







 本文详细介绍了Elasticsearch中IK分词器的两种模式:ik_max_word与ik_smart的区别及应用场景,并通过实例展示了两种模式下对同一文本进行分词的不同结果。
本文详细介绍了Elasticsearch中IK分词器的两种模式:ik_max_word与ik_smart的区别及应用场景,并通过实例展示了两种模式下对同一文本进行分词的不同结果。
- 安装地址
首先访问官网:https://github.com/medcl/elasticsearch-analysis-ik
- ik_max_word 和 ik_smart 什么区别?
ik_max_word: 会将文本做最细粒度的拆分,比如会将“中华人民共和国国歌”拆分为“中华人民共和国,中华人民,中华,华人,人民共和国,人民,人,民,共和国,共和,和,国国,国歌”,会穷尽各种可能的组合,适合 Term Query;
ik_smart: 会做最粗粒度的拆分,比如会将“中华人民共和国国歌”拆分为“中华人民共和国,国歌”,适合 Phrase 查询。
- 测试验证分词引擎的结果
POST _analyze
{
"analyzer": "ik_max_word",
"text": "中华人民共和国国歌"
}
ik_max_word 查询结果:
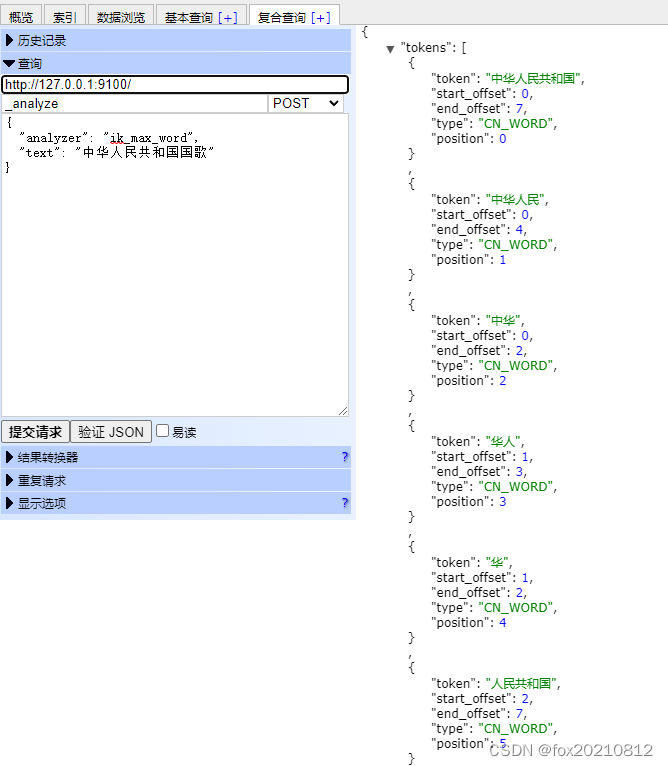
{
"tokens": [
{
"token": "中华人民共和国",
"start_offset": 0,
"end_offset": 7,
"type": "CN_WORD",
"position": 0
}
,
{
"token": "中华人民",
"start_offset": 0,
"end_offset": 4,
"type": "CN_WORD",
"position": 1
}
,
{
"token": "中华",
"start_offset": 0,
"end_offset": 2,
"type": "CN_WORD",
"position": 2
}
,
{
"token": "华人",
"start_offset": 1,
"end_offset": 3,
"type": "CN_WORD",
"position": 3
}
,
{
"token": "华",
"start_offset": 1,
"end_offset": 2,
"type": "CN_WORD",
"position": 4
}
,
{
"token": "人民共和国",
"start_offset": 2,
"end_offset": 7,
"type": "CN_WORD",
"position": 5
}
,
{
"token": "人民",
"start_offset": 2,
"end_offset": 4,
"type": "CN_WORD",
"position": 6
}
,
{
"token": "民",
"start_offset": 3,
"end_offset": 4,
"type": "CN_CHAR",
"position": 7
}
,
{
"token": "共和国",
"start_offset": 4,
"end_offset": 7,
"type": "CN_WORD",
"position": 8
}
,
{
"token": "共和",
"start_offset": 4,
"end_offset": 6,
"type": "CN_WORD",
"position": 9
}
,
{
"token": "国",
"start_offset": 6,
"end_offset": 7,
"type": "CN_CHAR",
"position": 10
}
,
{
"token": "国歌",
"start_offset": 7,
"end_offset": 9,
"type": "CN_WORD",
"position": 11
}
]
}
- ik_smart 引擎查询结果
{
"tokens": [
{
"token": "中华人民共和国",
"start_offset": 0,
"end_offset": 7,
"type": "CN_WORD",
"position": 0
}
,
{
"token": "国歌",
"start_offset": 7,
"end_offset": 9,
"type": "CN_WORD",
"position": 1
}
]
}

















 394
394

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









