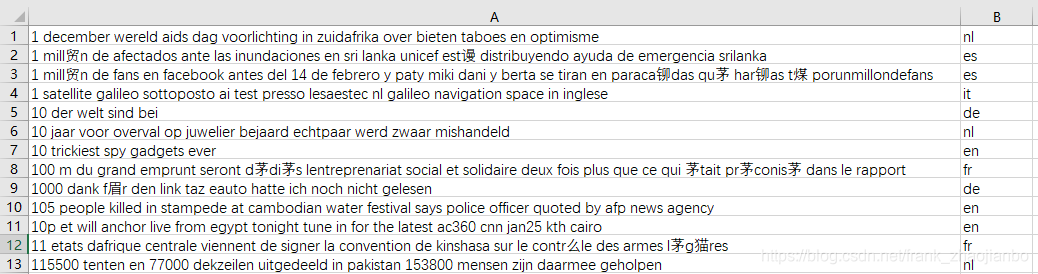
data,csv
代码实现:
from sklearn.model_selection import train_test_split
from sklearn.naive_bayes import MultinomialNB #采用多项式的朴素贝叶斯
from sklearn.feature_extraction.text import CountVectorizer # 从sklearn.feature_extraction.text里导入CountVectorizer
import re
in_f = open('data.csv')#读取数据
lines = in_f.readlines()
in_f.close()
dataset = [(line.strip()[:-3], line.strip()[-2:]) for line in lines]
# print(dataset[:5])
x, y = zip(*dataset)
x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=1)#分配训练数据和测试数据
def remove_noise(document):#去点噪声
noise_pattern = re.compile("|".join(["http\S+", "\@\w+", "\#\w+"]))
clean_text = re.sub(noise_pattern, "", document)
return clean_text.strip()
#https://scikit-learn.org/stable/modules/generated/sklearn.feature_extraction.text.CountVectorizer.html
CountVectorizer(
lowercase=True, # lowercase the text 把文章中的大写都变为小写
analyzer='char_wb', # tokenise by character ngrams
ngram_range=(1,2), # use ngrams of size 1 and 2
max_features=500, # keep the most common 500 ngrams 按频率大小选择前500的features(就是词表中频率最高的500个词)
preprocessor=remove_noise
)
vec = CountVectorizer(stop_words= 'english')#创建词袋数据结构
X = vec.fit_transform(x_train)#<class 'scipy.sparse.csr.csr_matrix'>
# X的结构 print(count_vec.fit_transform(X_test))
# (0:data输入列表的元素索引(第几个文章(列表元素)),词典里词索引) 词频
# (0, 7) 2
# (0, 25) 2
# (0, 34) 2
# (0, 4) 1
# (0, 0) 1
print('\n词典中的特征词的个数:',len(vec.get_feature_names())) # 输出维度数。
print('\n词典中的特征词:',vec.get_feature_names())# 输出各个维度的特征含义。
print( '\n词典中词的数量:',vec.vocabulary_.__len__())#输出词典的数量
print( '\n词典中的词 :',vec.vocabulary_)#输出词典中的词
# for key,value in vec.vocabulary_.items():#打印字典
# print(key,value)
classifier = MultinomialNB()
classifier.fit(X, y_train)
Test = vec.transform(x_test)
print(classifier.score(Test, y_test))
sentence = ['wp deutsche version auch schon da wordpress 304 important security update']
sen = vec.transform(sentence)
print(classifier.predict(sen))
data,csv 部分数据


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









