






Transformer 详解
首先,我们从宏观的视角开始讲一下 Transformer。
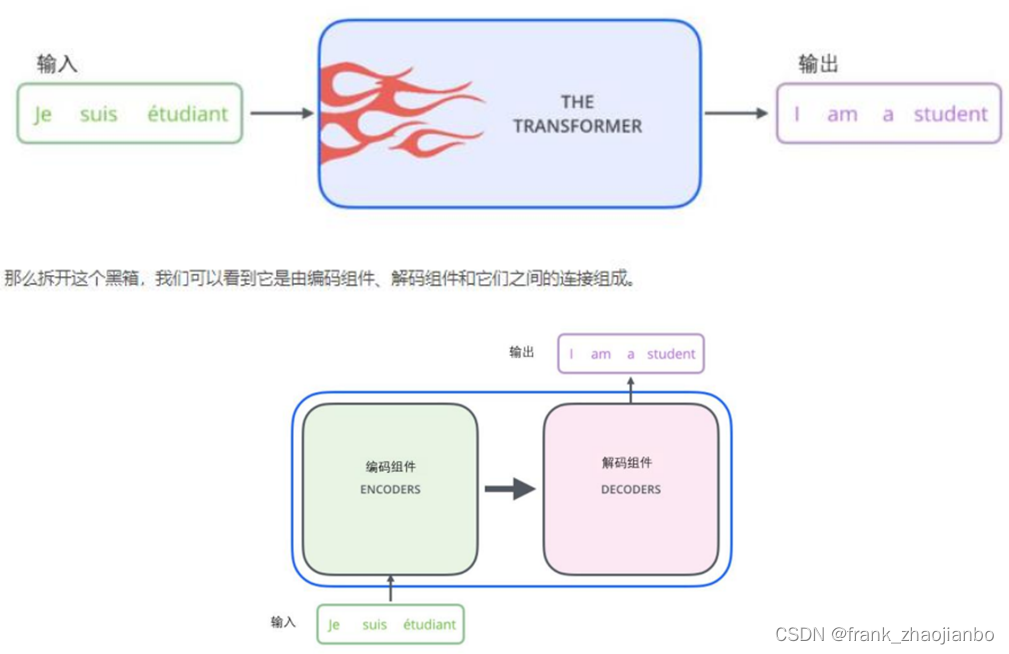
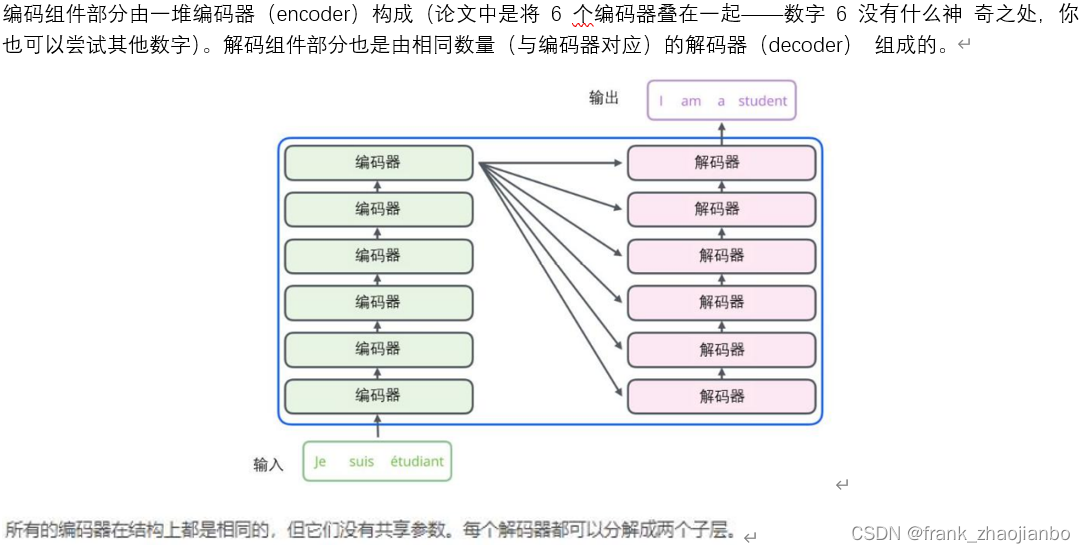
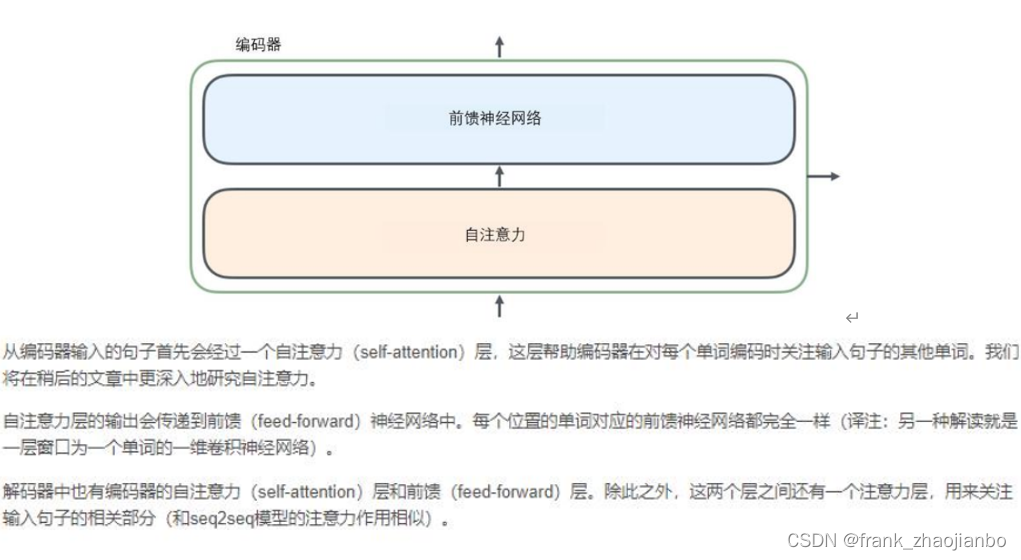
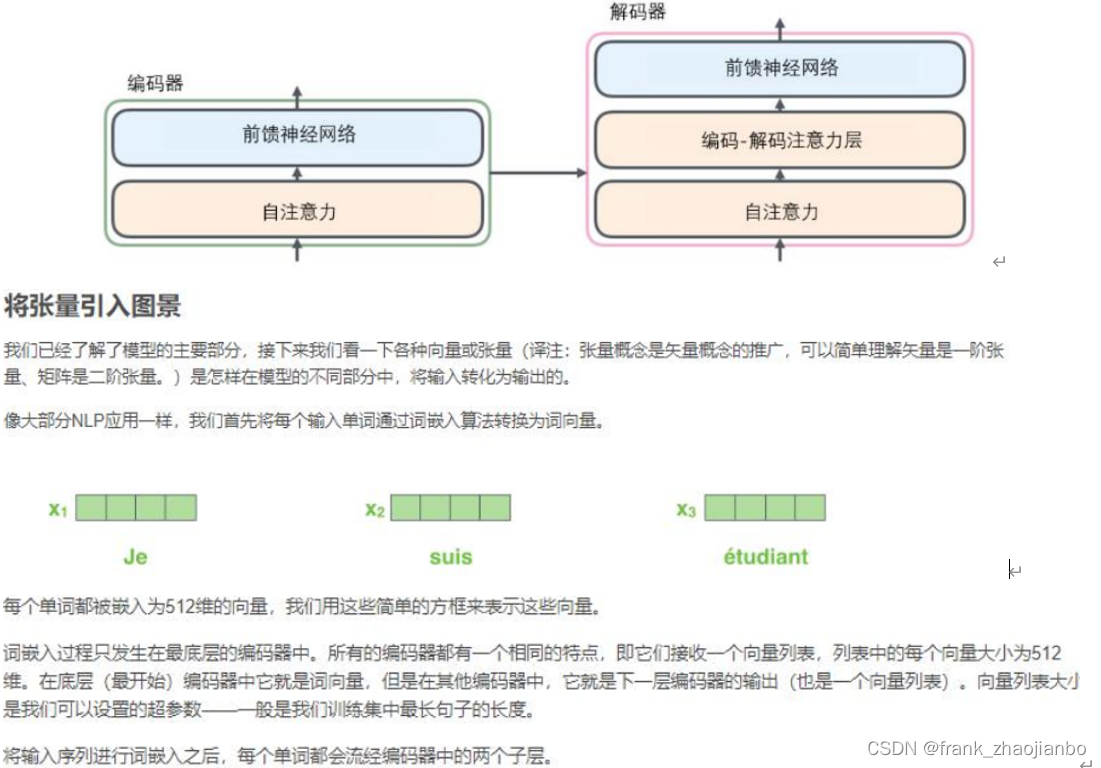
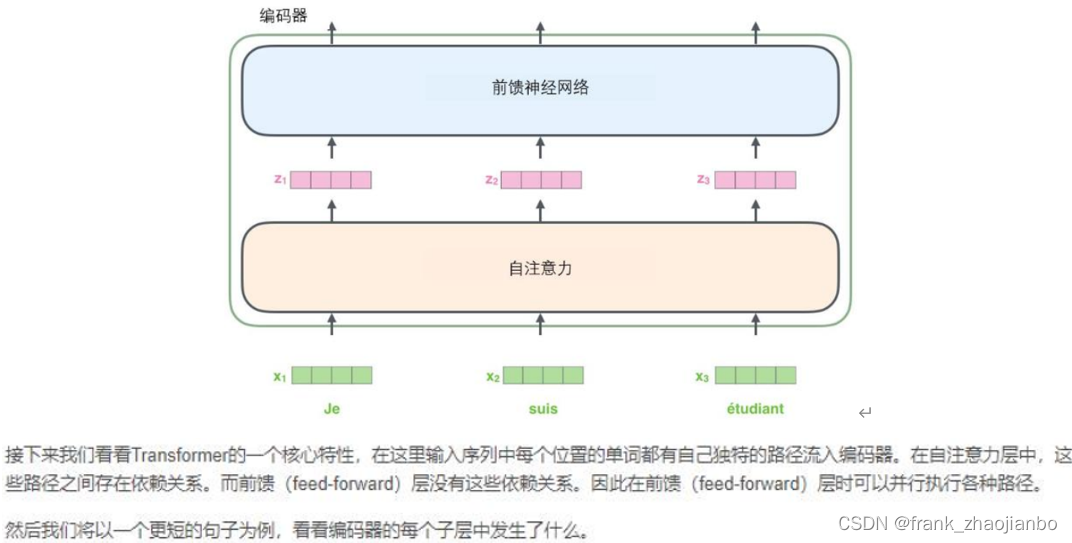
编码器 (encoder)
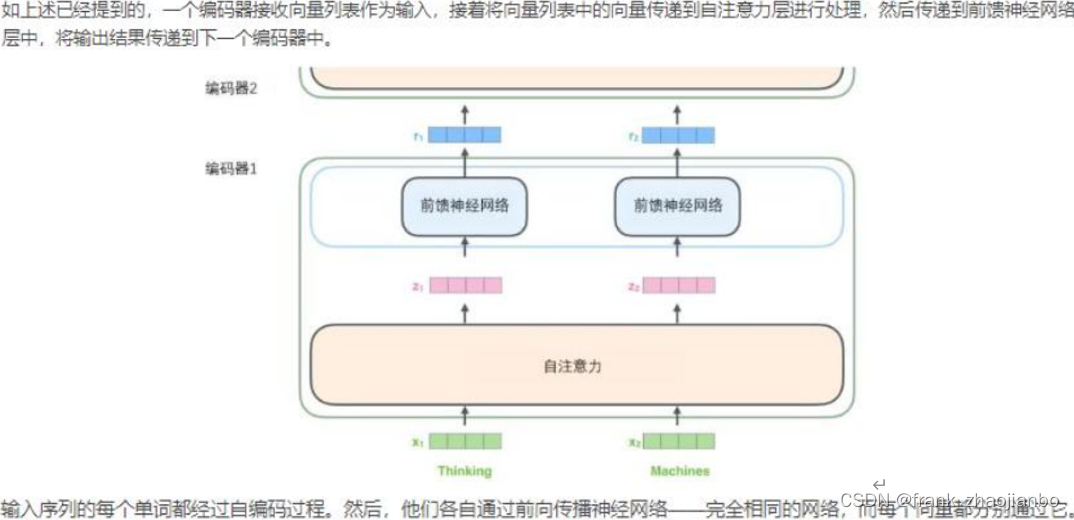
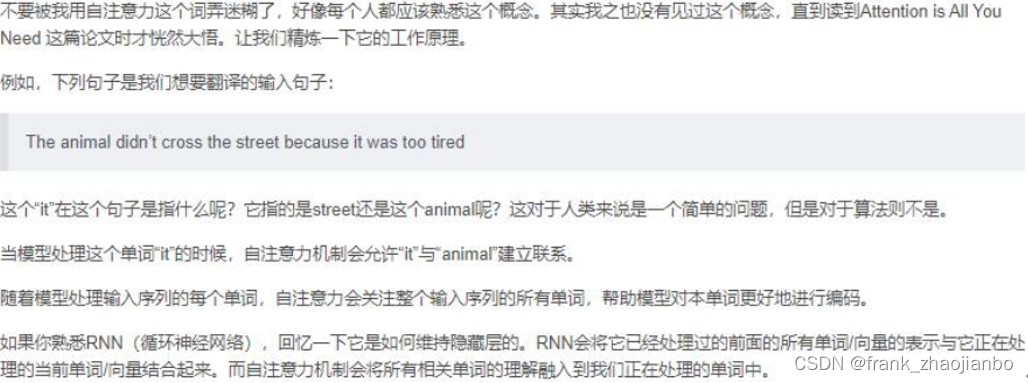
注意力机制

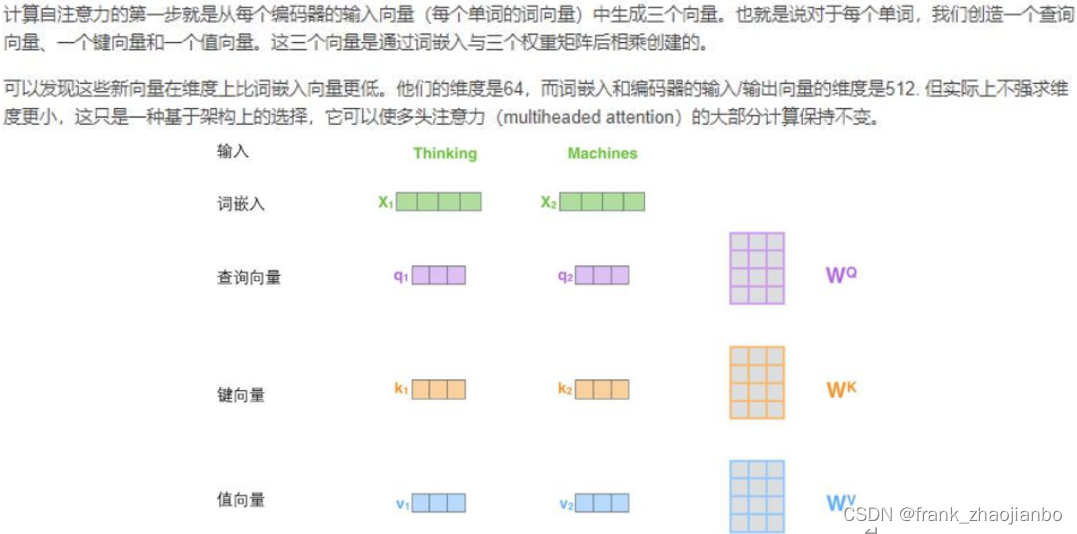

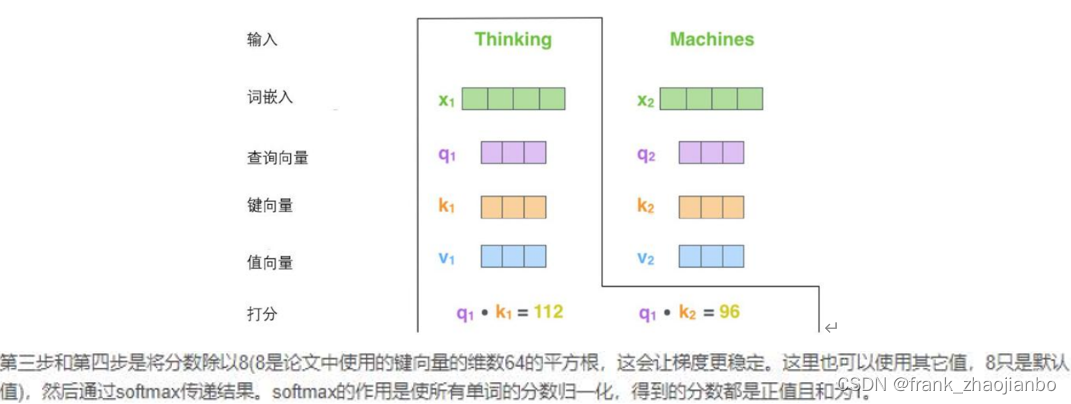
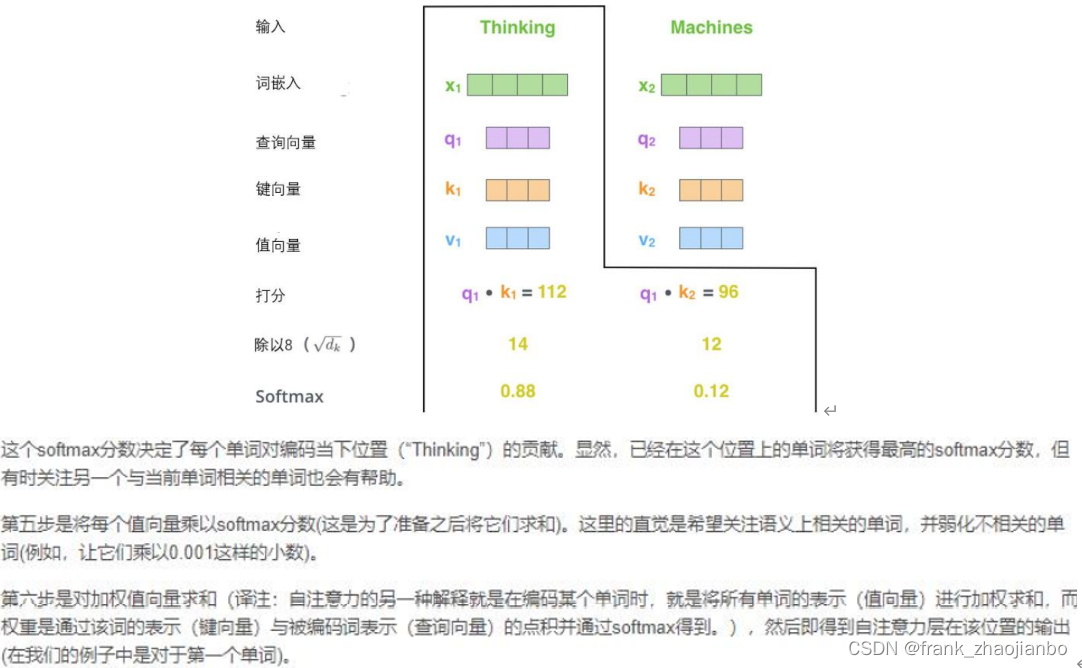
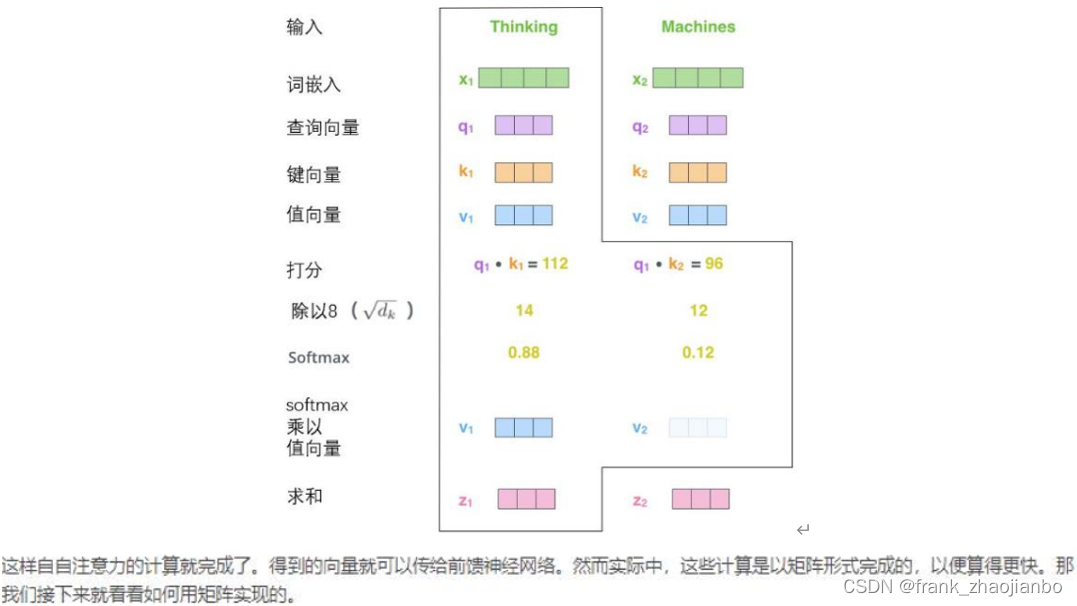
查询向量、键向量和值向量

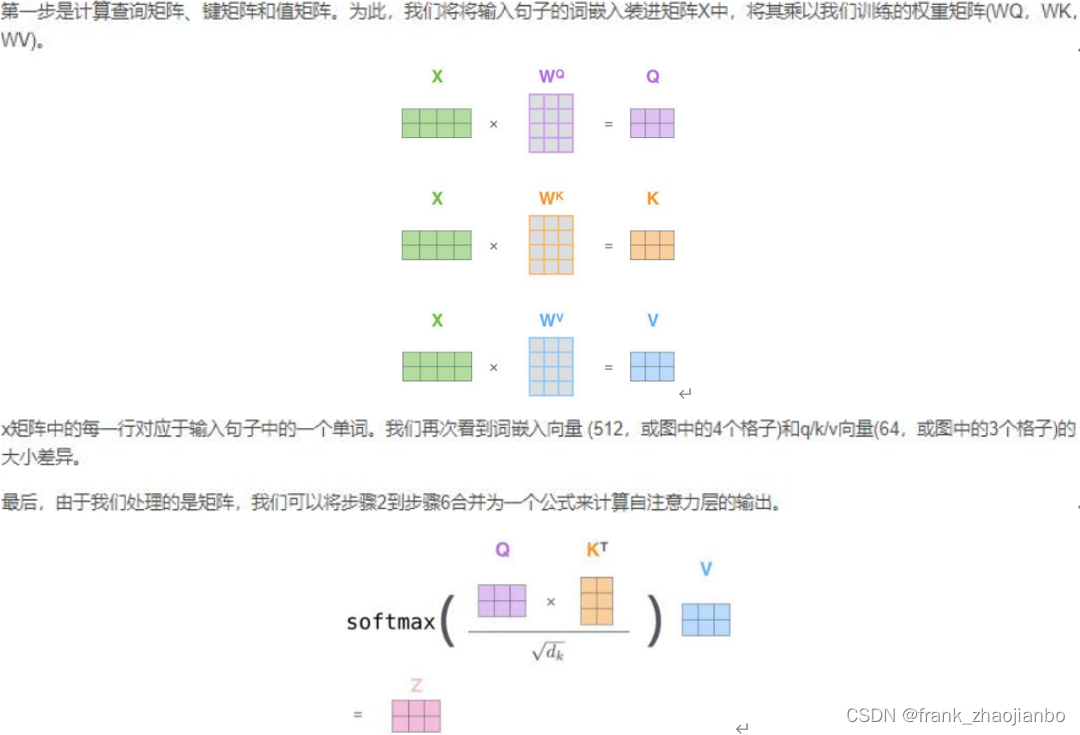
矩阵运算实现自注意力机制
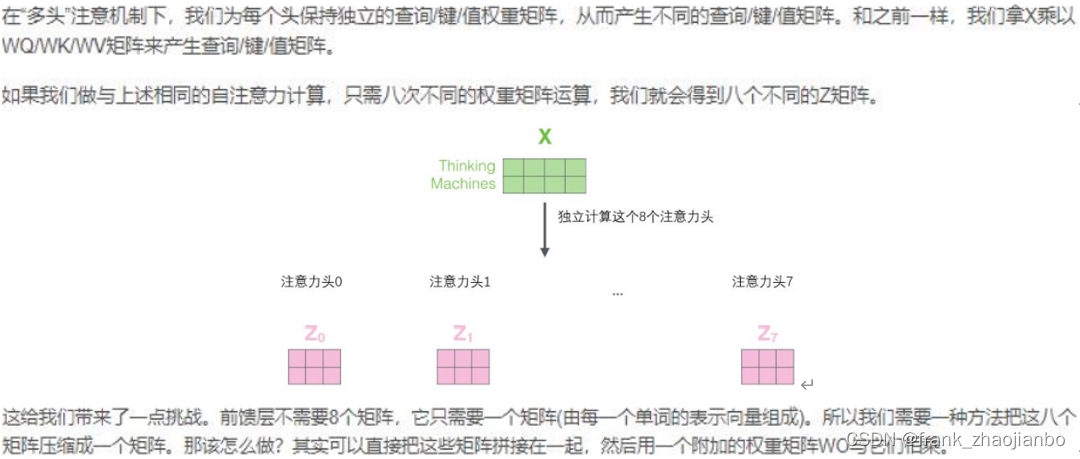
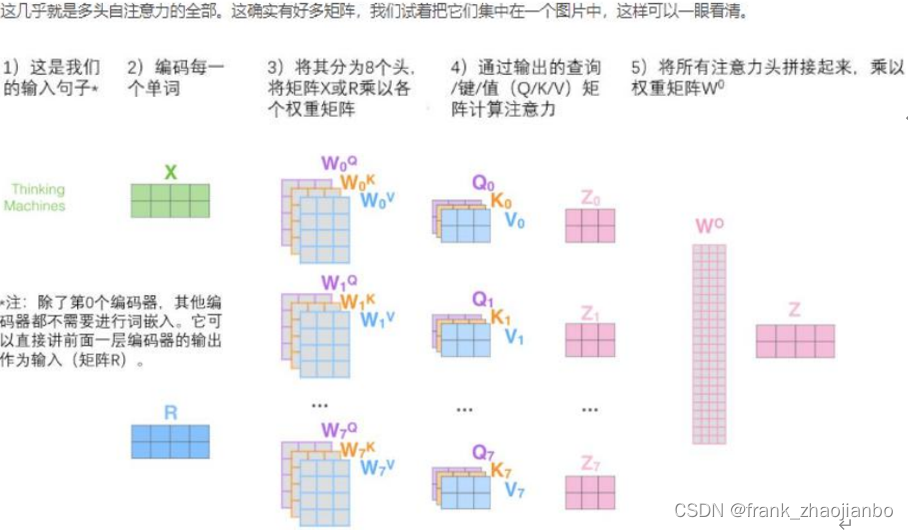
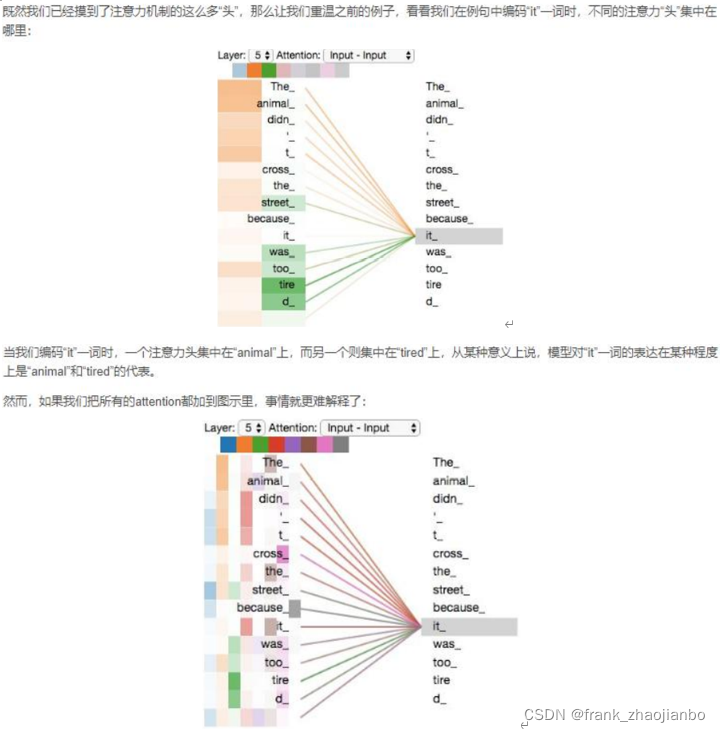
多头注意力


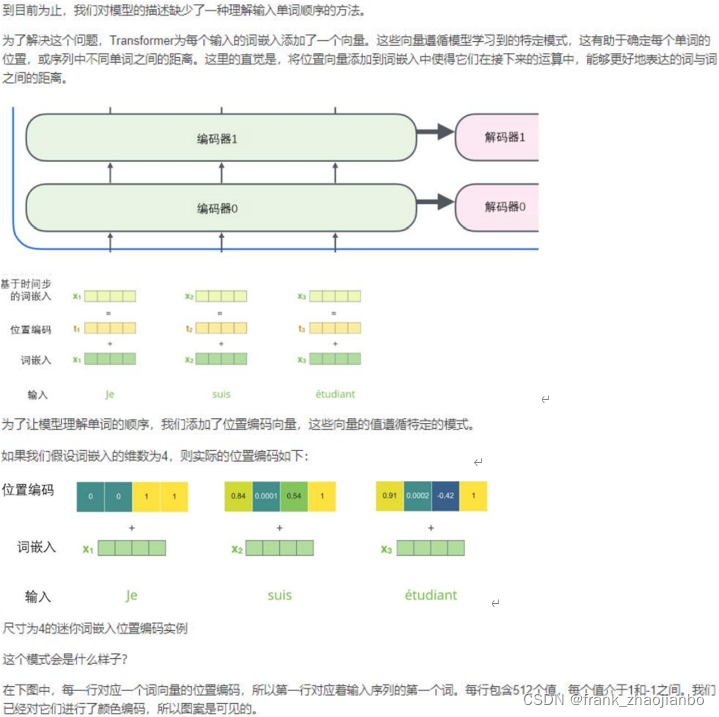
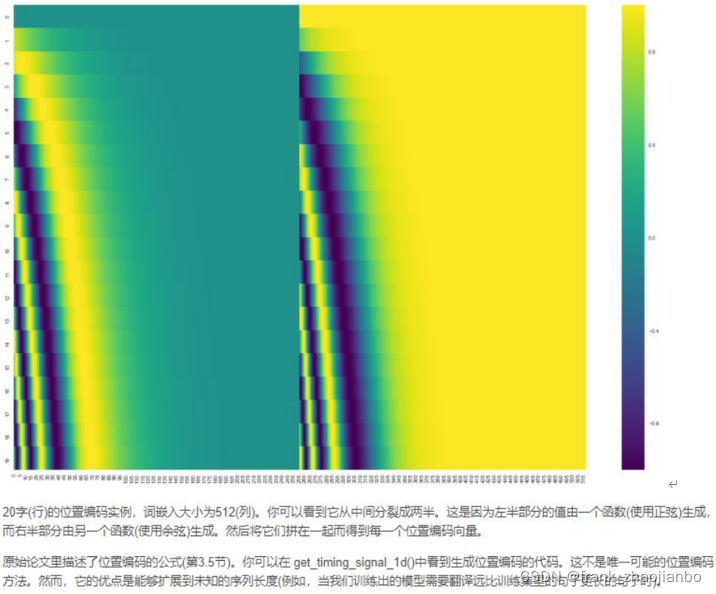
位置编码表示序列的顺序(positional embedding)
残差模块

层-归一化步骤:https://arxiv.org/abs/1607.06450
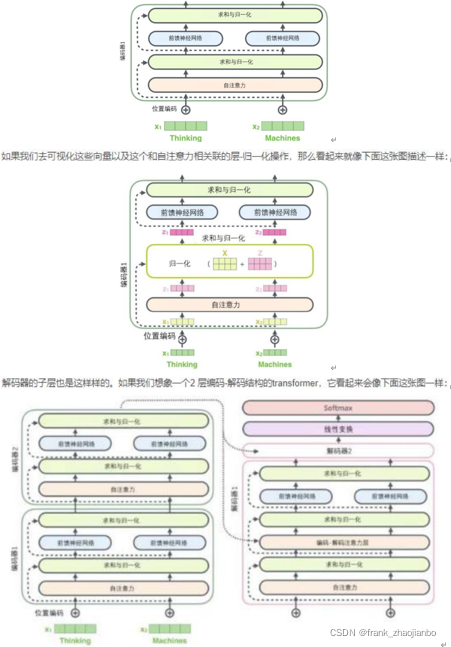
解码机(decoder)
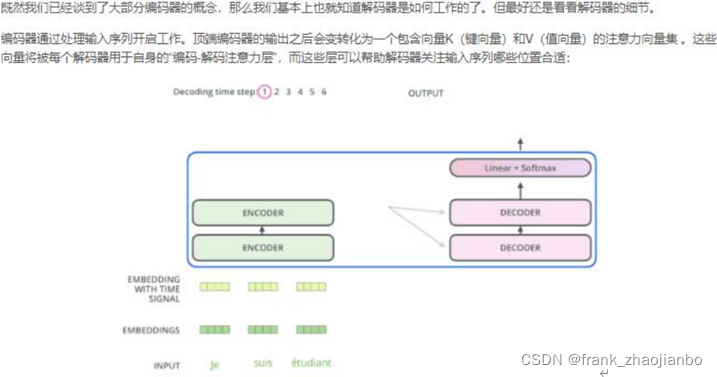
在完成编码阶段后,则开始解码阶段。解码阶段的每个步骤都会输出一个输出序列(在这个例子里,是英语翻译的句子)的元素。
接下来的步骤重复了这个过程,直到到达一个特殊的终止符号,它表示 transformer 的解码器已经完成了它的输出。每个步骤的输出在下一个时间步被提供给底端解码器,并且就像编码器之前做的那样,这些解码器会输出它们的解码结果 。另外,就像我们对编码器的输入所做的那样,我们会嵌入并添加位置编码给那些解码器,来表示每个单词的位置。
而那些解码器中的自注意力层表现的模式与编码器不同:在解码器中,自注意力层只被允许处理输出序 列中更靠前的那些位置。在 softmax 步骤前,它会把后面的位置给隐去(把它们设为-inf)。 这个“编码-解码注意力层”工作方式基本就像多头自注意力层一样,只不过它是通过在它下面的层来创造 查询矩阵,并且从编码器的输出中取得键/值矩阵。
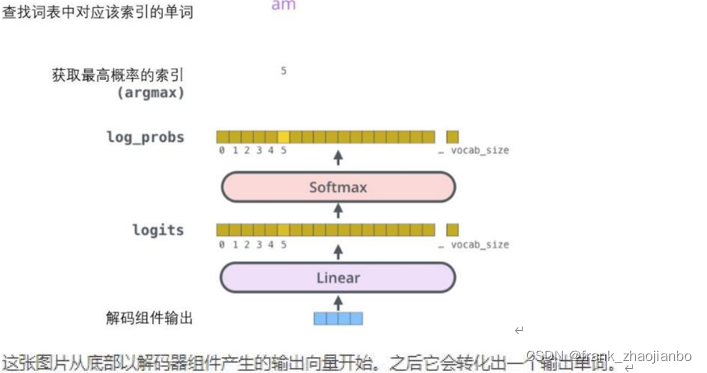
Softmax 层



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









