 改进LoRaWAN自适应数据速率
改进LoRaWAN自适应数据速率




一种改进的LoRaWAN网络自适应数据速率
摘要
目前,LoRaWAN采用自适应数据速率(ADR),旨在通过管理扩频因子(SF)和发射功率来提供可靠且节能的通信。然而,时变信道条件严重影响了ADR的性能,导致大量数据包丢失。本文提出了一种改进的自适应数据速率(I-ADR),该方法在初始部署期间根据网关处的接收信号强度为终端设备分配扩频因子。I-ADR算法在城市环境中针对确认模式和非确认模式进行了评估。仿真结果表明,与典型自适应数据速率相比,I-ADR通过降低干扰的影响,在成功率方面表现更优。
关键词 :LoRaWAN,自适应数据速率,确认模式,非确认模式,干扰。
1. 引言
远距离广域网(LoRaWAN)[1]包含介质访问控制层,而LoRa描述的是物理层。由于具有远距离、低功耗和低成本的特点,LoRaWAN被广泛应用于物联网。LoRaWAN网络架构采用星型拓扑,由三个主要组件构成,即终端设备(EDs)、网关(GW)和网络服务器(NS)。
在LoRaWAN中,NS实施了一种称为自适应数据速率(ADR)的控制机制,通过管理扩频因子(SF)、发射功率(TP)和通信信道,以实现更高的包成功比率和低能耗性能[2]。
LoRaWAN中的自适应数据速率机制主要针对静态终端设备[2]设计。然而,时变信道条件[3],[4]严重影响了自适应数据速率的性能。文献[3]表明,该自适应数据速率方案缺乏应对时变信道条件的敏捷性。该自适应数据速率方案需要多次
当网络服务器开始监控最近接收到的N个上行数据包(即,N=20)时,需要数小时到数天的时间才能收敛到稳定且节能的通信状态。为了提高自适应数据速率在时变信道条件下的性能,作者提出了一种自适应数据速率+方案[5]。该自适应数据速率+方法通过对网络服务器接收到的最近N个数据包的信噪比(SNR)取平均值,对基本自适应数据速率进行了轻微修改。
最近,已有研究在移动环境中评估了自适应数据速率的性能[6]。文献[6]表明,由于自适应数据速率机制仅适用于静态终端设备,因此在移动场景中效率不高。
为了提升自适应数据速率在静态环境下的性能,本文提出了一种改进的自适应数据速率(I‐ADR)。
I‐ADR在初始部署阶段根据网关灵敏度值分配合适的扩频因子。I‐ADR未对终端设备和网络服务器上的典型自适应数据速率机制其余部分进行修改。所提出的I‐ADR在包成功比率方面提升了性能,并减少了由信道干扰引起的数据包丢失。
本文的其余部分组织如下:第2节介绍了所提出的I‐ADR算法。第3节给出了ADR、ADR+和所提出的I‐ADR的实验结果与分析,而最后的第4节对本文进行了总结。
2. 提出的改进型自适应数据速率方案
为了改进自适应数据速率(ADR)方案,引入了基于网关灵敏度的初始扩频因子分配机制,如我们之前的工作[7]所示。I‐ADR的主要目的是在初始部署网络时,根据网关处的接收信号强度来分配扩频因子(SF)。如[8],[9],所述,扩频因子的分配主要基于扩频因子分配范围(SF7至SF12)。然而,由于阴影效应和建筑物穿透损耗导致的时变信道条件,I‐ADR并未采用固定宽度的扩频因子范围。如图1所示,每个终端设备计算在网关处的接收信号强度(ܲ ௫ )。根据ܲ ௫的值,扩频因子的分配需确保ܲ௫始终高于每个扩频因子的灵敏度(Si,,如表I所示)。I‐ADR的详细流程如图1所示。
表I. ED和GW的灵敏度
| SF | BW [kHz] | (ࡿ ሻ | (ࡿࢋ ሻ |
|---|---|---|---|
| 12 | 125 | -142.5 | -137.0 |
| 11 | 125 | -140.0 | -135.0 |
| 10 | 125 | -137.5 | -133.0 |
| 9 | 125 | -135.0 | -130.0 |
| 8 | 125 | -132.5 | -127.0 |
| 7 | 125 | -130.0 | -124.0 |
网关灵敏度
终端设备灵敏度
3. 实验结果
本节通过模拟NS‐3[10],评估基于LoRaWAN的自适应数据速率、ADR+[5]以及所提出的I‐ADR方案的性能。
仿真背景
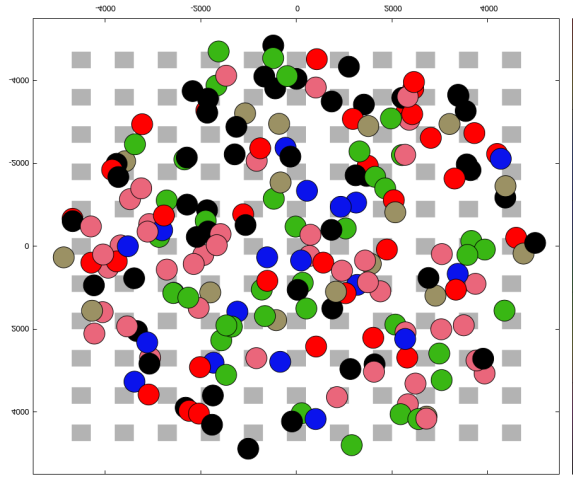
在仿真中,M个终端设备均匀分布在单个网关周围5公里半径范围内。网关和终端设备天线高度分别设置为15米和1.5米。仿真中的每个终端设备每天发送24个数据包,数据包大小为51字节。为了模拟真实环境,仿真结构采用基于曼哈顿布局模型的方形建筑物,并引入相关阴影衰落[11]。I‐ADR和典型自适应数据速率的带建筑物仿真环境如图2所示。仿真中使用的其余参数见表II。
表II. 仿真参数。
| 参数 | 值 |
|---|---|
| 仿真时间 [天] | 2 |
| M | 200‐1000 |
| ADR | 在终端设备和网络服务器上运行 初始扩频因子 = 12[12] |
| 通信模式 | 确认模式和非确认模式 |
| 路径损耗指数 | 3.76 |
| 传播损耗模型 | 对数距离 |
| 阴影效应 | 去相关距离= 110 m 和方差 = 6 dB [11] |
| 干扰模型 | 如我们之前的工作 [13] |
| 建筑物穿透损耗模型 | 如我们之前的工作 >@ |
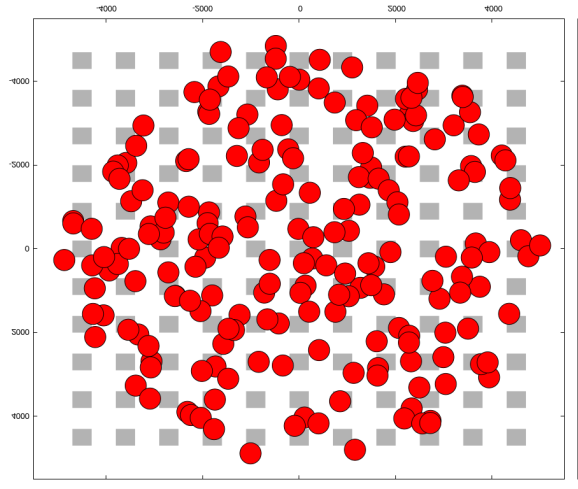 使用I‐ADR的初始扩频因子分配)
使用I‐ADR的初始扩频因子分配)
使用典型自适应数据速率(含SF=12)的初始扩频因子分配)
性能分析
图3显示了自适应数据速率、自适应数据速率+和I‐ADR在确认模式(CON‐urban)中的M=400。图3所示的趋势表明,这些方案大约需要16小时才能收敛到可能的稳定状态,这证实了[12]中所展示的相同事实。图3的主要目的是突出由于网络服务器监控N个上行链路数据包所需时间而导致的收敛缓慢问题。然而,由于采用了初始最优扩频因子分配,I‐ADR在收敛期内的数据包丢失率相较于ADR和ADR+更低。
的城市环境中,确认模式下每小时的包成功比率)
在城市环境(UNC‐urban)中,ADR、ADR+和I‐ADR在非确认模式下的每小时数据包成功比率如图4所示。总体而言,成功率高于图4中的情况。这是因为在ADR中,终端设备通常不需要来自网关的任何下行链路消息。然而,在ADR中,终端设备在每发送64个上行链路数据包后会周期性地接收来自网关的下行链路消息。如果在发送64个上行链路数据包后仍未收到相应的下行链路消息,终端设备将在接下来的32个数据包中启用ADR确认请求。在这种情况下,如果终端设备在92次上行链路传输后仍未收到下行链路消息,则会通过终端设备侧实现的自适应数据速率算法[14]增加扩频因子。
的城市环境中,非确认模式下的每小时包成功比率)
图5显示了在连续城市环境中自适应数据速率、自适应数据速率+和I‐ADR的平均数据包成功比率。两种情况下自适应数据速率和自适应数据速率+的下降趋势表明数据包丢失增加。随着终端设备数量从200增加到1000,网络服务器在自适应数据速率确认模式下需要更长时间才能从终端设备接收N个数据包以配置最优配置。当网络服务器计算出新的配置后,需通过网关使用MAC命令将此配置传达给终端设备。此外,由于网关存在1%占空比限制,在大规模网络中可能无法处理双向流量,从而导致入站数据包丢失和额外延迟。
图6显示了在城市环境中,从ADR、ADR+和I‐ADR方法中观察到的平均数据包丢失率。如[15]中所述,考虑了相同扩频因子和不同扩频因子传输的数据包在同一信道上的干扰。在ADR和ADR+中,随着M的增加,数据包丢失均呈上升趋势。最初,M个终端设备使用扩频因子12发送数据包,导致较高的空中传输时间(即当扩频因子为12且数据包大小为51字节时,空中传输时间为2.46秒)。由于空中传输时间较高,使用扩频因子12传输的数据包相互之间产生干扰。因此,高数据包丢失明显表明,由于空中传输时间较长,较高的扩频因子更容易受到干扰。此外,还表明扩频因子彼此之间并非完全正交[16],[17]。
另一方面,与ADR和ADR+相比,I‐ADR方案在CON‐urban和UNC‐urban两种情况下,由于在初始部署期间使用了不同的扩频因子,其数据包丢失率要低得多。此外,扩频因子之间并非完全正交,因此使用不同扩频因子发送的数据包可能会在短时间内相互产生干扰。如果经均衡后两个相互干扰的数据包各自的信号干扰噪声比高于阈值(如我们之前的工作[13]所示),则该数据包仍可被正确接收。因此,网络中的干扰影响显著降低。
4. 结论
LoRaWAN建议使用自适应数据速率(ADR),因为它通过精细调整扩频因子(SF)和发射功率(TP),实现了可靠、节能且高效的通信。由于ADR在时变信道条件下的性能较差,我们提出了一种名为I‐ADR的新算法,该算法在初始部署期间根据网关灵敏度为终端设备(EDs)分配扩频因子(SF)。通过仿真结果,我们表明所提出的方案通过降低干扰的影响,提高了包成功比率。特别是,我们验证了ADR需要较长的收敛时间,从而导致大量数据包丢失。此外,我们还观察到占空比限制和双向通信限制了LoRaWAN的可扩展性。未来,我们计划缩短ADR机制的收敛期。

















 5305
5305

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









