









 本文介绍了在寒武纪显卡上实现高维向量softmax运算的优化策略,包括基础编程、合并访存加速以及针对不同轴的并行优化方法。通过对数据访问模式的改进,提高处理大规模数组的效率,减少内存浪费,并通过实验对比展示优化效果。
本文介绍了在寒武纪显卡上实现高维向量softmax运算的优化策略,包括基础编程、合并访存加速以及针对不同轴的并行优化方法。通过对数据访问模式的改进,提高处理大规模数组的效率,减少内存浪费,并通过实验对比展示优化效果。
关于寒武纪编程可以参考本人之前的文章添加链接描述,添加链接描述,添加链接描述
高维向量softmax的基础编程
高维向量的softmax实现更加复杂,回忆之前在英伟达平台上实现高维向量的softmax函数,比如说我们以形状为[1,2,3,4,5,6]的6维向量举例,变换维度假设axis=2,之前英伟达平台的实现,我们计算出变换维度的长度dimsize=3,其他维度的乘积othersize=1×2×4×5×6 = 240,步长stride= 1×6×5×4 = 120,使用othersize=240个线程块,其中每个线程块处理对应一份数据,计算出int tid =blockIdx.x % stride + (blockIdx.x - blockIdx.x % stride) × dimsize;全局索引为tid + threadIdx.x × stride,类似地,我们也按照这个思路来实现寒武纪显卡上的高维向量softmax:
#include <bang.h>
#include <bang_device_functions.h>
#define EPS 1e-7
const int NRAM_MAX_SIZE = 1024 * 4;//后续树状求和必须保证NRAM_MAX_SIZE为2的幂次
const int maxNum = NRAM_MAX_SIZE/sizeof(float); //NRAM上最多存储maxNum个float元素
const int warpSize = 32;//__bang_reduce_sum每次从src取128字节数据相加,对应32个float元素,并且0-31的结果保存在索引0,32-63的结果保存在索引1
__nram__ float src1[maxNum];//每次搬运maxNum数据到NRAM
__nram__ float destSum[maxNum];//后面数值求和
__nram__ float destSumFinal[warpSize];//将destSum规约到destFinal[0]
__nram__ float srcMax[2];
__mlu_entry__ void softmaxKernel(float* dst, float* source1, int othersize, int dimsize, int stride) {
__nram__ float destOldMax;
__nram__ float destNewMax;
int liu = false;
if(liu){
for(int otherIdx = taskId; otherIdx < othersize; otherIdx += taskDim){
destOldMax = -INFINITY;
destNewMax = -INFINITY;
float sum_s = 1.0;
int tid = otherIdx % stride + (otherIdx - otherIdx % stride) * dimsize;
for(int i = 0; i < dimsize; i++){
__memcpy(src1, source1 + tid + i * stride, sizeof(float), GDRAM2NRAM);
if(destNewMax < src1[0]){
destNewMax = src1[0];
}
if(i > 0){
sum_s = sum_s * exp(destOldMax - destNewMax) + exp(src1[0] - destNewMax);
}
destOldMax = destNewMax;
}
float globalSumInv = 1.0/sum_s;;
for(int i = 0; i < dimsize; i++){
__memcpy(src1, source1 + tid + i * stride, sizeof(float), GDRAM2NRAM);
src1[0] = exp(src1[0] - destNewMax) * globalSumInv;
__memcpy(dst + tid + i * stride, src1, sizeof(float), NRAM2GDRAM);
}
}
}
else{
for(int otherIdx = taskId; otherIdx < othersize; otherIdx += taskDim){
destOldMax = -INFINITY;
destNewMax = -INFINITY;
float sum_s = 1.0;
int tid = otherIdx % stride + (otherIdx - otherIdx % stride) * dimsize;
for(int i = 0; i < dimsize + 1; i++){
if(i < dimsize){
__memcpy_async(src1 + i%2, source1 + tid + i * stride, sizeof(float), GDRAM2NRAM);
}
if(i > 0){
if(destNewMax < src1[(i - 1)%2]){
destNewMax = src1[(i - 1)%2];
}
if(i > 1){
sum_s = sum_s * exp(destOldMax - destNewMax) + exp(src1[(i - 1)%2] - destNewMax);
}
destOldMax = destNewMax;
}
__sync_all_ipu();
}
float globalSumInv = 1.0/sum_s;;
for(int i = 0; i < dimsize + 2; i++){
if(i < dimsize){
__memcpy(src1 + i%3, source1 + tid + i * stride, sizeof(float), GDRAM2NRAM);
}
if(i > 0 && i < dimsize + 1){
src1[(i - 1)%3] = exp(src1[(i - 1)%3] - destNewMax) * globalSumInv;
}
if(i > 1){
__memcpy(dst + tid + (i - 2) * stride, src1 + (i - 2)%3, sizeof(float), NRAM2GDRAM);
}
__sync_all_ipu();
}
}
}
}
int main(void)
{
int num = 32 * 16 * 64 * 128;//shape = {32, 16, 64, 128},axis = 2
int stride = 128;
int dimsize = 64;
int othersize = 32 * 16 * 128;
/***
int num = 24;//shape = {2,3,2,2}, axis = 1
int stride = 4;
int dimsize = 3;
int othersize = 8;
***/
cnrtQueue_t queue;
CNRT_CHECK(cnrtSetDevice(0));
CNRT_CHECK(cnrtQueueCreate(&queue));
cnrtDim3_t dim = {4, 1, 1};
int taskNum = dim.x * dim.y * dim.z;
cnrtFunctionType_t ktype = CNRT_FUNC_TYPE_UNION1;
cnrtNotifier_t start, end;
CNRT_CHECK(cnrtNotifierCreate(&start));
CNRT_CHECK(cnrtNotifierCreate(&end));
float* host_dst = (float*)malloc(num * sizeof(float));
float* host_src1 = (float*)malloc(num * sizeof(float));
for (int i = 0; i < num; i++) {
host_src1[i] = i%4;
//host_src1[i] = i;
}
float* mlu_dst;
float* mlu_src1;
CNRT_CHECK(cnrtMalloc((void**)&mlu_dst, num * sizeof(float)));
CNRT_CHECK(cnrtMalloc((void**)&mlu_src1, num * sizeof(float)));
CNRT_CHECK(cnrtMemcpy(mlu_src1, host_src1, num * sizeof(float), cnrtMemcpyHostToDev));
//----------------------------
CNRT_CHECK(cnrtPlaceNotifier(start, queue));
softmaxKernel<<<dim, ktype, queue>>>(mlu_dst, mlu_src1, othersize, dimsize, stride);
CNRT_CHECK(cnrtPlaceNotifier(end, queue));
cnrtQueueSync(queue);
//---------------------------
CNRT_CHECK(cnrtMemcpy(host_dst, mlu_dst, num * sizeof(float), cnrtMemcpyDevToHost));
for(int i = 0; i < 24; i++){
printf("softmax[%d]:%.6e,origin:%.6f\n", i, host_dst[i], host_src1[i]);
}
float timeTotal;
CNRT_CHECK(cnrtNotifierDuration(start, end, &timeTotal));
printf("Total Time: %.3f ms\n", timeTotal / 1000.0);
CNRT_CHECK(cnrtQueueDestroy(queue));
cnrtFree(mlu_dst);
cnrtFree(mlu_src1);
free(host_dst);
free(host_src1);
return 0;
}
我们利用taskId来处理othersize,但是考虑到taskDim往往是2或者4的倍数,而othersize不一定满足这个条件,因此我们使用for循环来解决,参考for(int otherIdx = taskId; otherIdx < othersize; otherIdx += taskDim)
进入上述for循环以后,我们尝试来处理dimsize,由于寒武纪的函数基本上支持向量操作,无法针对具体某个元素来处理,为此我们仍然把dimsize这份数据按照maxNum长度分成多个小单元,如果不能整除后面特殊处理,特殊处理的方式和上面一维向量一模一样。在代码24行——25行,这里使用两层for循环来加载数据,高维数组导致每次处理的数据不连续,间隔stride,为此必须要不断遍历数组把结果集中到src1数组上处理,后续的处理类似,这里不做赘述。
#include <bang.h>
#include <bang_device_functions.h>
#define EPS 1e-7
const int NRAM_MAX_SIZE = 1024 * 4;//后续树状求和必须保证NRAM_MAX_SIZE为2的幂次
const int maxNum = NRAM_MAX_SIZE/sizeof(float); //NRAM上最多存储maxNum个float元素
const int warpSize = 32;//__bang_reduce_sum每次从src取128字节数据相加,对应32个float元素,并且0-31的结果保存在索引0,32-63的结果保存在索引1
__nram__ float src1[maxNum];//每次搬运maxNum数据到NRAM
__nram__ float destSum[maxNum];//后面数值求和
__nram__ float destSumFinal[warpSize];//将destSum规约到destFinal[0]
__nram__ float srcMax[2];
__mlu_entry__ void softmaxKernel(float* dst, float* source1, int othersize, int dimsize, int stride) {
int remain = dimsize%maxNum;
int repeat = (dimsize - remain)/maxNum;
__nram__ float destOldMax;
__nram__ float destNewMax;
//下面利用taskId来处理其他维度
for(int otherIdx = taskId; otherIdx < othersize; otherIdx += taskDim){
destOldMax = -INFINITY;
destNewMax = -INFINITY;
__bang_write_zero(destSum, maxNum);
int tid = otherIdx % stride + (otherIdx - otherIdx % stride) * dimsize;
for(int i = 0; i < repeat; i++){
for(int j = 0; j < maxNum; j++){//从source1间隔stride读取数据
__memcpy(src1 + j, source1 + tid + (i * maxNum + j) * stride, sizeof(float), GDRAM2NRAM);
}
__bang_argmax(srcMax, src1, maxNum);
if(destNewMax < srcMax[0]){
destNewMax = srcMax[0];//更新最大值
}
__bang_sub_scalar(src1, src1, destNewMax, maxNum);//src1 = src1 - 最大值
__bang_active_exp_less_0(src1, src1, maxNum);//src1 = exp(src1 - 最大值)
if(i > 0){
__bang_mul_scalar(destSum, destSum, exp(destOldMax - destNewMax), maxNum);
}
__bang_add(destSum, destSum, src1, maxNum);//destSum = destSum + exp(src1 - destNewMax)
destOldMax = destNewMax;
}
//-------------------------------------
if(remain){
__bang_write_value(src1, maxNum, -INFINITY);//多余部分必须设置负无穷
for(int j = 0; j < remain; j++){
__memcpy(src1 + j, source1 + tid + (repeat * maxNum + j) * stride, sizeof(float), GDRAM2NRAM);
}
__bang_argmax(srcMax, src1, maxNum);
if(destNewMax < srcMax[0]){
destNewMax = srcMax[0];
}
__bang_write_value(src1, maxNum, destNewMax);//必须重新初始化为destNewMax
for(int j = 0; j < remain; j++){
__memcpy(src1 + j, source1 + tid + (repeat * maxNum + j) * stride, sizeof(float), GDRAM2NRAM);
}
__bang_sub_scalar(src1, src1, destNewMax, maxNum);//后面maxNum-remain部分为0
__bang_active_exp_less_0(src1, src1, maxNum);//相当于多加了maxNum-remain
if(repeat > 0){
__bang_mul_scalar(destSum, destSum, exp(destOldMax - destNewMax), maxNum);
}
__bang_add(destSum, destSum, src1, maxNum);
destOldMax = destNewMax;
}
//--------------------------------
__bang_write_zero(destSumFinal, warpSize);
int segNum = maxNum / warpSize;
for(int strip = segNum/2; strip > 0; strip = strip / 2){
for(int i = 0; i < strip ; i++){
__bang_add(destSum + i * warpSize, destSum + i * warpSize, destSum + (i + strip) * warpSize, warpSize);
}
}
__bang_reduce_sum(destSumFinal, destSum, warpSize);
if(remain){
destSumFinal[0] = destSumFinal[0] - (maxNum - remain);
}
//__bang_printf("--max:%.3e,sum:%.6e,:%d\n",destNewMax,destSumFinal[0], maxNum - remain);
//------------------------------------至此全局最大值为destNewMax,全局数值和为destSumFinal[0]
float globalSumInv = 1.0/destSumFinal[0];
if(remain){
__bang_mul_scalar(src1, src1, globalSumInv, maxNum);//倒数和另一个向量逐元素相乘得到除法结果
for(int j = 0; j < remain; j++){
__memcpy(dst + tid + (repeat * maxNum + j) * stride, src1 + j, sizeof(float), NRAM2GDRAM);
}
}
for(int i = 0; i < repeat; i++){
for(int j = 0; j < maxNum; j++){
__memcpy(src1 + j, source1 + tid + (i * maxNum + j) * stride, sizeof(float), GDRAM2NRAM);
}
__bang_sub_scalar(src1, src1, destNewMax, maxNum);
__bang_active_exp_less_0(src1, src1, maxNum);
__bang_mul_scalar(src1, src1, globalSumInv, maxNum);//倒数和另一个向量逐元素相乘得到除法结果
for(int j = 0; j < maxNum; j++){
__memcpy(dst + tid + (i * maxNum + j) * stride, src1 + j, sizeof(float), NRAM2GDRAM);
}
}
}
}
int main(void)
{
int num = 32 * 16 * 64 * 128;//shape = {32, 16, 64, 128},axis = 2
int stride = 128;
int dimsize = 64;
int othersize = 32 * 16 * 128;
/***
int num = 24;//shape = {2,3,2,2}, axis = 1
int stride = 4;
int dimsize = 3;
int othersize = 8;
***/
cnrtQueue_t queue;
CNRT_CHECK(cnrtSetDevice(0));
CNRT_CHECK(cnrtQueueCreate(&queue));
cnrtDim3_t dim = {4, 1, 1};
int taskNum = dim.x * dim.y * dim.z;
cnrtFunctionType_t ktype = CNRT_FUNC_TYPE_UNION1;
cnrtNotifier_t start, end;
CNRT_CHECK(cnrtNotifierCreate(&start));
CNRT_CHECK(cnrtNotifierCreate(&end));
float* host_dst = (float*)malloc(num * sizeof(float));
float* host_src1 = (float*)malloc(num * sizeof(float));
for (int i = 0; i < num; i++) {
host_src1[i] = i%4;
//host_src1[i] = i;
}
float* mlu_dst;
float* mlu_src1;
CNRT_CHECK(cnrtMalloc((void**)&mlu_dst, num * sizeof(float)));
CNRT_CHECK(cnrtMalloc((void**)&mlu_src1, num * sizeof(float)));
CNRT_CHECK(cnrtMemcpy(mlu_src1, host_src1, num * sizeof(float), cnrtMemcpyHostToDev));
//----------------------------
CNRT_CHECK(cnrtPlaceNotifier(start, queue));
softmaxKernel<<<dim, ktype, queue>>>(mlu_dst, mlu_src1, othersize, dimsize, stride);
CNRT_CHECK(cnrtPlaceNotifier(end, queue));
cnrtQueueSync(queue);
//---------------------------
CNRT_CHECK(cnrtMemcpy(host_dst, mlu_dst, num * sizeof(float), cnrtMemcpyDevToHost));
for(int i = 0; i < 24; i++){
printf("softmax[%d]:%.6e,origin:%.6f\n", i, host_dst[i], host_src1[i]);
}
float timeTotal;
CNRT_CHECK(cnrtNotifierDuration(start, end, &timeTotal));
printf("Total Time: %.3f ms\n", timeTotal / 1000.0);
CNRT_CHECK(cnrtQueueDestroy(queue));
cnrtFree(mlu_dst);
cnrtFree(mlu_src1);
free(host_dst);
free(host_src1);
return 0;
}
高维向量softmax的合并访存加速
上面提到的就是最简单最容易想到的编程手段了,上面的方案有一个问题,即数组元素的访问读取都是跳跃的,因此时间特别长,根本无法用于处理大规模数组,为了加速,下面我们尝试在原始方案上做优化。为了方便描述,我们以形状为[32,16,64,128]这样一个四维向量举例,其中softmax的操作维度假设axis=2,那么就可以计算出stride=128,dimsize=64,othersize=32×16×128。上面算法的特点是,利用不同taskId处理othersize得到对应的otherIdx,然后针对dimsize做循环,得到全局的index为otherIdx + i×stride,最终不断跳跃stride来获取数组对应元素,把结果集中到一个长度为maxNum的NRAM向量src里面,经过一系列变换以后通过for循环把src的元素写回目标向量dst中,这个过程最耗时的地方就在于数组的跳跃访问,为了解决这个问题,我们尝试一种合并访存的方式来读取数组,我们以4维向量举例子,其中假设向量的形状为[A,B,C,D],下面需要针对softmax的操作维度axis进行分类讨论,全局索引为i(BCD) + j(CD) + k(D) + s,具体想法如下:
axis=0
我们知道 j(CD) + k(D) + s对应的othersize刚好就是BCD,而stride正好也是BCD,为此我们可以这样读取数据,把向量分成A个单元,其中每个单元的长度为BCD,考虑for循环如下:for(i = 0; i < A; i++),循环体内每次读取source[i×(BCD):(i+1)×BCD]这部分数据,我们发现这样做可以得到A个长度为BCD的向量,而且每个向量对应元素的索引差别就是stride,因此我们完全可以把这A个向量存储起来,逐个元素比较最大值M,最终得到一个长度为BCD的向量tmpMax,其中tmpMax当中的每个元素正好就是不同(j,k,s)对应的最大值,类似的可以这样求出数值和以及把数据写回GDRAM。
下面这个bang_maxequal可以完成对应元素比较最大值,另外关于对应元素求和的函数直接使用bang_add即可。
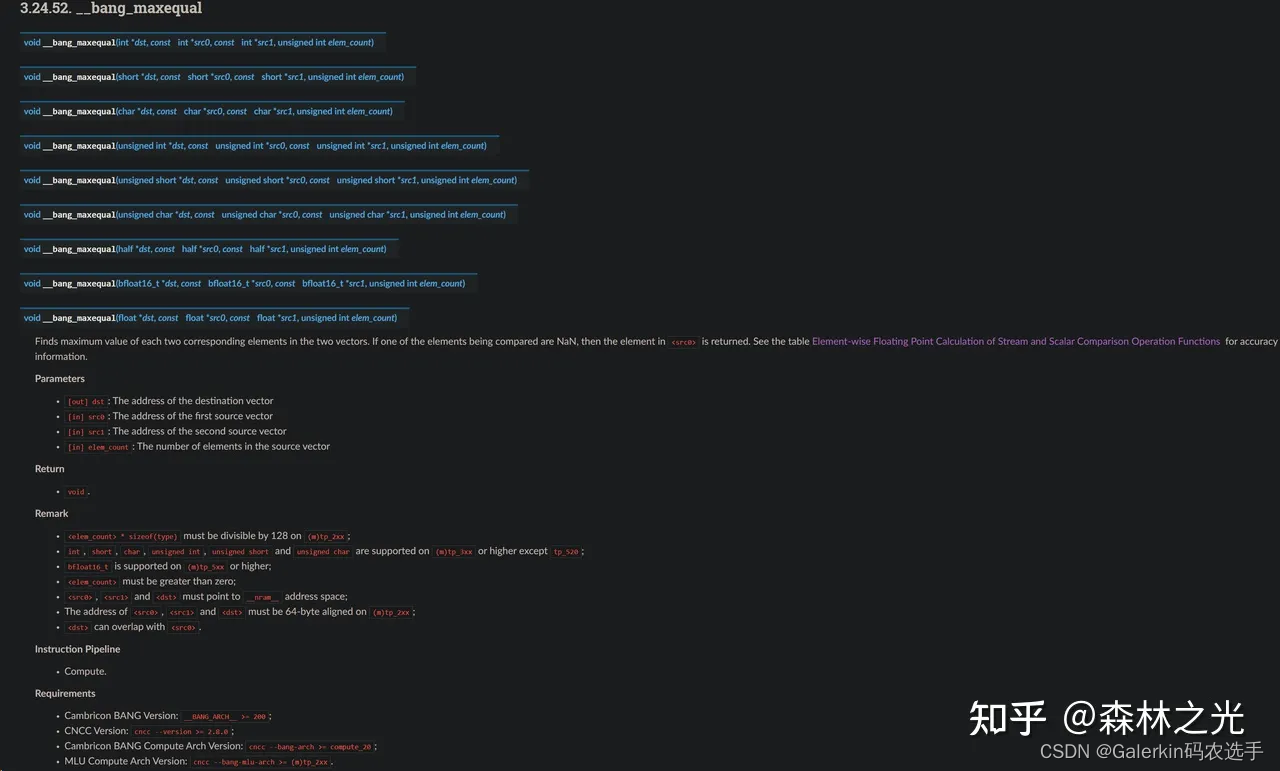
在这种情况下,taskId用于处理othersize这部分,主要原因在于此时读取数据的时候,只有othersize这部分数据恰好是连续的。
#include <bang.h>
#include <bang_device_functions.h>
#define EPS 1e-7
const int NRAM_MAX_SIZE = 1024 * 128;//后续树状求和必须保证NRAM_MAX_SIZE为2的幂次
const int maxNum = NRAM_MAX_SIZE/sizeof(float); //NRAM上最多存储maxNum个float元素
__mlu_entry__ void softmaxKernelAxis_s(float* destination, float* source, int othersize, int dimsize, int stride) {// axis = 0
__nram__ float src[maxNum];//每次搬运maxNum数据到NRAM
__nram__ float tmpSum[maxNum];
__nram__ float tmpNewMax[maxNum];
__nram__ float tmpOldMax[maxNum];
int remain = othersize % taskDim;
int stepEasy = (othersize - remain)/taskDim;
int stepHard = stepEasy + 1;
int step = (taskId < remain ? stepHard : stepEasy);//前部分taskId多处理一个元素
int indStart = (taskId < remain ? taskId * stepHard : remain * stepHard + (taskId - remain) * stepEasy);
int remainNram = step%maxNum;
int repeat = (step - remainNram)/maxNum;
__bang_printf("taskId:%d, repeat:%d, step:%d, indStart:%d, remainNram:%d\n", taskId, repeat, step, indStart, remainNram);
for(int j = 0; j < repeat; j++){
__bang_write_value(tmpNewMax, maxNum, -INFINITY);
__bang_write_zero(tmpSum, maxNum);
for(int i = 0; i < dimsize; i++){
__memcpy(src, source + i * stride + indStart + j * maxNum, maxNum * sizeof(float), GDRAM2NRAM);
__bang_maxequal(tmpNewMax, tmpNewMax, src, maxNum);//不断更新最大值
__bang_sub(src, src, tmpNewMax, maxNum);//x - M
__bang_active_exp_less_0(src, src, maxNum);//exp(x - M)
if(i > 0){
__bang_sub(tmpOldMax, tmpOldMax, tmpNewMax, maxNum);//oldM = oldM - newM
__bang_active_exp_less_0(tmpOldMax, tmpOldMax, maxNum);//exp(oldM - newM)
__bang_mul(tmpSum, tmpSum, tmpOldMax, maxNum);//sum = sum * exp(oldM - newM)
}
__bang_add(tmpSum, tmpSum, src, maxNum);//sum += exp(x - M)
__memcpy(tmpOldMax, tmpNewMax, maxNum * sizeof(float), NRAM2NRAM);//oldM = newM
}
__bang_active_recip(tmpSum, tmpSum, maxNum);//计算1/sum
//开始指数变换并且写回GDRAM
__bang_mul(src, src, tmpSum, maxNum);//上面循环结束src存储的数据可以利用
__memcpy(destination + (dimsize - 1) * stride + indStart + j * maxNum, src, maxNum * sizeof(float), NRAM2GDRAM);
for(int i = 0; i < dimsize - 1; i++){
__memcpy(src, source + i * stride + indStart + j * maxNum, maxNum * sizeof(float), GDRAM2NRAM);
__bang_sub(src, src, tmpNewMax, maxNum);//x - M
__bang_active_exp_less_0(src, src, maxNum);//exp(x - M)
__bang_mul(src, src, tmpSum, maxNum);
__memcpy(destination + i * stride + indStart + j * maxNum, src, maxNum * sizeof(float), NRAM2GDRAM);
}
}
if(remainNram){
__bang_write_value(tmpNewMax, maxNum, -INFINITY);
__bang_write_zero(tmpSum, maxNum);
__bang_write_zero(src, maxNum);
for(int i = 0; i < dimsize; i++){
__memcpy(src, source + i * stride + indStart + repeat * maxNum, remainNram * sizeof(float), GDRAM2NRAM);
__bang_maxequal(tmpNewMax, tmpNewMax, src, maxNum);
__bang_sub(src, src, tmpNewMax, maxNum);//x - M
__bang_active_exp_less_0(src, src, maxNum);//exp(x - M)
if(i > 0){
__bang_sub(tmpOldMax, tmpOldMax, tmpNewMax, maxNum);//oldM = oldM - newM
__bang_active_exp_less_0(tmpOldMax, tmpOldMax, maxNum);//exp(oldM - newM)
__bang_mul(tmpSum, tmpSum, tmpOldMax, maxNum); //sum = sum * exp(oldM - newM)
}
__bang_add(tmpSum, tmpSum, src, maxNum);//sum += exp(x - M)
__memcpy(tmpOldMax, tmpNewMax, maxNum * sizeof(float), NRAM2NRAM);//oldM = newM
}
/***
for(int k = 0; k < remainNram; k++){
__bang_printf("%d,max:%.2f,sum:%.2f, src:%.2f\n",k, tmpNewMax[k], tmpSum[k], src[k]);
}
***/
__bang_active_recip(tmpSum, tmpSum, maxNum);//计算1/sum
//开始指数变换并且写回GDRAM
__bang_mul(src, src, tmpSum, maxNum);//上面循环结束src存储的数据可以利用
__memcpy(destination + (dimsize - 1) * stride + indStart + repeat * maxNum, src, remainNram * sizeof(float), NRAM2GDRAM);
for(int i = 0; i < dimsize - 1; i++){
__memcpy(src, source + i * stride + indStart + repeat * maxNum, remainNram * sizeof(float), GDRAM2NRAM);
__bang_sub(src, src, tmpNewMax, maxNum);//x - M
__bang_active_exp_less_0(src, src, maxNum);//exp(x - M)
__bang_mul(src, src, tmpSum, maxNum);
__memcpy(destination + i * stride + indStart + repeat * maxNum, src, remainNram * sizeof(float), NRAM2GDRAM);
}
}
}
int main(void)
{
//int shape[4] = {1024,128,32,32};
//int shape[4] = {1024,64,32,32};
int shape[4] = {1024,32,32,32};
//int shape[4] = {2, 3, 2, 2};
int axis = 0;
int stride = 1;
int dimsize = shape[axis];
int num = 1;
int othersize = 1;
for(int s = 3; s >= 0; s--){
num *= shape[s];
if(s > axis){
stride *= shape[s];
}
if(s != axis){
othersize *= shape[s];
}
}
printf("axis:%d, dimsize:%d, stride:%d, othersize:%d, num:%d\n", axis, dimsize, stride, othersize, num);
cnrtQueue_t queue;
CNRT_CHECK(cnrtSetDevice(0));
CNRT_CHECK(cnrtQueueCreate(&queue));
cnrtDim3_t dim = {4, 1, 1};
int taskNum = dim.x * dim.y * dim.z;
cnrtFunctionType_t ktype = CNRT_FUNC_TYPE_UNION1;
cnrtNotifier_t start, end;
CNRT_CHECK(cnrtNotifierCreate(&start));
CNRT_CHECK(cnrtNotifierCreate(&end));
float* host_destination = (float*)malloc(num * sizeof(float));
float* host_src = (float*)malloc(num * sizeof(float));
for (int i = 0; i < num; i++) {
host_src[i] = i%4;
//host_src[i] = i;
}
float* mlu_destination;
float* mlu_src;
CNRT_CHECK(cnrtMalloc((void**)&mlu_destination, num * sizeof(float)));
CNRT_CHECK(cnrtMalloc((void**)&mlu_src, num * sizeof(float)));
CNRT_CHECK(cnrtMemcpy(mlu_src, host_src, num * sizeof(float), cnrtMemcpyHostToDev));
//----------------------------
CNRT_CHECK(cnrtPlaceNotifier(start, queue));
softmaxKernelAxis_s<<<dim, ktype, queue>>>(mlu_destination, mlu_src, othersize, dimsize, stride);
CNRT_CHECK(cnrtPlaceNotifier(end, queue));
cnrtQueueSync(queue);
//---------------------------
CNRT_CHECK(cnrtMemcpy(host_destination, mlu_destination, num * sizeof(float), cnrtMemcpyDevToHost));
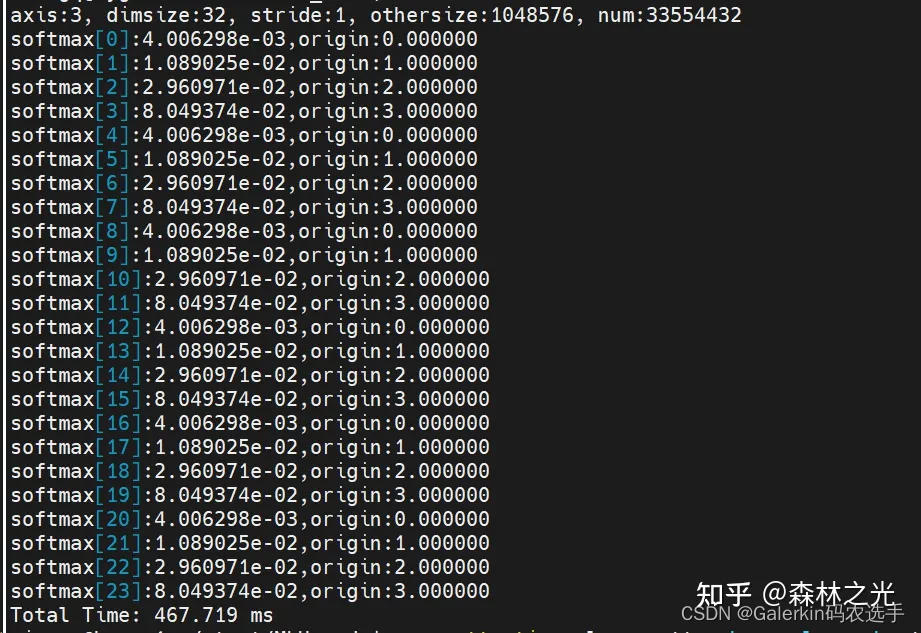
for(int i = 0; i < 24; i++){
printf("softmax[%d]:%.6e,origin:%.6f\n", i, host_destination[i], host_src[i]);
}
float timeTotal;
CNRT_CHECK(cnrtNotifierDuration(start, end, &timeTotal));
printf("Total Time: %.3f ms\n", timeTotal / 1000.0);
CNRT_CHECK(cnrtQueueDestroy(queue));
cnrtFree(mlu_destination);
cnrtFree(mlu_src);
free(host_destination);
free(host_src);
return 0;
}
axis = -1
此时softmax操作维度正好是最后一个,这个时候就更加简单了,把向量分成ABC个单元,每个单元长度为D,考虑这样一个for循环:for(i = 0; i < ABC; i++),每轮循环读取source[i×(D):(i+1)×D]这份数据,针对这部分数据做规约获得最大值M,经过这个循环以后就可以得到不同(i,j,k)对应的最大值,对应的也就是othersize这部分数据对应的最大值,类似的可以得到数值和以及把数据写回GDRAM。在这种情况下,数据在axis=-1这个轴连续,此时并行策略有两种:
第一种策略:用taskId处理othersize,具体做法可以是for(i=taskId; i < ABC; i += taskDim),然后每轮循环内部读取对应的长度为D的数据,但是此时D不一定是2的幂次方,而且NRAM上也不一定能一次放下长度为D的向量,所以这个时候在循环内部,还需要额外针对source[i×(D):(i+1)×D]多做一个循环,每次循环读取maxNum个元素,直到数据读取结束。
第二种并行策略:串行处理othersize,for(i = 0; i < ABC; i++),在循环内部针对source[i×(D):(i+1)×D]这份数据分配给不同的taskId,这种做法导致每个taskId分到的数据是source[i×(D):(i+1)×D]一部分,在我们之前代码里面就是step,并且step也不一定是2的幂次方,也不一定能够在NRAM上放下,而且我们需要的最大值是source[i×(D):(i+1)×D]这部分数据的最大值,如果把这部分数据切分到不同taskId,最后算完以后还得额外针对不同taskId做一个规约(和上面的一维向量一模一样)。
经过上面两种分析,我们倾向于采取第一种策略。另外如果使用for(i=taskId; i < ABC; i += taskDim),站在taskId的角度来看,每次循环读取数据都是跳跃的。如果我们提前设定好step,让不同taskId处理的索引在[taskId×step:(taskId+1)×step]这个区间,此时站在taskId的角度来说,每次循环读取的数据会相对连续(但是需要实验结果来验证)。不过为了方便起见,我们还是使用for(i=taskId; i < ABC; i += taskDim)这种循环模式来计算结果。
#include <bang.h>
#include <bang_device_functions.h>
#define EPS 1e-7
const int NRAM_MAX_SIZE = 1024 * 128;//后续树状求和必须保证NRAM_MAX_SIZE为2的幂次
const int maxNum = NRAM_MAX_SIZE/sizeof(float); //NRAM上最多存储maxNum个float元素
const int warpSize = 32;
__mlu_entry__ void softmaxKernelAxis_e(float* destination, float* source, int othersize, int dimsize) {// axis = -1
__nram__ float src[maxNum];
__nram__ float destSum[maxNum];//后面数值求和
__nram__ float destSumFinal[warpSize];//将destSum规约到destFinal[0]
__nram__ float srcMax[2];
__nram__ float destOldMax;
__nram__ float destNewMax;
int remain = dimsize % maxNum;
int repeat = (dimsize - remain)/maxNum;
for(int otherIdx = taskId; otherIdx < othersize; otherIdx += taskDim){
int tid = otherIdx * dimsize;
destOldMax = -INFINITY;
destNewMax = -INFINITY;
__bang_write_zero(destSum, maxNum);
for(int i = 0; i < repeat; i++){
__memcpy(src, source + tid + i * maxNum, maxNum * sizeof(float), GDRAM2NRAM);
__bang_argmax(srcMax, src, maxNum);
if(destNewMax < srcMax[0]){
destNewMax = srcMax[0];//更新最大值
}
__bang_sub_scalar(src, src, destNewMax, maxNum);//src = src - 最大值
__bang_active_exp_less_0(src, src, maxNum);//src = exp(src - 最大值)
if(i > 0){
__bang_mul_scalar(destSum, destSum, exp(destOldMax - destNewMax), maxNum);
}
__bang_add(destSum, destSum, src, maxNum);
destOldMax = destNewMax;
}
//------------
if(remain){
__bang_write_value(src, maxNum, -INFINITY);//多余部分必须设置负无穷
__memcpy(src, source + tid + repeat * maxNum, remain * sizeof(float), GDRAM2NRAM);
__bang_argmax(srcMax, src, maxNum);
if(destNewMax < srcMax[0]){
destNewMax = srcMax[0];
}
__bang_write_value(src, maxNum, destNewMax);//必须重新初始化为destNewMax
__memcpy(src, source + tid + repeat * maxNum, remain * sizeof(float), GDRAM2NRAM);
__bang_sub_scalar(src, src, destNewMax, maxNum);//后面maxNum-remain部分为0
__bang_active_exp_less_0(src, src, maxNum);//相当于多加了maxNum-remain
if(repeat > 0){
__bang_mul_scalar(destSum, destSum, exp(destOldMax - destNewMax), maxNum);
}
__bang_add(destSum, destSum, src, maxNum);
destOldMax = destNewMax;
}
//--------------
//--------------------------------
__bang_write_zero(destSumFinal, warpSize);
int segNum = maxNum / warpSize;
for(int strip = segNum/2; strip > 0; strip = strip / 2){
for(int i = 0; i < strip ; i++){
__bang_add(destSum + i * warpSize, destSum + i * warpSize, destSum + (i + strip) * warpSize, warpSize);
}
}
__bang_reduce_sum(destSumFinal, destSum, warpSize);
if(remain){
destSumFinal[0] = destSumFinal[0] - (maxNum - remain);
}
//-----------
float globalSumInv = 1.0/destSumFinal[0];
for(int i = 0; i < repeat; i++){
__memcpy(src, source + tid + i * maxNum, maxNum * sizeof(float), GDRAM2NRAM);
__bang_sub_scalar(src, src, destNewMax, maxNum);
__bang_active_exp_less_0(src, src, maxNum);
__bang_mul_scalar(src, src, globalSumInv, maxNum);//倒数和另一个向量逐元素相乘得到除法结果
__memcpy(destination + tid + i * maxNum, src, maxNum * sizeof(float), NRAM2GDRAM);
}
if(remain){
__bang_write_value(src, maxNum, destNewMax);
__memcpy(src, source + tid + repeat * maxNum, remain * sizeof(float), GDRAM2NRAM);
__bang_sub_scalar(src, src, destNewMax, maxNum);
__bang_active_exp_less_0(src, src, maxNum);
__bang_mul_scalar(src, src, globalSumInv, maxNum);//倒数和另一个向量逐元素相乘得到除法结果
__memcpy(destination + tid + repeat * maxNum, src, remain * sizeof(float), NRAM2GDRAM);
}
}
}
int main(void)
{
//int shape[4] = {1024,128,32,32};
//int shape[4] = {1024,64,32,32};
int shape[4] = {1024,32,32,32};
//int shape[4] = {2, 3, 2, 2};
int axis = 3;
int stride = 1;
int dimsize = shape[axis];
int num = 1;
int othersize = 1;
for(int s = 3; s >= 0; s--){
num *= shape[s];
if(s > axis){
stride *= shape[s];
}
if(s != axis){
othersize *= shape[s];
}
}
printf("axis:%d, dimsize:%d, stride:%d, othersize:%d, num:%d\n", axis, dimsize, stride, othersize, num);
cnrtQueue_t queue;
CNRT_CHECK(cnrtSetDevice(0));
CNRT_CHECK(cnrtQueueCreate(&queue));
cnrtDim3_t dim = {4, 1, 1};
int taskNum = dim.x * dim.y * dim.z;
cnrtFunctionType_t ktype = CNRT_FUNC_TYPE_UNION1;
cnrtNotifier_t start, end;
CNRT_CHECK(cnrtNotifierCreate(&start));
CNRT_CHECK(cnrtNotifierCreate(&end));
float* host_destination = (float*)malloc(num * sizeof(float));
float* host_src = (float*)malloc(num * sizeof(float));
for (int i = 0; i < num; i++) {
//host_src[i] = i%4;
host_src[i] = i;
}
float* mlu_destination;
float* mlu_src;
CNRT_CHECK(cnrtMalloc((void**)&mlu_destination, num * sizeof(float)));
CNRT_CHECK(cnrtMalloc((void**)&mlu_src, num * sizeof(float)));
CNRT_CHECK(cnrtMemcpy(mlu_src, host_src, num * sizeof(float), cnrtMemcpyHostToDev));
//----------------------------
CNRT_CHECK(cnrtPlaceNotifier(start, queue));
softmaxKernelAxis_e<<<dim, ktype, queue>>>(mlu_destination, mlu_src, othersize, dimsize);
CNRT_CHECK(cnrtPlaceNotifier(end, queue));
cnrtQueueSync(queue);
//---------------------------
CNRT_CHECK(cnrtMemcpy(host_destination, mlu_destination, num * sizeof(float), cnrtMemcpyDevToHost));
for(int i = 0; i < 24; i++){
printf("softmax[%d]:%.6e,origin:%.6f\n", i, host_destination[i], host_src[i]);
}
float timeTotal;
CNRT_CHECK(cnrtNotifierDuration(start, end, &timeTotal));
printf("Total Time: %.3f ms\n", timeTotal / 1000.0);
CNRT_CHECK(cnrtQueueDestroy(queue));
cnrtFree(mlu_destination);
cnrtFree(mlu_src);
free(host_destination);
free(host_src);
return 0;
}
0 < axis < dimsize - 1
假设dim表示向所属空间的维度,此时最为复杂,结合上面axis=0和axis=-1的分析,这里我们这样考虑0 < axis < dim - 1,为了方便叙述,我们分别以axis=1和axis=2来解释数据读取的做法:
axis=1,对于[A,B,C,D]这样的向量来说,我们设置otherIdx=i(BCD)和循环for(j = 0; j < B; j++),其中每轮循环读取长度为CD的数据source[otherIdx + j×stride:otherIdx + j×stride + CD],此时我们发现对于固定的otherIdx来说,经过for循环以后会得到dimsize=B个长度为CD的向量,并且我们逐个元素比较最大值最终可以得到一个长度为CD的向量tmpMax,其中tmpMax保存的是对于固定otherIdx下对应于(k,s)的最大值,类似的可以得到数值和以及写回数据。
axis=2,我们设置otherIdx=i(BCD) + j(CD)和循环for(k = 0; k < C; k++),其中每轮循环读取长度为D的数据source[otherIdx + k×stride:otherIdx + k×stride + D],此时我们发现对于固定的otherIdx来说,经过for循环以后会得到dimsize=C个长度为D的向量,并且我们逐个元素比较最大值最终可以得到一个长度为D的向量tmpMax,其中tmpMax保存的是对于固定otherIdx下对应于(s)的最大值,类似的可以得到数值和以及写回数据。
我们可以得到规律,如果axis是中间维度,那么我们需要固定axis之前的otherIdx,然后设置对应的for循环,每轮循环读取axis之后的数据即可。我们设置两个参数frontsize和behindsize分别表示axis前面和后面的数据,比如说axis=1,frontsize=A,behindsize=CD,如果axis=2,那么frontsize=AB,behindsize=D。
这种时候我们需要考虑taskId到底用来处理frontsize还是behindsize,两种想法都可以,下面我们来分析一下两种不同的策略,我们以axis=2来举例说明:
第一种:taskId处理frontsize,即for(ind = taskId; ind < frontsize; ind += taskDim),由于axis=2,此时我们知道frontsize=AB,ind对应的二维索引(i,j)有对应关系ind=iB + j,但是我们需要对ind进一步做一个转换得到frontIdx = ind×CD,更加一般的情况是frontIdx = ind×dimsize×behindsize。进入这个循环以后继续for(k = 0; k < C; k++),此时开始一次读取behindsize个数据。
第二种:taskId处理behindsize,此时对于frontsize只能串行处理了,即for(ind = 0; ind < frontsize; ind += 1),由于axis=2,frontIdx = ind×CD,更加一般的情况是frontIdx = ind×dimsize×behindsize。进入这个循环以后继续for(k = 0; k < C; k++),此时由于taskId处理的是behindsize,那么不同taskId分配的数据量是step,开始一次读取step个数据。
粗糙的观察,我们倾向于选择第一种策略,另外我们注意到,其实behindsize就是stride,为此后面我们不区分两者。
策略1:
#include <bang.h>
#include <bang_device_functions.h>
#define EPS 1e-7
const int NRAM_MAX_SIZE = 1024 * 128;//后续树状求和必须保证NRAM_MAX_SIZE为2的幂次
const int maxNum = NRAM_MAX_SIZE/sizeof(float); //NRAM上最多存储maxNum个float元素
__mlu_entry__ void softmaxKernelAxis_m(float* destination, float* source, int frontsize, int dimsize, int stride) {
// 0<axis<dim -1
__nram__ float src[maxNum];
__nram__ float tmpSum[maxNum];
__nram__ float tmpNewMax[maxNum];
__nram__ float tmpOldMax[maxNum];
int remain = stride % maxNum;
int repeat = (stride - remain) / maxNum;
for(int ind = taskId; ind < frontsize; ind += taskDim){
int frontIdx = ind * dimsize * stride;
for(int j = 0; j < repeat; j++){
__bang_write_value(tmpNewMax, maxNum, -INFINITY);
__bang_write_zero(tmpSum, maxNum);
__bang_write_zero(src, maxNum);
for(int i = 0; i < dimsize; i++){
__memcpy(src, source + frontIdx + i * stride + j * maxNum, maxNum * sizeof(float), GDRAM2NRAM);
__bang_maxequal(tmpNewMax, tmpNewMax, src, maxNum);//不断更新最大值
__bang_sub(src, src, tmpNewMax, maxNum);//x - M
__bang_active_exp_less_0(src, src, maxNum);//exp(x - M)
if(i > 0){
__bang_sub(tmpOldMax, tmpOldMax, tmpNewMax, maxNum);//oldM = oldM - newM
__bang_active_exp_less_0(tmpOldMax, tmpOldMax, maxNum);//exp(oldM - newM)
__bang_mul(tmpSum, tmpSum, tmpOldMax, maxNum);//sum = sum * exp(oldM - newM)
}
__bang_add(tmpSum, tmpSum, src, maxNum);//sum += exp(x - M)
__memcpy(tmpOldMax, tmpNewMax, maxNum * sizeof(float), NRAM2NRAM);//oldM = newM
}
__bang_active_recip(tmpSum, tmpSum, maxNum);//计算1/sum
//开始指数变换并且写回GDRAM
__bang_mul(src, src, tmpSum, maxNum);//上面循环结束src存储的数据可以利用
__memcpy(destination + (dimsize - 1) * stride + frontIdx + j * maxNum, src, maxNum * sizeof(float), NRAM2GDRAM);
for(int i = 0; i < dimsize - 1; i++){
__memcpy(src, source + frontIdx + i * stride + j * maxNum, maxNum * sizeof(float), GDRAM2NRAM);
__bang_sub(src, src, tmpNewMax, maxNum);//x - M
__bang_active_exp_less_0(src, src, maxNum);//exp(x - M)
__bang_mul(src, src, tmpSum, maxNum);
__memcpy(destination + frontIdx + i * stride + j * maxNum, src, maxNum * sizeof(float), NRAM2GDRAM);
}
}
if(remain){
__bang_write_value(tmpNewMax, maxNum, -INFINITY);
__bang_write_zero(tmpSum, maxNum);
__bang_write_value(src, maxNum, -INFINITY);
for(int i = 0; i < dimsize; i++){
__memcpy(src, source + frontIdx + i * stride + repeat * maxNum, remain * sizeof(float), GDRAM2NRAM);
__bang_maxequal(tmpNewMax, tmpNewMax, src, maxNum);
__bang_sub(src, src, tmpNewMax, maxNum);//x - M
__bang_active_exp_less_0(src, src, maxNum);//exp(x - M)
if(i > 0){
__bang_sub(tmpOldMax, tmpOldMax, tmpNewMax, maxNum);//oldM = oldM - newM
__bang_active_exp_less_0(tmpOldMax, tmpOldMax, maxNum);//exp(oldM - newM)
__bang_mul(tmpSum, tmpSum, tmpOldMax, maxNum); //sum = sum * exp(oldM - newM)
}
__bang_add(tmpSum, tmpSum, src, maxNum);//sum += exp(x - M)
__memcpy(tmpOldMax, tmpNewMax, maxNum * sizeof(float), NRAM2NRAM);//oldM = newM
}
//-------------------
__bang_active_recip(tmpSum, tmpSum, maxNum);//计算1/sum
//开始指数变换并且写回GDRAM
__bang_mul(src, src, tmpSum, maxNum);//上面循环结束src存储的数据可以利用
__memcpy(destination + (dimsize - 1) * stride + frontIdx + repeat * maxNum, src, remain * sizeof(float), NRAM2GDRAM);
for(int i = 0; i < dimsize - 1; i++){
__memcpy(src, source + i * stride + frontIdx + repeat * maxNum, remain * sizeof(float), GDRAM2NRAM);
__bang_sub(src, src, tmpNewMax, maxNum);//x - M
__bang_active_exp_less_0(src, src, maxNum);//exp(x - M)
__bang_mul(src, src, tmpSum, maxNum);
__memcpy(destination + i * stride + frontIdx + repeat * maxNum, src, remain * sizeof(float), NRAM2GDRAM);
}
//---------------------
}
}
}
int main(void)
{
//int shape[4] = {1024,128,32,32};
//int shape[4] = {1024,64,32,32};
int shape[4] = {1024,32,32,32};
//int shape[4] = {2, 3, 2, 2};
int axis = 2;
int stride = 1;
int dimsize = shape[axis];
int num = 1;
int othersize = 1;
int frontsize = 1;
for(int s = 3; s >= 0; s--){
num *= shape[s];
if(s > axis){
stride *= shape[s];
}
if(s < axis){
frontsize *= shape[s];
}
if(s != axis){
othersize *= shape[s];
}
}
printf("axis:%d, dimsize:%d, stride:%d, othersize:%d, frontsize:%d, num:%d\n", axis, dimsize, stride, othersize, frontsize, num);
cnrtQueue_t queue;
CNRT_CHECK(cnrtSetDevice(0));
CNRT_CHECK(cnrtQueueCreate(&queue));
cnrtDim3_t dim = {4, 1, 1};
int taskNum = dim.x * dim.y * dim.z;
cnrtFunctionType_t ktype = CNRT_FUNC_TYPE_UNION1;
cnrtNotifier_t start, end;
CNRT_CHECK(cnrtNotifierCreate(&start));
CNRT_CHECK(cnrtNotifierCreate(&end));
float* host_destination = (float*)malloc(num * sizeof(float));
float* host_src = (float*)malloc(num * sizeof(float));
for (int i = 0; i < num; i++) {
//host_src[i] = i%4;
host_src[i] = i;
}
float* mlu_destination;
float* mlu_src;
CNRT_CHECK(cnrtMalloc((void**)&mlu_destination, num * sizeof(float)));
CNRT_CHECK(cnrtMalloc((void**)&mlu_src, num * sizeof(float)));
CNRT_CHECK(cnrtMemcpy(mlu_src, host_src, num * sizeof(float), cnrtMemcpyHostToDev));
//----------------------------
CNRT_CHECK(cnrtPlaceNotifier(start, queue));
softmaxKernelAxis_m<<<dim, ktype, queue>>>(mlu_destination, mlu_src, frontsize, dimsize, stride);
CNRT_CHECK(cnrtPlaceNotifier(end, queue));
cnrtQueueSync(queue);
//---------------------------
CNRT_CHECK(cnrtMemcpy(host_destination, mlu_destination, num * sizeof(float), cnrtMemcpyDevToHost));
for(int i = 0; i < 24; i++){
printf("softmax[%d]:%.6e,origin:%.6f\n", i, host_destination[i], host_src[i]);
}
float timeTotal;
CNRT_CHECK(cnrtNotifierDuration(start, end, &timeTotal));
printf("Total Time: %.3f ms\n", timeTotal / 1000.0);
CNRT_CHECK(cnrtQueueDestroy(queue));
cnrtFree(mlu_destination);
cnrtFree(mlu_src);
free(host_destination);
free(host_src);
return 0;
}
策略2:
#include <bang.h>
#include <bang_device_functions.h>
#define EPS 1e-7
const int NRAM_MAX_SIZE = 1024 * 128;//后续树状求和必须保证NRAM_MAX_SIZE为2的幂次
const int maxNum = NRAM_MAX_SIZE/sizeof(float); //NRAM上最多存储maxNum个float元素
__mlu_entry__ void softmaxKernelAxis_m(float* destination, float* source, int frontsize, int dimsize, int stride) {
// 0<axis<dim -1
__nram__ float src[maxNum];
__nram__ float tmpSum[maxNum];
__nram__ float tmpNewMax[maxNum];
__nram__ float tmpOldMax[maxNum];
int remain = stride % taskDim;
int stepEasy = (stride - remain)/taskDim;
int stepHard = stepEasy + 1;
int step = (taskId < remain ? stepHard : stepEasy);//前部分taskId多处理一个元素
int indStart = (taskId < remain ? taskId * stepHard : remain * stepHard + (taskId - remain) * stepEasy);
int remainNram = step % maxNum;
int repeat = (step - remainNram) / maxNum;
for(int ind = 0; ind < frontsize; ind ++){
int frontIdx = ind * dimsize * stride;
for(int j = 0; j < repeat; j++){
__bang_write_value(tmpNewMax, maxNum, -INFINITY);
__bang_write_zero(tmpSum, maxNum);
__bang_write_zero(src, maxNum);
for(int i = 0; i < dimsize; i++){
__memcpy(src, source + frontIdx + i * stride + indStart + j * maxNum, maxNum * sizeof(float), GDRAM2NRAM);
__bang_maxequal(tmpNewMax, tmpNewMax, src, maxNum);//不断更新最大值
__bang_sub(src, src, tmpNewMax, maxNum);//x - M
__bang_active_exp_less_0(src, src, maxNum);//exp(x - M)
if(i > 0){
__bang_sub(tmpOldMax, tmpOldMax, tmpNewMax, maxNum);//oldM = oldM - newM
__bang_active_exp_less_0(tmpOldMax, tmpOldMax, maxNum);//exp(oldM - newM)
__bang_mul(tmpSum, tmpSum, tmpOldMax, maxNum);//sum = sum * exp(oldM - newM)
}
__bang_add(tmpSum, tmpSum, src, maxNum);//sum += exp(x - M)
__memcpy(tmpOldMax, tmpNewMax, maxNum * sizeof(float), NRAM2NRAM);//oldM = newM
}
__bang_active_recip(tmpSum, tmpSum, maxNum);//计算1/sum
//开始指数变换并且写回GDRAM
__bang_mul(src, src, tmpSum, maxNum);//上面循环结束src存储的数据可以利用
__memcpy(destination + (dimsize - 1) * stride + frontIdx + indStart + j * maxNum, src, maxNum * sizeof(float), NRAM2GDRAM);
for(int i = 0; i < dimsize - 1; i++){
__memcpy(src, source + frontIdx + i * stride + indStart + j * maxNum, maxNum * sizeof(float), GDRAM2NRAM);
__bang_sub(src, src, tmpNewMax, maxNum);//x - M
__bang_active_exp_less_0(src, src, maxNum);//exp(x - M)
__bang_mul(src, src, tmpSum, maxNum);
__memcpy(destination + frontIdx + i * stride + indStart + j * maxNum, src, maxNum * sizeof(float), NRAM2GDRAM);
}
}
if(remainNram){
__bang_write_value(tmpNewMax, maxNum, -INFINITY);
__bang_write_zero(tmpSum, maxNum);
__bang_write_zero(src, maxNum);
for(int i = 0; i < dimsize; i++){
__memcpy(src, source + frontIdx + i * stride + indStart + repeat * maxNum, remainNram * sizeof(float), GDRAM2NRAM);
__bang_maxequal(tmpNewMax, tmpNewMax, src, maxNum);
__bang_sub(src, src, tmpNewMax, maxNum);//x - M
__bang_active_exp_less_0(src, src, maxNum);//exp(x - M)
if(i > 0){
__bang_sub(tmpOldMax, tmpOldMax, tmpNewMax, maxNum);//oldM = oldM - newM
__bang_active_exp_less_0(tmpOldMax, tmpOldMax, maxNum);//exp(oldM - newM)
__bang_mul(tmpSum, tmpSum, tmpOldMax, maxNum); //sum = sum * exp(oldM - newM)
}
__bang_add(tmpSum, tmpSum, src, maxNum);//sum += exp(x - M)
__memcpy(tmpOldMax, tmpNewMax, maxNum * sizeof(float), NRAM2NRAM);//oldM = newM
}
//-------------------
__bang_active_recip(tmpSum, tmpSum, maxNum);//计算1/sum
//开始指数变换并且写回GDRAM
__bang_mul(src, src, tmpSum, maxNum);//上面循环结束src存储的数据可以利用
__memcpy(destination + (dimsize - 1) * stride + indStart + frontIdx + repeat * maxNum, src, remainNram * sizeof(float), NRAM2GDRAM);
for(int i = 0; i < dimsize - 1; i++){
__memcpy(src, source + i * stride + frontIdx + repeat * maxNum, remainNram * sizeof(float), GDRAM2NRAM);
__bang_sub(src, src, tmpNewMax, maxNum);//x - M
__bang_active_exp_less_0(src, src, maxNum);//exp(x - M)
__bang_mul(src, src, tmpSum, maxNum);
__memcpy(destination + i * stride + indStart + frontIdx + repeat * maxNum, src, remainNram * sizeof(float), NRAM2GDRAM);
}
//---------------------
}
}
}
int main(void)
{
int shape[4] = {1024,128,32,32};
//int shape[4] = {1024,64,32,32};
//int shape[4] = {1024,32,32,32};
//int shape[4] = {2, 3, 2, 2};
int axis = 1;
int stride = 1;
int dimsize = shape[axis];
int num = 1;
int othersize = 1;
int frontsize = 1;
;
for(int s = 3; s >= 0; s--){
num *= shape[s];
if(s > axis){
stride *= shape[s];
}
if(s < axis){
frontsize *= shape[s];
}
if(s != axis){
othersize *= shape[s];
}
}
printf("axis:%d, dimsize:%d, stride:%d, othersize:%d, frontsize:%d, num:%d\n", axis, dimsize, stride, othersize, frontsize, num);
cnrtQueue_t queue;
CNRT_CHECK(cnrtSetDevice(0));
CNRT_CHECK(cnrtQueueCreate(&queue));
cnrtDim3_t dim = {16, 1, 1};
int taskNum = dim.x * dim.y * dim.z;
cnrtFunctionType_t ktype = CNRT_FUNC_TYPE_UNION4;
cnrtNotifier_t start, end;
CNRT_CHECK(cnrtNotifierCreate(&start));
CNRT_CHECK(cnrtNotifierCreate(&end));
float* host_destination = (float*)malloc(num * sizeof(float));
float* host_src = (float*)malloc(num * sizeof(float));
for (int i = 0; i < num; i++) {
//host_src[i] = i%4;
host_src[i] = i;
}
float* mlu_destination;
float* mlu_src;
CNRT_CHECK(cnrtMalloc((void**)&mlu_destination, num * sizeof(float)));
CNRT_CHECK(cnrtMalloc((void**)&mlu_src, num * sizeof(float)));
CNRT_CHECK(cnrtMemcpy(mlu_src, host_src, num * sizeof(float), cnrtMemcpyHostToDev));
//----------------------------
CNRT_CHECK(cnrtPlaceNotifier(start, queue));
softmaxKernelAxis_m<<<dim, ktype, queue>>>(mlu_destination, mlu_src, frontsize, dimsize, stride);
CNRT_CHECK(cnrtPlaceNotifier(end, queue));
cnrtQueueSync(queue);
//---------------------------
CNRT_CHECK(cnrtMemcpy(host_destination, mlu_destination, num * sizeof(float), cnrtMemcpyDevToHost));
for(int i = 0; i < 24; i++){
printf("softmax[%d]:%.6e,origin:%.6f\n", i, host_destination[i], host_src[i]);
}
float timeTotal;
CNRT_CHECK(cnrtNotifierDuration(start, end, &timeTotal));
printf("Total Time: %.3f ms\n", timeTotal / 1000.0);
CNRT_CHECK(cnrtQueueDestroy(queue));
cnrtFree(mlu_destination);
cnrtFree(mlu_src);
free(host_destination);
free(host_src);
return 0;
}
这里我们不妨看一下不同规模情况下上面并行策略带来的优化效果,下面针对axis=1,2都是指策略1,因为策略2的效果太差不展示:

高维softmax的进一步优化
axis = -1
从上面的表格我们发现对于axis=-1,此时虽然数据读取连续,但是速度仍然非常慢,我们发现最主要原因在于src数组大量内存浪费。比如说我们上面表格的例子,最后一个维度长度是32,但是我们为src开辟的内存是maxNum×sizeof(float),在上面的做法中,我们一次只从GDRAM读取32个浮点数到NRAM,剩下的空间全部浪费了,所以速度特别慢,为了充分利用这部分内存,下面我们将给出另一种思路。
上面做法的本质其实是taskId处理othersize,然后一个src处理一个otherIdx,相当于说src只存放固定一个otherIdx,axis=-1对应的这部分数据。为了充分利用内存,这里我们希望一个src可以存储多个otherIdx对应的axis=-1的这份数据,我们不妨先假设maxNum正好整除shape[-1],并且shape[-1]也是2的幂次方,假设multiple=maxNum/shape[-1]=maxNum/dimsize,此时一个src存储了muitiple个otherIdx对应的数据,一共有othersize个长度为dimsize的向量,一个src就存储了multiple个这样的向量,而且我们一共使用taskDim个任务,因此一次就可以存储size=multiple×taskDim个长度为dimsize的向量,下面为了方便叙述,我们引入一些变量:
multiple=maxNum/shape[-1]=maxNum/dimsize:一个src可以存储多少个长度为dimsize的向量
size=multiple×taskDim:开辟taskDim个任务可以存储长度为dimsize的向量数目
remainS = othersize % size:如果不能整除,多余的余数需要特殊处理,分配给不同taskId,每个taskId额外获得step个
taskRepeat = (othersize - remainS) / size:经过taskReapt次循环可以加载的othersize对应的数据量
整体来看,每个taskId处理的数据量就是(taskRepeat * multiple + step) * dimsize,此时我们可以计算出不同taskId的偏移量,计算以后,下面我们站在taskId的角度来看计算过程:
首先进入一个循环(int s = 0; s < taskRepeat; s++),循环体内部在原有偏移量的情况下计算出不同s对应的偏移量为tid = s × multiple × dimsize,循环体内部每次从GDRAM中读取长度为multiple×dimsize的数据加载到src上,然后再开一个循环(int j = 0; j < multiple; j++),单独针对src处理,每次从src读取长度为dimsize的数据进行求和,指数变换,最终把结果写回GDRAM。
跳出上面的二重循环以后,下面针对额外获得的step这份数据进行处理,此时只需要一重循环(int s = 0; s < step; s++),循环体内每次直接从source读取长度为dimsize的数据,经过一系列计算以后写回GDRAM即可。
#include <bang.h>
#include <bang_device_functions.h>
#define EPS 1e-7
const int NRAM_MAX_SIZE = 1024 * 128;//后续树状求和必须保证NRAM_MAX_SIZE为2的幂次
const int maxNum = NRAM_MAX_SIZE/sizeof(float); //NRAM上最多存储maxNum个float元素
const int warpSize = 32;
//dimS至少要等于dimsize,且是最近的2的幂次方,同时由于后面需要规约,为此dimS至少是32
//下面这个kernel只适合dimsize < maxNum的情况
template<int dimS>
__mlu_entry__ void softmaxKernelAxis_e(float* destination, float* source, int othersize, int dimsize) {// axis = -1
int multiple = maxNum / dimsize;
int size = taskDim * multiple;
int remainS = othersize % size;
int taskRepeat = (othersize - remainS) / size;
int remainT = remainS % taskDim;
int stepEasy = (remainS - remainT) / taskDim;
int stepHard = stepEasy + 1;
int step = (taskId < remainT ? stepHard : stepEasy);
//每个taskId处理othersize分配的量就是taskRepeat * multiple + step
//整体来看,每个taskId处理的数据量就是(taskRepeat * multiple + step) * dimsize
int startHard = taskId * (taskRepeat * multiple + stepHard);
int startEasy = remainT * (taskRepeat * multiple + stepHard) + (taskId - remainT) * (taskRepeat * multiple + stepEasy);
int indStart = (taskId < remainT ? startHard: startEasy);
source = source + indStart * dimsize;
destination = destination + indStart * dimsize;
//printf("taskRepeat:%d, indstart:%d, %d\n", taskRepeat, indStart, indStart * dimsize);
__nram__ float src[maxNum];
__nram__ float tmp[dimS];
__nram__ float destSum[dimS];//后面数值求和
__nram__ float destSumFinal[warpSize];//将destSum规约到destFinal[0]
__nram__ float srcMax[2];
int tid;
for(int s = 0; s < taskRepeat; s++){
tid = s * multiple * dimsize;
__memcpy(src, source + tid, multiple * dimsize * sizeof(float), GDRAM2NRAM);
for(int j = 0; j < multiple; j++){
__bang_write_zero(destSum, dimS);
__bang_write_zero(destSumFinal, warpSize);
__bang_write_value(tmp, dimS, -INFINITY);
__memcpy(tmp, src + j * dimsize, dimsize * sizeof(float), NRAM2NRAM);
__bang_argmax(srcMax, tmp, dimS);
__bang_write_value(tmp, dimS, srcMax[0]);//必须重新初始化为srcMax[0]
__memcpy(tmp, src + j * dimsize, dimsize * sizeof(float), NRAM2NRAM);//必须要重新读取
__bang_sub_scalar(tmp, tmp, srcMax[0], dimS);
__bang_active_exp_less_0(tmp, tmp, dimS);//这里我们认为负无穷-srcMax[0]非常小,所以后面dimS - dimsize部分认为是0
__bang_add(destSum, destSum, tmp, dimS);
int segNum = dimS / warpSize;//开始数值求和
for(int strip = segNum/2; strip > 0; strip = strip / 2){
for(int i = 0; i < strip ; i++){
__bang_add(destSum + i * warpSize, destSum + i * warpSize, destSum + (i + strip) * warpSize, warpSize);
}
}
__bang_reduce_sum(destSumFinal, destSum, warpSize);//此时destSumFinal[0]保存的就是当前dimsize长度数据的数值和
destSumFinal[0] = destSumFinal[0] - (dimS - dimsize);
//__bang_printf("max:%.2f, sum:%.2f\n", srcMax[0], destSumFinal[0]);
float globalSumInv = 1.0/destSumFinal[0];
__bang_mul_scalar(tmp, tmp, globalSumInv, maxNum);
//__memcpy(src + j * dimsize, tmp, dimsize * sizeof(float), NRAM2NRAM);
__memcpy(destination + tid + j * dimsize, tmp, dimsize * sizeof(float), NRAM2GDRAM);
}//必须马上写回GDRAM,如果先写回src,然后src写回GDRAM,可能出现src写回GDRAM没有结束就修改src数据的情况
//__memcpy(destination + tid, src, multiple * dimsize * sizeof(float), NRAM2GDRAM);
}
for(int s = 0; s < step; s++){
tid = taskRepeat * multiple * dimsize + s * dimsize;
__bang_write_zero(destSum, dimS);
__bang_write_zero(destSumFinal, warpSize);
__bang_write_value(tmp, dimS, -INFINITY);
__memcpy(tmp, source + tid, dimsize * sizeof(float), GDRAM2NRAM);
__bang_argmax(srcMax, tmp, dimS);
__bang_write_value(tmp, dimS, srcMax[0]);
__memcpy(tmp, source + tid, dimsize * sizeof(float), GDRAM2NRAM);
__bang_sub_scalar(tmp, tmp, srcMax[0], dimS);
__bang_active_exp_less_0(tmp, tmp, dimS);//后面dimS - dimsize部分是1
__bang_add(destSum, destSum, tmp, dimS);
int segNum = dimS / warpSize;//开始数值求和
for(int strip = segNum/2; strip > 0; strip = strip / 2){
for(int i = 0; i < strip ; i++){
__bang_add(destSum + i * warpSize, destSum + i * warpSize, destSum + (i + strip) * warpSize, warpSize);
}
}
__bang_reduce_sum(destSumFinal, destSum, warpSize);//此时destSumFinal[0]保存的就是当前dimsize长度数据的数值和
destSumFinal[0] = destSumFinal[0] - (dimS - dimsize);
//__bang_printf(":%.2f,max:%.2f, sum:%.2f, final:%.2f\n",tmp[1], srcMax[0], destSum[1], destSumFinal[0]);
float globalSumInv = 1.0/destSumFinal[0];
__bang_mul_scalar(tmp, tmp, globalSumInv, maxNum);
__memcpy(destination + tid, tmp, dimsize * sizeof(float), NRAM2GDRAM);
}
//__bang_printf("max:%.2f, sum:%.2f\n", srcMax[0], destSumFinal[0]);
}
int main(void)
{
//int shape[4] = {1024,128,32,32};
//int shape[4] = {1024,64,32,32};
int shape[4] = {1024,32,32,32};
//int shape[4] = {2, 3, 2, 2};
int axis = 3;
int stride = 1;
int dimsize = shape[axis];
int num = 1;
int othersize = 1;
for(int s = 3; s >= 0; s--){
num *= shape[s];
if(s > axis){
stride *= shape[s];
}
if(s != axis){
othersize *= shape[s];
}
}
printf("axis:%d, dimsize:%d, stride:%d, othersize:%d, num:%d\n", axis, dimsize, stride, othersize, num);
cnrtQueue_t queue;
CNRT_CHECK(cnrtSetDevice(0));
CNRT_CHECK(cnrtQueueCreate(&queue));
cnrtDim3_t dim = {4, 1, 1};
int taskNum = dim.x * dim.y * dim.z;
cnrtFunctionType_t ktype = CNRT_FUNC_TYPE_UNION1;
cnrtNotifier_t start, end;
CNRT_CHECK(cnrtNotifierCreate(&start));
CNRT_CHECK(cnrtNotifierCreate(&end));
float* host_destination = (float*)malloc(num * sizeof(float));
float* host_src = (float*)malloc(num * sizeof(float));
for (int i = 0; i < num; i++) {
host_src[i] = i%4;
//host_src[i] = i;
}
float* mlu_destination;
float* mlu_src;
CNRT_CHECK(cnrtMalloc((void**)&mlu_destination, num * sizeof(float)));
CNRT_CHECK(cnrtMalloc((void**)&mlu_src, num * sizeof(float)));
CNRT_CHECK(cnrtMemcpy(mlu_src, host_src, num * sizeof(float), cnrtMemcpyHostToDev));
//----------------------------
CNRT_CHECK(cnrtPlaceNotifier(start, queue));
softmaxKernelAxis_e<32><<<dim, ktype, queue>>>(mlu_destination, mlu_src, othersize, dimsize);
CNRT_CHECK(cnrtPlaceNotifier(end, queue));
cnrtQueueSync(queue);
//---------------------------
CNRT_CHECK(cnrtMemcpy(host_destination, mlu_destination, num * sizeof(float), cnrtMemcpyDevToHost));
for(int i = 0; i < 24; i++){
printf("softmax[%d]:%.6e,origin:%.6f\n", i, host_destination[i], host_src[i]);
}
float timeTotal;
CNRT_CHECK(cnrtNotifierDuration(start, end, &timeTotal));
printf("Total Time: %.3f ms\n", timeTotal / 1000.0);
CNRT_CHECK(cnrtQueueDestroy(queue));
cnrtFree(mlu_destination);
cnrtFree(mlu_src);
free(host_destination);
free(host_src);
return 0;
}
axis=-1的进一步优化
上面的这种做法有一个特点,需要人为指定dimS,因为同时加载多份dimsize数据以后,我们需要利用循环来读取不同的dimsize对应的数据,这个dimS就是用来承载dimsize长度向量的,上面的要求是dimS至少是dimsize,并且由于后面需要规约,所以dimS至少也得是32。但是实际编写代码中,我们不可能提前知道dimsize的数值,也就没有办法提前传一个常数dimS进去,为此我们需要进一步调整方案。
我们保持整体方案不变,只考虑src加载到多份dimsize数据以后的修改,此时我们仍然需要利用for循环来读取每一份dimsize对应的数据,但是读取过程中我们利用一个长度为dimS(提前使用const int申明具体数值,后面我们使用的都是32)来读取dimsize,那么这个时候仅仅是针对一个长度为dimsize的数据进行读取计算,我们可以计算出为了让长度为dimS的向量tmp读取整个dimsize数据需要的循环次数repeatDim,以及余数remainDim,然后就可以像一维向量一样处理这部分数据了,下面是详细代码:
#include <bang.h>
#include <bang_device_functions.h>
#define EPS 1e-7
const int NRAM_MAX_SIZE = 1024 * 512;//the maximum NRAM memory is 1024 * 768
const int nramNum = NRAM_MAX_SIZE/sizeof(float);
__nram__ float nram_buffer[nramNum];
const int SRC_MAX_SIZE = 1024 * 64;//The subsequent tree summation must ensure that SRC-MAX-SIZE is a power of 2
//4 * SRC_MAX_SIZE must <= NRAM_MAX_SIZE
const int maxNum = SRC_MAX_SIZE/sizeof(float);
const int wSize = 32;
__mlu_device__ void softmaxKernelAxis_e(float* destination, float* source, int othersize, int dimsize, int dimS) {// axis = -1
__nram__ float destSumFinal[wSize];
__nram__ float srcMax[2];
__nram__ float destOldMax;
__nram__ float destNewMax;
if(dimsize >= maxNum){
float *src = nram_buffer;
float *destSum = src + 3 * maxNum;
int remain = dimsize % maxNum;
int repeat = (dimsize - remain)/maxNum;
int otherRemain = othersize % taskDim;
int stepEasy = (othersize - otherRemain) / taskDim;
int stepHard = stepEasy + 1;
int startHard = taskId * stepHard;
int startEasy = otherRemain * stepHard + (taskId - otherRemain) * stepEasy;
int indStart = (taskId < otherRemain ? startHard : startEasy);
source = source + indStart * dimsize;
destination = destination + indStart * dimsize;
destOldMax = -INFINITY;
destNewMax = -INFINITY;
__bang_write_zero(destSum, maxNum);
for(int i = 0; i < repeat + 1; i++){
if(i < repeat){
__memcpy_async(src + i % 2 * maxNum, source + i * maxNum, maxNum * sizeof(float), GDRAM2NRAM);
}
if(i > 0){
__bang_argmax(srcMax, src + (i - 1) % 2 * maxNum, maxNum);
if(destNewMax < srcMax[0]){
destNewMax = srcMax[0];
}
__bang_sub_scalar(src + (i - 1) % 2 * maxNum, src + (i - 1) % 2 * maxNum, destNewMax, maxNum);
__bang_active_exp_less_0(src + (i - 1) % 2 * maxNum, src + (i - 1) % 2 * maxNum, maxNum);
if(i > 1){
__bang_mul_scalar(destSum, destSum, exp(destOldMax - destNewMax), maxNum);
}
__bang_add(destSum, destSum, src + (i - 1) % 2 * maxNum, maxNum);
destOldMax = destNewMax;
}
__sync_all_ipu();
}
//------------
if(remain){
__bang_write_value(src, maxNum, -INFINITY);
__memcpy(src, source + repeat * maxNum, remain * sizeof(float), GDRAM2NRAM);
__bang_argmax(srcMax, src, maxNum);
if(destNewMax < srcMax[0]){
destNewMax = srcMax[0];
}
__bang_write_value(src, maxNum, destNewMax);
__memcpy(src, source + repeat * maxNum, remain * sizeof(float), GDRAM2NRAM);
__bang_sub_scalar(src, src, destNewMax, maxNum);
__bang_active_exp_less_0(src, src, maxNum);
if(repeat > 0){
__bang_mul_scalar(destSum, destSum, exp(destOldMax - destNewMax), maxNum);
}
__bang_add(destSum, destSum, src, maxNum);
destOldMax = destNewMax;
}
//--------------
//--------------------------------
__bang_write_zero(destSumFinal, wSize);
int segNum = maxNum / wSize;
for(int strip = segNum/2; strip > 0; strip = strip / 2){
for(int i = 0; i < strip ; i++){
__bang_add(destSum + i * wSize, destSum + i * wSize, destSum + (i + strip) * wSize, wSize);
}
}
__bang_reduce_sum(destSumFinal, destSum, wSize);
if(remain){
destSumFinal[0] = destSumFinal[0] - (maxNum - remain);
}
//-----------
float globalSumInv = 1.0/destSumFinal[0];
for(int i = 0; i < repeat + 2; i++){
if(i < repeat){
__memcpy_async(src + i % 3 * maxNum, source + i * maxNum, maxNum * sizeof(float), GDRAM2NRAM);
}
if(i > 0 && i < repeat){
__bang_sub_scalar(src + (i - 1) % 3 * maxNum, src + (i - 1) % 3 * maxNum, destNewMax, maxNum);
__bang_active_exp_less_0(src + (i - 1) % 3 * maxNum, src + (i - 1) % 3 * maxNum, maxNum);
__bang_mul_scalar(src + (i - 1) % 3 * maxNum, src + (i - 1) % 3 * maxNum, globalSumInv, maxNum);
}
if(i > 1){
__memcpy_async(destination + (i - 2) * maxNum, src + (i - 2) % 3 * maxNum, maxNum * sizeof(float), NRAM2GDRAM);
}
__sync_all_ipu();
}
if(remain){
__bang_write_value(src, maxNum, destNewMax);
__memcpy(src, source + repeat * maxNum, remain * sizeof(float), GDRAM2NRAM);
__bang_sub_scalar(src, src, destNewMax, maxNum);
__bang_active_exp_less_0(src, src, maxNum);
__bang_mul_scalar(src, src, globalSumInv, maxNum);
__memcpy(destination + repeat * maxNum, src, remain * sizeof(float), NRAM2GDRAM);
}
}
else{
int multiple = maxNum / dimsize;
int size = taskDim * multiple;
int remainS = othersize % size;
int taskRepeat = (othersize - remainS) / size;
int remainT = remainS % taskDim;
int stepEasy = (remainS - remainT) / taskDim;
int stepHard = stepEasy + 1;
int step = (taskId < remainT ? stepHard : stepEasy);
//The amount allocated for processing othersize for each taskId is taskRepeat * multiple+step
//Overall, the amount of data processed by each taskId is (taskRepeat * multiple+step) * dimsize
int startHard = taskId * (taskRepeat * multiple + stepHard);
int startEasy = remainT * (taskRepeat * multiple + stepHard) + (taskId - remainT) * (taskRepeat * multiple + stepEasy);
int indStart = (taskId < remainT ? startHard: startEasy);
source = source + indStart * dimsize;
destination = destination + indStart * dimsize;
//-----------------------------------------allocate memory
float* src = nram_buffer;//src[maxNum]
float* tmp = src + 3 * maxNum;//tmp[dimS]
float* destSum = tmp + dimS;//destSum[dimS],dimS >= max(dimsize, wSize), dimS = pow(2,K) ,pow(2,K - 1) < dimsize
//-----------------------------------------
//printf("taskId:%d, taskRepeat:%d, step:%d, repeatDim:%d, indstart:%d, %d\n", taskId, taskRepeat, step, repeatDim, indStart, indStart * dimsize);
int tid;
for(int s = 0; s < taskRepeat + 2; s++){
if(s < taskRepeat){
tid = s * multiple * dimsize;
__memcpy_async(src + s % 3 * maxNum, source + tid, multiple * dimsize * sizeof(float), GDRAM2NRAM);
}
if(s > 0 && s < taskRepeat + 1){
for(int j = 0; j < multiple; j++){
__bang_write_zero(destSum, dimS);
__bang_write_zero(destSumFinal, wSize);
__bang_write_value(tmp, dimS, -INFINITY);
__memcpy(tmp, src + (s - 1) %3 * maxNum + j * dimsize, dimsize * sizeof(float), NRAM2NRAM);
__bang_argmax(srcMax, tmp, dimS);
__bang_write_value(tmp, dimS, srcMax[0]);
__memcpy(tmp, src + (s - 1) %3 * maxNum + j * dimsize, dimsize * sizeof(float), NRAM2NRAM);
__bang_sub_scalar(tmp, tmp, srcMax[0], dimS);
__bang_active_exp_less_0(tmp, tmp, dimS);//tmp[dimsize:dimS] = exp(0)
__bang_add(destSum, destSum, tmp, dimS);
int segNum = dimS / wSize;//Starting numerical summation
for(int strip = segNum/2; strip > 0; strip = strip / 2){
for(int i = 0; i < strip ; i++){
__bang_add(destSum + i * wSize, destSum + i * wSize, destSum + (i + strip) * wSize, wSize);
}
}
__bang_reduce_sum(destSumFinal, destSum, wSize);//At this point, destSumFinal [0] saves the numerical value of the current dimsize length data sum
destSumFinal[0] = destSumFinal[0] - (dimS - dimsize);
//Now let's start writing back the data
float globalSumInv = 1.0/destSumFinal[0];
__bang_mul_scalar(tmp, tmp, globalSumInv, maxNum);
__memcpy(src + (s - 1) %3 * maxNum + j * dimsize, tmp, dimsize * sizeof(float), NRAM2NRAM);
}
}
if(s > 1){
tid = (s - 2) * multiple * dimsize;
__memcpy_async(destination + tid, src + (s - 2) % 3 * maxNum, multiple * dimsize * sizeof(float), NRAM2GDRAM);
}
__sync_all_ipu();
//it is necessary to write back to GDRAM immediately. If you first write back to src and then write back to GDRAM,
//there may be a situation where src writes back to GDRAM before modifying the src data
}
for(int s = 0; s < step; s++){//Step targets parts of othersize that cannot be divided by multiple * dimsize
tid = taskRepeat * multiple * dimsize + s * dimsize;
__bang_write_zero(destSum, dimS);
__bang_write_zero(destSumFinal, wSize);
__bang_write_value(tmp, dimS, -INFINITY);
__memcpy(tmp, source + tid, dimsize * sizeof(float), GDRAM2NRAM);
__bang_argmax(srcMax, tmp, dimS);
__bang_write_value(tmp, dimS, srcMax[0]);
__memcpy(tmp, source + tid, dimsize * sizeof(float), GDRAM2NRAM);
__bang_sub_scalar(tmp, tmp, srcMax[0], dimS);
__bang_active_exp_less_0(tmp, tmp, dimS);
__bang_add(destSum, destSum, tmp, dimS);
int segNum = dimS / wSize;
for(int strip = segNum/2; strip > 0; strip = strip / 2){
for(int i = 0; i < strip ; i++){
__bang_add(destSum + i * wSize, destSum + i * wSize, destSum + (i + strip) * wSize, wSize);
}
}
__bang_reduce_sum(destSumFinal, destSum, wSize);
destSumFinal[0] = destSumFinal[0] - (dimS - dimsize);
//__bang_printf(":%.2f,max:%.2f, sum:%.2f, final:%.2f\n",tmp[1], srcMax[0], destSum[1], destSumFinal[0]);
float globalSumInv = 1.0/destSumFinal[0];
__bang_mul_scalar(tmp, tmp, globalSumInv, maxNum);
__memcpy(destination + tid, tmp, dimsize * sizeof(float), NRAM2GDRAM);
}
}
}
__mlu_global__ void softmaxUnion1(float *mlu_destination, float *mlu_src, int othersize, int dimsize){
int dimS;
float mi = log2(dimsize);
if(floor(mi) == mi){
dimS = dimsize;
}
else{
dimS = pow(2,floor(mi) + 1);
}
if(dimS < wSize){
dimS = wSize;
}
softmaxKernelAxis_e(mlu_destination, mlu_src, othersize, dimsize, dimS);
}
int main(void)
{
int shape[4] = {1024,1024, 1, 1024};
int axis = 3;
int stride = 1;
int dimsize = shape[axis];
int num = 1;
int othersize = 1;
for(int s = 3; s >= 0; s--){
num *= shape[s];
if(s > axis){
stride *= shape[s];
}
if(s != axis){
othersize *= shape[s];
}
}
printf("axis:%d, dimsize:%d, stride:%d, othersize:%d, num:%d\n", axis, dimsize, stride, othersize, num);
cnrtQueue_t queue;
CNRT_CHECK(cnrtSetDevice(0));
CNRT_CHECK(cnrtQueueCreate(&queue));
cnrtDim3_t dim = {16, 1, 1};
int taskNum = dim.x * dim.y * dim.z;
cnrtFunctionType_t ktype = CNRT_FUNC_TYPE_UNION1;
cnrtNotifier_t start, end;
CNRT_CHECK(cnrtNotifierCreate(&start));
CNRT_CHECK(cnrtNotifierCreate(&end));
float* host_destination = (float*)malloc(num * sizeof(float));
float* host_src = (float*)malloc(num * sizeof(float));
for (int i = 0; i < num; i++) {
//host_src[i] = i%4;
host_src[i] = i;
}
float* mlu_destination;
float* mlu_src;
CNRT_CHECK(cnrtMalloc((void**)&mlu_destination, num * sizeof(float)));
CNRT_CHECK(cnrtMalloc((void**)&mlu_src, num * sizeof(float)));
CNRT_CHECK(cnrtMemcpy(mlu_src, host_src, num * sizeof(float), cnrtMemcpyHostToDev));
//----------------------------
CNRT_CHECK(cnrtPlaceNotifier(start, queue));
softmaxUnion1<<<dim, ktype, queue>>>(mlu_destination, mlu_src, othersize, dimsize);
CNRT_CHECK(cnrtPlaceNotifier(end, queue));
cnrtQueueSync(queue);
//---------------------------
CNRT_CHECK(cnrtMemcpy(host_destination, mlu_destination, num * sizeof(float), cnrtMemcpyDevToHost));
float timeTotal;
CNRT_CHECK(cnrtNotifierDuration(start, end, &timeTotal));
printf("Total Time: %.3f ms\n", timeTotal / 1000.0);
CNRT_CHECK(cnrtQueueDestroy(queue));
cnrtFree(mlu_destination);
cnrtFree(mlu_src);
free(host_destination);
free(host_src);
return 0;
}
0 < axis < dimsize - 1
这种情况更加特殊,根据上面的分析,我们知道如果axis是中间维度,比如说[A,B,C,D]向量,axis=1,索引为i(BCD)+j(CD)+k(D)+s,此时我们把索引分成三个部分,i(BCD)称之为frontIdx,k(D)+s对应的部分是长度为CD的behindsize,而且我们知道behindsize=stride,以及中间对应的j(CD)。上面我们分析,对于固定的frontIdx来说,behindsize在内存中是连续的,我们可以使用for(j = 0: j < B: j++),循环体内每次读取[frontIdx + j×(CD):frontIdx + (j+1)×(CD)]数据,因此得到B个长度为CD的向量,然后这B个向量逐元素对比最大值得到一个长度为CD的向量tmpNewMax,此时tmpNewMax对应元素保存的就是固定frontIdx下不同(k,s)对应的最大值。
和上面axis=-1类似,这种情况如果behindsize远远小于maxNum,那么src也会有大量的内存浪费,因此我们也希望能让src尽可能多加载数据。
这里我们需要考虑一下maxNum和BCD的相对大小,在axis=1的情况下,如果BCD的大小和maxNum差不多,那么我们尽量希望src一次加载长度为BCD的向量,此时src保存的数据相当于是固定frontIdx情况下,对于所有(k,s)的数据,接下来我们针对src的数据做一个循环for(j=0;j<B;j++),循环体每次读取长度为CD的数据,不断更新最大值,最后写回GDRAM。这种做法更加适合axis相对靠前,CD小于maxNum,BCD小于maxNum但是BCD接近maxNum的情况,因为当axis相对靠前的时候,此时dimsize×stride会更有机会超过maxNum。如果说stride比maxNum小,但是dimsize×stride比maxNum大,此时我们就需要针对dimsize进行拆分,详细细节参考代码。
如果axis相对靠后,此时就算是dimsize×stride也远小于maxNum,那么就算一次读取长度为dimsize×stride的数据,src也会有大量内存浪费,此时我们就希望src能够读取多个以长度为dimsize×stride的数据,保证src内存尽可能填充满(最极端的例子,比如说上面的4维向量[A,B,C,D],axis=2,如果D远小于maxNum,CD远小于maxNum,BCD远小于maxNum,就连ABCD也远小于maxNum,此时就干脆让src一次把所有数据都加载进来)。这个时候就需要额外开辟一个长度为dimsize×stride的NRAM向量,每次从src中读取数据,不断计算循环(和原始做法一样,只不过原来从GDRAM读取长度为dimsize×stride的数据,现在变成了从NRAM的src中读取长度为dimsize×stride的数据)。
axis相对靠前
此时虽然stride<maxNum,但是dimsize×stride>=maxNum,那么我们一次让src加载multiple×stride个数据,其中multiple=maxNum/stride,代码如下:
下面这个代码需要特别注意的是,计算出frontIdx以后,千万不能写source = source + frontIdx,而是应该在数据读取的时候进行偏移,否则会导致内存踩踏(内存踩踏原因还在查找)
#include <bang.h>
#include <bang_device_functions.h>
#define EPS 1e-7
const int NRAM_MAX_SIZE = 1024 * 128;//后续树状求和必须保证NRAM_MAX_SIZE为2的幂次
const int maxNum = NRAM_MAX_SIZE/sizeof(float); //NRAM上最多存储maxNum个float元素
//strideS是大于等于stride的最小的二的幂次方
template<int strideS>
__mlu_entry__ void softmaxKernelAxis_m(float* destination, float* source, int frontsize, int dimsize, int stride) {
// 0<axis<dim -1
__nram__ float src[maxNum];
__nram__ float tmp[strideS];
__nram__ float tmpOldMax[strideS];
__nram__ float tmpNewMax[strideS];
__nram__ float tmpSum[strideS];
if(dimsize * stride >= maxNum){
int multiple = maxNum / stride;
int size = multiple * stride;//一个src最多可以放的数据量
int remain = dimsize % multiple;//如果不能整除,这部分数据需要特殊处理
int repeat = (dimsize - remain) / multiple;//为了加载整个dimsize需要的循环总数
printf("maxNum:%d, dimsize * stride:%d, multiple:%d, size:%d, repeat:%d,remain:%d\n",maxNum, dimsize * stride, multiple, size, repeat,remain);
for(int ind = taskId; ind < frontsize; ind += taskDim){
int frontIdx = ind * dimsize * stride;
__bang_write_value(tmpNewMax, strideS, -INFINITY);//必须初始化为负无穷
__bang_write_value(tmp, strideS, -INFINITY);//必须初始化为负无穷
__bang_write_zero(tmpSum, strideS);//必须初始化为0
for(int j = 0; j < repeat; j++){
__memcpy(src, source + frontIdx + j * multiple * stride, size * sizeof(float), GDRAM2NRAM);
for(int m = 0; m < multiple; m++){
__memcpy(tmp, src + m * stride, stride * sizeof(float), NRAM2NRAM);
__bang_maxequal(tmpNewMax, tmpNewMax, tmp, strideS);//虽然tmpNewMax后面strideS-stride部分是0,但是不用写回GDRAM,不影响结果
__bang_sub(tmp, tmp, tmpNewMax, strideS);//tmp后面strideS-stride部分是0
__bang_active_exp_less_0(tmp, tmp, strideS);
if(j != 0 || m != 0){
__bang_sub(tmpOldMax, tmpOldMax, tmpNewMax, strideS);//oldM = oldM - newM
__bang_active_exp_less_0(tmpOldMax, tmpOldMax, strideS);//exp(oldM - newM)
__bang_mul(tmpSum, tmpSum, tmpOldMax, strideS);//sum = sum * exp(oldM - newM)
}
__bang_add(tmpSum, tmpSum, tmp, strideS);//sum += exp(x - M)
//if(m == 0) __bang_printf("tmp:%.2f, tmpMax[0]:%.2f,tmpSum[0]:%.2f\n", tmp[1], tmpNewMax[1],tmpSum[0]);
__memcpy(tmpOldMax, tmpNewMax, stride * sizeof(float), NRAM2NRAM);//oldM = newM
}
}
//__bang_printf("tmpOldMax[0]:%.2f,tmpSum[0]:%.2f\n", tmpNewMax[0],tmpSum[0]);
if(remain){
__memcpy(src, source + frontIdx + repeat * multiple * stride, remain * stride * sizeof(float), GDRAM2NRAM);
for(int m = 0; m < remain; m++){
__memcpy(tmp, src + m * stride, stride * sizeof(float), NRAM2NRAM);
__bang_maxequal(tmpNewMax, tmpNewMax, tmp, strideS);
__bang_sub(tmp, tmp, tmpNewMax, strideS);//tmp后面strideS-stride部分是0
__bang_active_exp_less_0(tmp, tmp, strideS);
if(repeat != 0 || m != 0){
__bang_sub(tmpOldMax, tmpOldMax, tmpNewMax, strideS);//oldM = oldM - newM
__bang_active_exp_less_0(tmpOldMax, tmpOldMax, strideS);//exp(oldM - newM)
__bang_mul(tmpSum, tmpSum, tmpOldMax, strideS);//sum = sum * exp(oldM - newM)
}
__bang_add(tmpSum, tmpSum, tmp, strideS);//sum += exp(x - M)
__memcpy(tmpOldMax, tmpNewMax, stride * sizeof(float), NRAM2NRAM);//oldM = newM
}
}
//此时tmpNewMax存储的是对应于固定frontIdx,behindsize对应数据的最大值,而tmpSum存储的就是对应数值和
//__bang_printf("tmpOldMax[0]:%.2f,tmpSum[0]:%.2f\n", tmpNewMax[2],tmpSum[2]);
__bang_active_recip(tmpSum, tmpSum, strideS);
//__bang_printf("tmpOldMax[0]:%.2f,tmpSum[0]:%.2f\n", tmpNewMax[2],tmpSum[2]);
if(remain){
for(int m = 0; m < remain; m++){
__memcpy(tmp, src + m * stride, stride * sizeof(float), NRAM2NRAM);
__bang_sub(tmp, tmp, tmpNewMax, strideS);
__bang_active_exp_less_0(tmp, tmp, strideS);
__bang_mul(tmp, tmp, tmpSum, strideS);
__memcpy(destination + frontIdx + repeat * multiple * stride + m * stride, tmp, stride * sizeof(float), NRAM2GDRAM);
}
}
for(int j = 0 ; j < repeat; j++){
__memcpy(src, source + frontIdx + j * multiple * stride, size * sizeof(float), GDRAM2NRAM);
for(int m = 0; m < multiple; m++){
__memcpy(tmp, src + m * stride, stride * sizeof(float), NRAM2NRAM);
__bang_sub(tmp, tmp, tmpNewMax, strideS);
__bang_active_exp_less_0(tmp, tmp, strideS);
__bang_mul(tmp, tmp, tmpSum, strideS);
__memcpy(destination + frontIdx + j * multiple * stride + m * stride, tmp, stride * sizeof(float), NRAM2GDRAM);
}
}
}
}
}
int main(void)
{
//int shape[4] = {1024,128,32,32};
//int shape[4] = {1024,64,32,32};
int shape[4] = {1024,32,32,32};
//int shape[4] = {2, 3, 2, 2};
int axis = 1;
int stride = 1;
int dimsize = shape[axis];
int num = 1;
int othersize = 1;
int frontsize = 1;
;
for(int s = 3; s >= 0; s--){
num *= shape[s];
if(s > axis){
stride *= shape[s];
}
if(s < axis){
frontsize *= shape[s];
}
if(s != axis){
othersize *= shape[s];
}
}
printf("axis:%d, dimsize:%d, stride:%d, othersize:%d, frontsize:%d, num:%d\n", axis, dimsize, stride, othersize, frontsize, num);
cnrtQueue_t queue;
CNRT_CHECK(cnrtSetDevice(0));
CNRT_CHECK(cnrtQueueCreate(&queue));
cnrtDim3_t dim = {4, 1, 1};
int taskNum = dim.x * dim.y * dim.z;
cnrtFunctionType_t ktype = CNRT_FUNC_TYPE_UNION1;
cnrtNotifier_t start, end;
CNRT_CHECK(cnrtNotifierCreate(&start));
CNRT_CHECK(cnrtNotifierCreate(&end));
float* host_destination = (float*)malloc(num * sizeof(float));
float* host_src = (float*)malloc(num * sizeof(float));
for (int i = 0; i < num; i++) {
//host_src[i] = i%4;
host_src[i] = i;
}
float* mlu_destination;
float* mlu_src;
CNRT_CHECK(cnrtMalloc((void**)&mlu_destination, num * sizeof(float)));
CNRT_CHECK(cnrtMalloc((void**)&mlu_src, num * sizeof(float)));
CNRT_CHECK(cnrtMemcpy(mlu_src, host_src, num * sizeof(float), cnrtMemcpyHostToDev));
//----------------------------
CNRT_CHECK(cnrtPlaceNotifier(start, queue));
softmaxKernelAxis_m<1024><<<dim, ktype, queue>>>(mlu_destination, mlu_src, frontsize, dimsize, stride);
CNRT_CHECK(cnrtPlaceNotifier(end, queue));
cnrtQueueSync(queue);
//---------------------------
CNRT_CHECK(cnrtMemcpy(host_destination, mlu_destination, num * sizeof(float), cnrtMemcpyDevToHost));
for(int i = 0; i < 24; i++){
printf("softmax[%d]:%.6e,origin:%.6f\n", i, host_destination[i], host_src[i]);
}
float timeTotal;
CNRT_CHECK(cnrtNotifierDuration(start, end, &timeTotal));
printf("Total Time: %.3f ms\n", timeTotal / 1000.0);
CNRT_CHECK(cnrtQueueDestroy(queue));
cnrtFree(mlu_destination);
cnrtFree(mlu_src);
free(host_destination);
free(host_src);
return 0;
}
axis相对靠后
此时不仅stride<maxNum,dimsize×stride<maxNum,那么干脆定义behindsize = dimsize×stride,我们一次让src加载multiple×behindsize个数据,其中multiple=maxNum/behindsize,代码如下:
#include <bang.h>
#include <bang_device_functions.h>
#define EPS 1e-7
const int NRAM_MAX_SIZE = 1024 * 128;//后续树状求和必须保证NRAM_MAX_SIZE为2的幂次
const int maxNum = NRAM_MAX_SIZE/sizeof(float); //NRAM上最多存储maxNum个float元素
//strideS是大于等于stride的最小的二的幂次方
template<int strideS>
__mlu_entry__ void softmaxKernelAxis_m(float* destination, float* source, int frontsize, int dimsize, int stride) {
// 0<axis<dim -1
__nram__ float src[maxNum];
__nram__ float tmp[strideS];
__nram__ float tmpOldMax[strideS];
__nram__ float tmpNewMax[strideS];
__nram__ float tmpSum[strideS];
if(dimsize * stride < maxNum){
int behindsize = dimsize * stride;
int multiple = maxNum / behindsize;//表示一个maxNum能够在frontsize中分担的量
int size = multiple * behindsize;//一个taskId中一个src能够加载的数据量
int remainF = frontsize % (taskDim * multiple);
int remainT = remainF % taskDim;
int stepEasy = (remainF - remainT) / taskDim;
int stepHard = stepEasy + 1;
int step = (taskId < remainT ? stepHard : stepEasy);
int taskRepeat = (frontsize - remainF) / (taskDim * multiple);
//此时对应于frontsize,每个taskId处理的数据量是taskRepeat * multiple + step
int startHard = taskId * (taskRepeat * multiple + stepHard);
int startEasy = remainT * (taskRepeat * multiple + stepHard) + (taskId - remainT) * (taskRepeat * multiple + stepEasy);
int indStart = (taskId < remainT ? startHard: startEasy);
source = source + indStart * behindsize;//indStart * behindsize表示不同taskId对应的偏移量
destination = destination + indStart * behindsize;
int tid;
for(int s = 0; s < taskRepeat; s++){
tid = s * multiple * behindsize;
__memcpy(src, source + tid, multiple * behindsize * sizeof(float), GDRAM2NRAM);
for(int m = 0; m < multiple; m++){
__bang_write_zero(tmpSum, strideS);
__bang_write_value(tmp, strideS, -INFINITY);
__bang_write_value(tmpNewMax, strideS, -INFINITY);
for(int i = 0; i < dimsize; i++){
__memcpy(tmp, src + m * behindsize + i * stride, stride * sizeof(float), NRAM2NRAM);
__bang_maxequal(tmpNewMax, tmpNewMax, tmp, strideS);
__bang_sub(tmp, tmp, tmpNewMax, strideS);//x - M
__bang_active_exp_less_0(tmp, tmp, strideS);//exp(x - M)
if(i > 0){
__bang_sub(tmpOldMax, tmpOldMax, tmpNewMax, strideS);//oldM = oldM - newM
__bang_active_exp_less_0(tmpOldMax, tmpOldMax, strideS);//exp(oldM - newM)
__bang_mul(tmpSum, tmpSum, tmpOldMax, strideS); //sum = sum * exp(oldM - newM)
}
__bang_add(tmpSum, tmpSum, tmp, strideS);//sum += exp(x - M)
__memcpy(tmpOldMax, tmpNewMax, stride * sizeof(float), NRAM2NRAM);//oldM = newM
}
__bang_active_recip(tmpSum, tmpSum, strideS);
__bang_mul(tmp, tmp, tmpSum, strideS);//上面循环结束tmp存储的数据可以利用
//__memcpy(destination + tid + m * behindsize + (dimsize - 1) * stride, tmp, stride * sizeof(float), NRAM2GDRAM);
__memcpy(src + m * behindsize + (dimsize - 1) * stride, tmp, stride * sizeof(float), NRAM2NRAM);
for(int i = 0; i < dimsize - 1; i++){
__memcpy(tmp, src + m * behindsize + i * stride, stride * sizeof(float), NRAM2NRAM);
__bang_sub(tmp, tmp, tmpNewMax, strideS);//x - M
__bang_active_exp_less_0(tmp, tmp, strideS);//exp(x - M)
__bang_mul(tmp, tmp, tmpSum, strideS);
//__memcpy(destination + tid + m * behindsize + i * stride, tmp, stride * sizeof(float), NRAM2GDRAM);
__memcpy(src + m * behindsize + i * stride, tmp, stride * sizeof(float), NRAM2NRAM);
}
}
__memcpy(destination + tid, src, multiple * behindsize * sizeof(float), NRAM2GDRAM);
}
__bang_printf("taskId:%d, multiple:%d, taskRepeat:%d, step:%d, indStart:%d\n",taskId, multiple, taskRepeat, step, indStart * behindsize);
if(step){
tid = taskRepeat * multiple * behindsize;
__memcpy(src, source + tid, step * behindsize * sizeof(float), GDRAM2NRAM);
for(int m = 0; m < step; m++){
__bang_write_zero(tmpSum, strideS);
__bang_write_value(tmp, strideS, -INFINITY);
__bang_write_value(tmpNewMax, strideS, -INFINITY);
for(int i = 0; i < dimsize; i++){
__memcpy(tmp, src + m * behindsize + i * stride, stride * sizeof(float), NRAM2NRAM);
__bang_maxequal(tmpNewMax, tmpNewMax, tmp, strideS);
__bang_sub(tmp, tmp, tmpNewMax, strideS);//x - M
__bang_active_exp_less_0(tmp, tmp, strideS);//exp(x - M)
if(i > 0){
__bang_sub(tmpOldMax, tmpOldMax, tmpNewMax, strideS);//oldM = oldM - newM
__bang_active_exp_less_0(tmpOldMax, tmpOldMax, strideS);//exp(oldM - newM)
__bang_mul(tmpSum, tmpSum, tmpOldMax, strideS); //sum = sum * exp(oldM - newM)
}
__bang_add(tmpSum, tmpSum, tmp, strideS);//sum += exp(x - M)
__memcpy(tmpOldMax, tmpNewMax, stride * sizeof(float), NRAM2NRAM);//oldM = newM
}
//__bang_printf("max:%.2f,%.2f, sum:%.2f,sum:%.2f\n", tmpNewMax[0], tmpNewMax[1], tmpSum[0], tmpSum[0]);
__bang_active_recip(tmpSum, tmpSum, strideS);
__bang_mul(tmp, tmp, tmpSum, strideS);//上面循环结束tmp存储的数据可以利用
//__memcpy(destination + tid + m * behindsize + (dimsize - 1) * stride, tmp, stride * sizeof(float), NRAM2GDRAM);
__memcpy(src + m * behindsize + (dimsize - 1) * stride, tmp, stride * sizeof(float), NRAM2NRAM);
for(int i = 0; i < dimsize - 1; i++){
__memcpy(tmp, src + m * behindsize + i * stride, stride * sizeof(float), NRAM2NRAM);
__bang_sub(tmp, tmp, tmpNewMax, strideS);//x - M
__bang_active_exp_less_0(tmp, tmp, strideS);//exp(x - M)
__bang_mul(tmp, tmp, tmpSum, strideS);
//__memcpy(destination + tid + m * behindsize + i * stride, tmp, stride * sizeof(float), NRAM2GDRAM);
__memcpy(src + m * behindsize + i * stride, tmp, stride * sizeof(float), NRAM2NRAM);
}
}
__memcpy(destination + tid, src, step * behindsize * sizeof(float), NRAM2GDRAM);
}
}
}
int main(void)
{
//int shape[4] = {1024,128,32,32};
//int shape[4] = {1024,64,32,32};
int shape[4] = {1024,32,32,32};
//int shape[4] = {2, 3, 2, 2};
int axis = 2;
int stride = 1;
int dimsize = shape[axis];
int num = 1;
int othersize = 1;
int frontsize = 1;
;
for(int s = 3; s >= 0; s--){
num *= shape[s];
if(s > axis){
stride *= shape[s];
}
if(s < axis){
frontsize *= shape[s];
}
if(s != axis){
othersize *= shape[s];
}
}
printf("axis:%d, dimsize:%d, stride:%d, othersize:%d, frontsize:%d, num:%d\n", axis, dimsize, stride, othersize, frontsize, num);
cnrtQueue_t queue;
CNRT_CHECK(cnrtSetDevice(0));
CNRT_CHECK(cnrtQueueCreate(&queue));
cnrtDim3_t dim = {4, 1, 1};
int taskNum = dim.x * dim.y * dim.z;
cnrtFunctionType_t ktype = CNRT_FUNC_TYPE_UNION1;
cnrtNotifier_t start, end;
CNRT_CHECK(cnrtNotifierCreate(&start));
CNRT_CHECK(cnrtNotifierCreate(&end));
float* host_destination = (float*)malloc(num * sizeof(float));
float* host_src = (float*)malloc(num * sizeof(float));
for (int i = 0; i < num; i++) {
//host_src[i] = i%4;
host_src[i] = i;
}
float* mlu_destination;
float* mlu_src;
CNRT_CHECK(cnrtMalloc((void**)&mlu_destination, num * sizeof(float)));
CNRT_CHECK(cnrtMalloc((void**)&mlu_src, num * sizeof(float)));
CNRT_CHECK(cnrtMemcpy(mlu_src, host_src, num * sizeof(float), cnrtMemcpyHostToDev));
//----------------------------
CNRT_CHECK(cnrtPlaceNotifier(start, queue));
softmaxKernelAxis_m<1024><<<dim, ktype, queue>>>(mlu_destination, mlu_src, frontsize, dimsize, stride);
CNRT_CHECK(cnrtPlaceNotifier(end, queue));
cnrtQueueSync(queue);
//---------------------------
CNRT_CHECK(cnrtMemcpy(host_destination, mlu_destination, num * sizeof(float), cnrtMemcpyDevToHost));
for(int i = 0; i < 24; i++){
printf("softmax[%d]:%.6e,origin:%.6f\n", i, host_destination[i], host_src[i]);
}
float timeTotal;
CNRT_CHECK(cnrtNotifierDuration(start, end, &timeTotal));
printf("Total Time: %.3f ms\n", timeTotal / 1000.0);
CNRT_CHECK(cnrtQueueDestroy(queue));
cnrtFree(mlu_destination);
cnrtFree(mlu_src);
free(host_destination);
free(host_src);
return 0;
}
下面使用的taskDim都是4,任务类型都是Union1:
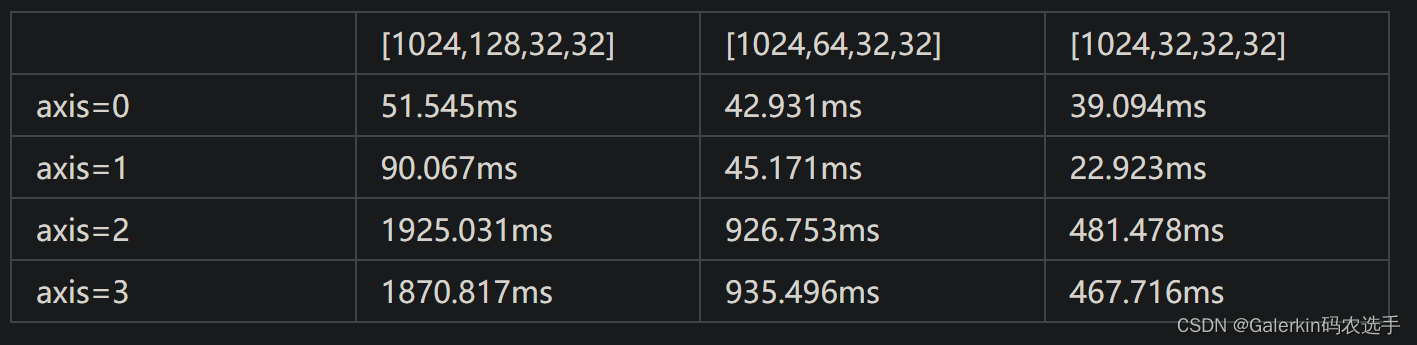
寒武纪构建C++项目以及库函数和手写bang C性能比较
src/main.cpp
#include <iostream>
#include <math.h>
#include "softmax.h"
#include <random>
class RandomGenerator
{
private:
double l, r;
std::mt19937 e;
std::uniform_int_distribution<int> di;
std::uniform_real_distribution<float> dr;
public:
RandomGenerator(double l = 0, double r = 1, unsigned int seed = 0)
: l(l), r(r), e(seed), di(l, r), dr(l, r) {}
virtual ~RandomGenerator() {}
void fill(uint32_t *data, size_t size)
{
for (size_t i = 0; i < size; i++)
{
data[i] = di(e);
}
}
void fill(float *data, size_t size)
{
for (size_t i = 0; i < size; i++)
{
data[i] = dr(e);
}
}
};
int main()
{
int nDim = 4;
//int shape[2] = {1024 * 1024, 1024};
int shape[4] = {1024 , 1, 1024, 1023};
//int axis = nDim - 1;
int axis = 2;
int dimsize = shape[axis];
int num = 1;
for (int s = 0; s < nDim; s++)
{
num *= shape[s];
}
float *host_destination = (float *)malloc(num * sizeof(float));
float *tmp_destination = (float *)malloc(num * sizeof(float));
float *host_src = (float *)malloc(num * sizeof(float));
for (int i = 0; i < num; i++)
{
host_src[i] = (i % 4) * 1e-1;
}
softmaxCnnl(tmp_destination, host_src, nDim, axis, shape);
softmaxParallel(host_destination, host_src, axis, nDim, shape);
float err = 0;
for (int i = 0; i < num; i++)
{
err = fmax(err, fabs(tmp_destination[i] - host_destination[i]));
if (err > 1e-3)
{
printf("%d = [%d * dimsize + %d], error:%.4e, cnnl:%.4e, bangC:%.4e\n", i, i / dimsize, i % dimsize, err, tmp_destination[i], host_destination[i]);
break;
}
}
free(host_destination);
free(tmp_destination);
free(host_src);
return 0;
}
src/softmaxCnnl.cpp
#include "cnnl.h"
#include "cnrt.h"
#include <vector>
#include <sys/time.h>
double get_walltime()
{
struct timeval tp;
gettimeofday(&tp, NULL);
return (double)(tp.tv_sec + tp.tv_usec * 1e-6);
}
void softmaxCnnlDevice(float *source, float *destination, int nDim, int axis, int *shape, cnnlHandle_t &handle, cnrtQueue_t &queue)
{
cnnlSoftmaxMode_t mode;
std::vector<int> inDim = {1, 1, 1};
std::vector<int> outDim = inDim;
if (nDim >= 3)
{
if (axis == 0)
{
mode = CNNL_SOFTMAX_MODE_HIGH_DIMENSION;
inDim[0] = shape[0];
inDim[1] = shape[1];
for (int i = 2; i < nDim; ++i)
{
inDim[2] *= shape[i];
}
outDim = inDim;
}
else if (axis == nDim - 1)
{
mode = CNNL_SOFTMAX_MODE_LOW_DIMENSION;
inDim[0] = shape[0];
for (int i = 1; i < axis; ++i)
{
inDim[1] *= shape[i];
}
inDim[2] = shape[axis];
outDim = inDim;
}
else
{
mode = CNNL_SOFTMAX_MODE_MEDIUM_DIMENSION;
for (int i = 0; i < axis; ++i)
{
inDim[0] *= shape[i];
}
inDim[1] = shape[axis];
for (int i = axis + 1; i < nDim; ++i)
{
inDim[2] *= shape[i];
}
outDim = inDim;
}
}
else if (nDim == 2)
{
if (axis == 0)
{
mode = CNNL_SOFTMAX_MODE_HIGH_DIMENSION;
inDim[0] = shape[0];
inDim[1] = shape[1];
outDim = inDim;
}
else
{
mode = CNNL_SOFTMAX_MODE_LOW_DIMENSION;
inDim[1] = shape[0];
inDim[2] = shape[1];
outDim = inDim;
}
}
else
{
mode = CNNL_SOFTMAX_MODE_HIGH_DIMENSION;
inDim[0] = shape[0];
outDim = inDim;
}
cnnlTensorDescriptor_t aDesc, cDesc;
cnnlCreateTensorDescriptor(&aDesc);
cnnlSetTensorDescriptor(
aDesc, CNNL_LAYOUT_ARRAY, CNNL_DTYPE_FLOAT,
inDim.size(), inDim.data());
cnnlCreateTensorDescriptor(&cDesc);
cnnlSetTensorDescriptor(
cDesc, CNNL_LAYOUT_ARRAY, CNNL_DTYPE_FLOAT,
outDim.size(), outDim.data());
float alpha = 1.0;
float beta = 0.0;
cnrtNotifier_t start = nullptr, end = nullptr;
CNRT_CHECK(cnrtNotifierCreate(&start));
CNRT_CHECK(cnrtNotifierCreate(&end));
CNRT_CHECK(cnrtPlaceNotifier(start, queue));
cnnlStatus_t stat =
cnnlSoftmaxForward_v2(handle, CNNL_SOFTMAX_ACCURATE,
mode, CNNL_COMPUTATION_ULTRAHIGH_PRECISION,
&alpha, aDesc, source, &beta, cDesc, destination);
CNRT_CHECK(cnrtPlaceNotifier(end, queue));
CNRT_CHECK(cnrtQueueSync(queue));
float timeTotal;
CNRT_CHECK(cnrtNotifierDuration(start, end, &timeTotal));
printf("cnnl softmax queue time:%.3f ms\n", timeTotal / 1000.0);
if (stat != CNNL_STATUS_SUCCESS)
return;
cnnlDestroyTensorDescriptor(aDesc);
cnnlDestroyTensorDescriptor(cDesc);
CNRT_CHECK(cnrtNotifierDestroy(start));
CNRT_CHECK(cnrtNotifierDestroy(end));
}
void softmaxCnnl(float *host_destination, float *host_src, int nDim, int axis, int *shape)
{
int num = 1;
for (int s = 0; s < nDim; s++)
{
num *= shape[s];
}
CNRT_CHECK(cnrtSetDevice(0));
cnnlHandle_t handle;
cnnlCreate(&handle);
cnrtQueue_t queue;
CNRT_CHECK(cnrtQueueCreate(&queue));
cnnlSetQueue(handle, queue); // 将队列绑定到 handle 中, 此接口也可用来更改句柄中的队列。
float *mlu_destination;
float *mlu_src;
CNRT_CHECK(cnrtMalloc((void **)&mlu_destination, num * sizeof(float)));
CNRT_CHECK(cnrtMalloc((void **)&mlu_src, num * sizeof(float)));
CNRT_CHECK(cnrtMemcpy(mlu_src, host_src, num * sizeof(float), cnrtMemcpyHostToDev));
//----------------------------
double st, ela;
st = get_walltime();
softmaxCnnlDevice(mlu_src, mlu_destination, nDim, axis, shape, handle, queue);
ela = get_walltime() - st;
CNRT_CHECK(cnrtMemcpy(host_destination, mlu_destination, num * sizeof(float), cnrtMemcpyDevToHost));
printf("cnnl softmax Total Time: %.3f ms\n", ela * 1000);
cnnlDestroy(handle);
CNRT_CHECK(cnrtQueueDestroy(queue));
cnrtFree(mlu_destination);
cnrtFree(mlu_src);
}
src/softmax.mlu
#include <bang.h>
#include <bang_device_functions.h>
#define EPS 1e-7
const int NRAM_MAX_SIZE = 1024 * (512 + 128);//the maximum NRAM memory is 1024 * 768
const int nramNum = NRAM_MAX_SIZE/sizeof(float);
__nram__ float nram_buffer[nramNum];
const int wSize = 32;
__mlu_device__ void softmaxKernelAxis_e(float* destination, float* source, int othersize, int dimsize, int dimS) {// axis = -1
const int SRC_MAX_SIZE = 1024 * 128;//The subsequent tree summation must ensure that SRC-MAX-SIZE is a power of 2
const int maxNum = SRC_MAX_SIZE/sizeof(float);
__nram__ float srcMax[2];
if(dimsize >= maxNum){
float *src = nram_buffer;
float *destSum = src + 3 * maxNum;
float *destSumFinal = destSum + maxNum;
float destOldMax;
float destNewMax;
int remain = dimsize % maxNum;
int repeat = (dimsize - remain)/maxNum;
int otherRemain = othersize % taskDim;
int stepEasy = (othersize - otherRemain) / taskDim;
int stepHard = stepEasy + 1;
int step = (taskId < otherRemain ? stepHard : stepEasy);
int startHard = taskId * stepHard;
int startEasy = otherRemain * stepHard + (taskId - otherRemain) * stepEasy;
int indStart = (taskId < otherRemain ? startHard : startEasy);
source = source + indStart * dimsize;
destination = destination + indStart * dimsize;
for(int s = 0; s < step; s++){
destOldMax = -INFINITY;
destNewMax = -INFINITY;
__bang_write_zero(destSum, maxNum);
for(int i = 0; i < repeat + 1; i++){
if(i < repeat){
__memcpy_async(src + i % 2 * maxNum, source + s * dimsize + i * maxNum, maxNum * sizeof(float), GDRAM2NRAM);
}
if(i > 0){
__bang_argmax(srcMax, src + (i - 1) % 2 * maxNum, maxNum);
if(destNewMax < srcMax[0]){
destNewMax = srcMax[0];
}
__bang_sub_scalar(src + (i - 1) % 2 * maxNum, src + (i - 1) % 2 * maxNum, destNewMax, maxNum);
__bang_active_exp_less_0(src + (i - 1) % 2 * maxNum, src + (i - 1) % 2 * maxNum, maxNum);
if(i > 1){
__bang_mul_scalar(destSum, destSum, exp(destOldMax - destNewMax), maxNum);
}
__bang_add(destSum, destSum, src + (i - 1) % 2 * maxNum, maxNum);
destOldMax = destNewMax;
}
__sync_all_ipu();
}
//------------
if(remain){
__bang_write_value(src, maxNum, -INFINITY);
__memcpy(src, source + s * dimsize + repeat * maxNum, remain * sizeof(float), GDRAM2NRAM);
__bang_argmax(srcMax, src, maxNum);
if(destNewMax < srcMax[0]){
destNewMax = srcMax[0];
}
__bang_sub_scalar(src, src, destNewMax, maxNum);
__bang_active_exp_less_0(src, src, maxNum);
if(repeat > 0){
__bang_mul_scalar(destSum, destSum, exp(destOldMax - destNewMax), maxNum);
}
__bang_add(destSum, destSum, src, maxNum);
destOldMax = destNewMax;
}
//--------------
//--------------------------------
int segNum = maxNum / wSize;
for(int strip = segNum/2; strip > 0; strip = strip / 2){
for(int i = 0; i < strip ; i++){
__bang_add(destSum + i * wSize, destSum + i * wSize, destSum + (i + strip) * wSize, wSize);
}
}
__bang_reduce_sum(destSumFinal, destSum, wSize);
//-----------
float globalSumInv = 1.0/destSumFinal[0];
for(int i = 0; i < repeat + 2; i++){
if(i < repeat){
__memcpy_async(src + i % 3 * maxNum, source + s * dimsize + i * maxNum, maxNum * sizeof(float), GDRAM2NRAM);
}
if(i > 0 && i < repeat + 1){
__bang_sub_scalar(src + (i - 1) % 3 * maxNum, src + (i - 1) % 3 * maxNum, destNewMax, maxNum);
__bang_active_exp_less_0(src + (i - 1) % 3 * maxNum, src + (i - 1) % 3 * maxNum, maxNum);
__bang_mul_scalar(src + (i - 1) % 3 * maxNum, src + (i - 1) % 3 * maxNum, globalSumInv, maxNum);
}
if(i > 1){
__memcpy_async(destination + s * dimsize + (i - 2) * maxNum, src + (i - 2) % 3 * maxNum, maxNum * sizeof(float), NRAM2GDRAM);
}
__sync_all_ipu();
}
if(remain){
__bang_write_value(src, maxNum, destNewMax);
__memcpy(src, source + s * dimsize + repeat * maxNum, remain * sizeof(float), GDRAM2NRAM);
__bang_sub_scalar(src, src, destNewMax, maxNum);
__bang_active_exp_less_0(src, src, maxNum);
__bang_mul_scalar(src, src, globalSumInv, maxNum);
__memcpy(destination + s * dimsize + repeat * maxNum, src, remain * sizeof(float), NRAM2GDRAM);
}
}
}
else{
int multiple = maxNum / dimsize;//一个src可以处理multiple个otherIdx
int size = taskDim * multiple;//所有core可以处理size个otherIdx
int remain = othersize % size;// remain < taskDim * multiple
int repeat = (othersize - remain) / size;
int remainT = remain % taskDim;
int stepEasy = (remain - remainT) / taskDim;
int stepHard = stepEasy + 1;
int step = (taskId < remainT ? stepHard : stepEasy);
int startHard = taskId * stepHard * dimsize;//前面remainT个taskId分配到stepHard个dimsize
int startEasy = remainT * stepHard * dimsize + (taskId - remainT) * stepEasy * dimsize;
int indStart = (taskId < remainT ? startHard : startEasy);
//-----------------------------------------allocate memory
float* src = nram_buffer;//src[maxNum]
float* tmp = src + 3 * maxNum;//tmp[dimS]
float* destSum = tmp + dimS;//destSum[dimS],dimS >= max(dimsize, wSize), dimS = pow(2,K) ,pow(2,K - 1) < dimsize
float* destSumFinal = destSum + wSize;
//-----------------------------------------
//printf("taskId:%d, repeat:%d, step:%d, repeatDim:%d, indstart:%d, %d\n", taskId, repeat, step, repeatDim, indStart, indStart * dimsize);
int tid;
__bang_write_value(tmp, dimS, -INFINITY);
__bang_write_zero(destSum, dimS);
if(repeat >= 2){
int s = 0;
tid = s * size * dimsize + taskId * multiple * dimsize;
__memcpy(src + s % 3 * maxNum, source + tid, multiple * dimsize * sizeof(float), GDRAM2NRAM);
s = 1;
tid = s * size * dimsize + taskId * multiple * dimsize;
__memcpy_async(src + s % 3 * maxNum, source + tid, multiple * dimsize * sizeof(float), GDRAM2NRAM);
// compute ------------------------
for(int j = 0; j < multiple; j++){
__memcpy(tmp, src + (s - 1) %3 * maxNum + j * dimsize, dimsize * sizeof(float), NRAM2NRAM);
__bang_argmax(srcMax, tmp, dimS);
__bang_sub_scalar(tmp, tmp, srcMax[0], dimS);
__memcpy(src + (s - 1) %3 * maxNum + j * dimsize, tmp, dimsize * sizeof(float), NRAM2NRAM);
}
__bang_active_exp_less_0(src + (s - 1) %3 * maxNum, src + (s - 1) %3 * maxNum, maxNum);
for(int j = 0; j < multiple; j++){
__memcpy(destSum, src + (s - 1) %3 * maxNum + j * dimsize, dimsize * sizeof(float), NRAM2NRAM);
__memcpy(tmp, destSum, dimsize * sizeof(float), NRAM2NRAM);
int segNum = dimS / wSize;//Starting numerical summation
for(int strip = segNum/2; strip > 0; strip = strip / 2){
for(int i = 0; i < strip ; i++){
__bang_add(destSum + i * wSize, destSum + i * wSize, destSum + (i + strip) * wSize, wSize);
}
}
__bang_reduce_sum(destSumFinal, destSum, wSize);
float globalSumInv = 1.0/destSumFinal[0];
__bang_mul_scalar(tmp, tmp, globalSumInv, dimS);
__memcpy(src + (s - 1) %3 * maxNum + j * dimsize, tmp, dimsize * sizeof(float), NRAM2NRAM);
}
// compute ------------------------
for(int s = 2; s < repeat; s++){
tid = (s - 2) * size * dimsize + taskId * multiple * dimsize;
__memcpy_async(destination + tid, src + (s - 2) % 3 * maxNum, multiple * dimsize * sizeof(float), NRAM2GDRAM);
tid = s * size * dimsize + taskId * multiple * dimsize;
__memcpy_async(src + s % 3 * maxNum, source + tid, multiple * dimsize * sizeof(float), GDRAM2NRAM);
// compute ------------------------
__bang_argmax(srcMax, src + (s - 1) %3 * maxNum, maxNum);//这一段特殊处理取全局max
__bang_sub_scalar(src + (s - 1) %3 * maxNum, src + (s - 1) %3 * maxNum, srcMax[0], maxNum);
__bang_active_exp_less_0(src + (s - 1) %3 * maxNum, src + (s - 1) %3 * maxNum, maxNum);
for(int j = 0; j < multiple; j++){
__memcpy(destSum, src + (s - 1) %3 * maxNum + j * dimsize, dimsize * sizeof(float), NRAM2NRAM);
__memcpy(tmp, destSum, dimsize * sizeof(float), NRAM2NRAM);
int segNum = dimS / wSize;//Starting numerical summation
for(int strip = segNum/2; strip > 0; strip = strip / 2){
for(int i = 0; i < strip ; i++){
__bang_add(destSum + i * wSize, destSum + i * wSize, destSum + (i + strip) * wSize, wSize);
}
}
__bang_reduce_sum(destSumFinal, destSum, wSize);
float globalSumInv = 1.0/destSumFinal[0];
__bang_mul_scalar(tmp, tmp, globalSumInv, dimS);
__memcpy(src + (s - 1) %3 * maxNum + j * dimsize, tmp, dimsize * sizeof(float), NRAM2NRAM);
}
// compute ------------------------
}
s = repeat;
tid = (s - 2) * size * dimsize + taskId * multiple * dimsize;
__memcpy_async(destination + tid, src + (s - 2) % 3 * maxNum, multiple * dimsize * sizeof(float), NRAM2GDRAM);
// compute ------------------------
for(int j = 0; j < multiple; j++){
__memcpy(tmp, src + (s - 1) %3 * maxNum + j * dimsize, dimsize * sizeof(float), NRAM2NRAM);
__bang_argmax(srcMax, tmp, dimS);
__bang_sub_scalar(tmp, tmp, srcMax[0], dimS);
__memcpy(src + (s - 1) %3 * maxNum + j * dimsize, tmp, dimsize * sizeof(float), NRAM2NRAM);
}
__bang_active_exp_less_0(src + (s - 1) %3 * maxNum, src + (s - 1) %3 * maxNum, maxNum);
for(int j = 0; j < multiple; j++){
__memcpy(destSum, src + (s - 1) %3 * maxNum + j * dimsize, dimsize * sizeof(float), NRAM2NRAM);
__memcpy(tmp, destSum, dimsize * sizeof(float), NRAM2NRAM);
int segNum = dimS / wSize;//Starting numerical summation
for(int strip = segNum/2; strip > 0; strip = strip / 2){
for(int i = 0; i < strip ; i++){
__bang_add(destSum + i * wSize, destSum + i * wSize, destSum + (i + strip) * wSize, wSize);
}
}
__bang_reduce_sum(destSumFinal, destSum, wSize);
float globalSumInv = 1.0/destSumFinal[0];
__bang_mul_scalar(tmp, tmp, globalSumInv, dimS);
__memcpy(src + (s - 1) %3 * maxNum + j * dimsize, tmp, dimsize * sizeof(float), NRAM2NRAM);
}
// compute ------------------------
s = repeat + 1;
tid = (s - 2) * size * dimsize + taskId * multiple * dimsize;
__memcpy(destination + tid, src + (s - 2) % 3 * maxNum, multiple * dimsize * sizeof(float), NRAM2GDRAM);
}
else{
for(int s = 0; s < repeat + 2; s++){
if(s < repeat){
tid = s * size * dimsize + taskId * multiple * dimsize;
__memcpy_async(src + s % 3 * maxNum, source + tid, multiple * dimsize * sizeof(float), GDRAM2NRAM);
}
if(s > 0 && s < repeat + 1){
// compute ------------------------
for(int j = 0; j < multiple; j++){
__memcpy(tmp, src + (s - 1) %3 * maxNum + j * dimsize, dimsize * sizeof(float), NRAM2NRAM);
__bang_argmax(srcMax, tmp, dimS);
__bang_sub_scalar(tmp, tmp, srcMax[0], dimS);
__memcpy(src + (s - 1) %3 * maxNum + j * dimsize, tmp, dimsize * sizeof(float), NRAM2NRAM);
}
__bang_active_exp_less_0(src + (s - 1) %3 * maxNum, src + (s - 1) %3 * maxNum, maxNum);
for(int j = 0; j < multiple; j++){
__memcpy(destSum, src + (s - 1) %3 * maxNum + j * dimsize, dimsize * sizeof(float), NRAM2NRAM);
__memcpy(tmp, destSum, dimsize * sizeof(float), NRAM2NRAM);
int segNum = dimS / wSize;//Starting numerical summation
for(int strip = segNum/2; strip > 0; strip = strip / 2){
for(int i = 0; i < strip ; i++){
__bang_add(destSum + i * wSize, destSum + i * wSize, destSum + (i + strip) * wSize, wSize);
}
}
__bang_reduce_sum(destSumFinal, destSum, wSize);
float globalSumInv = 1.0/destSumFinal[0];
__bang_mul_scalar(tmp, tmp, globalSumInv, dimS);
__memcpy(src + (s - 1) %3 * maxNum + j * dimsize, tmp, dimsize * sizeof(float), NRAM2NRAM);
}
// compute ------------------------
}
if(s > 1){
tid = (s - 2) * size * dimsize + taskId * multiple * dimsize;
__memcpy_async(destination + tid, src + (s - 2) % 3 * maxNum, multiple * dimsize * sizeof(float), NRAM2GDRAM);
}
__sync_all_ipu();//如果maxNum比较小,此时访存时间>计算时间,无法延迟
}
}
if(step){
tid = repeat * size * dimsize + indStart;
__memcpy(src, source + tid, step * dimsize * sizeof(float), GDRAM2NRAM);
for(int s = 0; s < step; s++){//Step targets parts of othersize that cannot be divided by multiple * dimsize
__bang_write_zero(destSum, dimS);
__bang_write_value(tmp, dimS, -INFINITY);
__memcpy(tmp, src + s * dimsize, dimsize * sizeof(float), NRAM2NRAM);
__bang_argmax(srcMax, tmp, dimS);
__bang_sub_scalar(tmp, tmp, srcMax[0], dimS);
__bang_active_exp_less_0(tmp, tmp, dimS);
__memcpy(destSum, tmp, dimsize * sizeof(float), NRAM2NRAM);
int segNum = dimS / wSize;
for(int strip = segNum/2; strip > 0; strip = strip / 2){
for(int i = 0; i < strip ; i++){
__bang_add(destSum + i * wSize, destSum + i * wSize, destSum + (i + strip) * wSize, wSize);
}
}
__bang_reduce_sum(destSumFinal, destSum, wSize);
float globalSumInv = 1.0/destSumFinal[0];
__bang_mul_scalar(tmp, tmp, globalSumInv, dimS);
__memcpy(src + s * dimsize, tmp, dimsize * sizeof(float), NRAM2NRAM);
}
__memcpy(destination + tid, src, step * dimsize * sizeof(float), NRAM2GDRAM);
}
}
}
__mlu_device__ void softmaxKernelAxis_s(float* destination, float* source, int othersize, int dimsize, int stride) {// axis = 0
const int SRC_MAX_SIZE = 1024 * 64;//The subsequent tree summation must ensure that SRC-MAX-SIZE is a power of 2
const int maxNum = SRC_MAX_SIZE/sizeof(float);
//-----------------------------------------allocate memory
float* src = nram_buffer;// src[3 * maxNum]
float* tmpSum = src + 3 * maxNum;//tmpSum[maxNum]
float* tmpNewMax = src + 4 * maxNum;//tmpNewMax[maxNum]
float* tmpOldMax = src + 5 * maxNum;//tmpOldMax[maxNum]
//-----------------------------------------
int remain = othersize % taskDim;
int stepEasy = (othersize - remain)/taskDim;
int stepHard = stepEasy + 1;
int step = (taskId < remain ? stepHard : stepEasy);//The first part of taskId handles an additional element
int indStart = (taskId < remain ? taskId * stepHard : remain * stepHard + (taskId - remain) * stepEasy);
int remainNram = step%maxNum;
int repeat = (step - remainNram)/maxNum;
//__bang_printf("taskId:%d, repeat:%d, step:%d, indStart:%d, remainNram:%d\n", taskId, repeat, step, indStart, remainNram);
for(int j = 0; j < repeat; j++){
__bang_write_value(tmpNewMax, maxNum, -INFINITY);
__bang_write_zero(tmpSum, maxNum);
for(int i = 0; i < dimsize + 1; i++){
if(i < dimsize){
__memcpy_async(src + i % 2 * maxNum, source + i * stride + indStart + j * maxNum, maxNum * sizeof(float), GDRAM2NRAM);
}
if(i > 0){
__bang_maxequal(tmpNewMax, tmpNewMax, src + (i - 1) % 2 * maxNum, maxNum);//Continuously updating the maximum value
__bang_sub(src + (i - 1) % 2 * maxNum, src + (i - 1) % 2 * maxNum, tmpNewMax, maxNum);//x - M
__bang_active_exp_less_0(src + (i - 1) % 2 * maxNum, src + (i - 1) % 2 * maxNum, maxNum);//exp(x - M)
if(i > 1){
__bang_sub(tmpOldMax, tmpOldMax, tmpNewMax, maxNum);//oldM = oldM - newM
__bang_active_exp_less_0(tmpOldMax, tmpOldMax, maxNum);//exp(oldM - newM)
__bang_mul(tmpSum, tmpSum, tmpOldMax, maxNum);//sum = sum * exp(oldM - newM)
}
__bang_add(tmpSum, tmpSum, src + (i - 1) % 2 * maxNum, maxNum);//sum += exp(x - M)
__memcpy(tmpOldMax, tmpNewMax, maxNum * sizeof(float), NRAM2NRAM);//oldM = newM
}
__sync_all_ipu();
}
__bang_active_reciphp(tmpSum, tmpSum, maxNum);//compute 1/sum
//Start exponential transformation and write back to GDRAM
for(int i = 0; i < dimsize + 2; i++){
if(i < dimsize){
__memcpy_async(src + i % 3 * maxNum, source + i * stride + indStart + j * maxNum, maxNum * sizeof(float), GDRAM2NRAM);
}
if(i > 0 && i < dimsize + 1){
__bang_sub(src + (i - 1) % 3 * maxNum, src + (i - 1) % 3 * maxNum, tmpNewMax, maxNum);//x - M
__bang_active_exp_less_0(src + (i - 1) % 3 * maxNum, src + (i - 1) % 3 * maxNum, maxNum);//exp(x - M)
__bang_mul(src + (i - 1) % 3 * maxNum, src + (i - 1) % 3 * maxNum, tmpSum, maxNum);
}
if(i > 1){
__memcpy_async(destination + (i - 2) * stride + indStart + j * maxNum, src + (i - 2) % 3 * maxNum, maxNum * sizeof(float), NRAM2GDRAM);
}
__sync_all_ipu();
}
}
if(remainNram){
__bang_write_value(tmpNewMax, maxNum, -INFINITY);
__bang_write_zero(tmpSum, maxNum);
__bang_write_zero(src, 3 * maxNum);
for(int i = 0; i < dimsize + 1; i++){
if(i < dimsize){
__memcpy_async(src + i % 2 * maxNum, source + i * stride + indStart + repeat * maxNum, remainNram * sizeof(float), GDRAM2NRAM);
}
if(i > 0){
__bang_maxequal(tmpNewMax, tmpNewMax, src + (i - 1) % 2 * maxNum, maxNum);
__bang_sub(src + (i - 1) % 2 * maxNum, src + (i - 1) % 2 * maxNum, tmpNewMax, maxNum);//x - M
__bang_active_exp_less_0(src + (i - 1) % 2 * maxNum, src + (i - 1) % 2 * maxNum, maxNum);//exp(x - M)
if(i > 1){
__bang_sub(tmpOldMax, tmpOldMax, tmpNewMax, maxNum);//oldM = oldM - newM
__bang_active_exp_less_0(tmpOldMax, tmpOldMax, maxNum);//exp(oldM - newM)
__bang_mul(tmpSum, tmpSum, tmpOldMax, maxNum); //sum = sum * exp(oldM - newM)
}
__bang_add(tmpSum, tmpSum, src + (i - 1) % 2 * maxNum, maxNum);//sum += exp(x - M)
__memcpy(tmpOldMax, tmpNewMax, maxNum * sizeof(float), NRAM2NRAM);//oldM = newM
}
__sync_all_ipu();
}
__bang_active_reciphp(tmpSum, tmpSum, maxNum);//compute 1/sum
//Start exponential transformation and write back to GDRAM
for(int i = 0; i < dimsize + 2; i++){
if(i < dimsize){
__memcpy_async(src + i % 3 * maxNum, source + i * stride + indStart + repeat * maxNum, remainNram * sizeof(float), GDRAM2NRAM);
}
if(i > 0 && i < dimsize + 1){
__bang_sub(src + (i - 1) % 3 * maxNum, src + (i - 1) % 3 * maxNum, tmpNewMax, maxNum);//x - M
__bang_active_exp_less_0(src + (i - 1) % 3 * maxNum, src + (i - 1) % 3 * maxNum, maxNum);//exp(x - M)
__bang_mul(src + (i - 1) % 3 * maxNum, src + (i - 1) % 3 * maxNum, tmpSum, maxNum);
}
if(i > 1){
__memcpy_async(destination + (i - 2) * stride + indStart + repeat * maxNum, src + (i - 2) % 3 * maxNum, remainNram * sizeof(float), NRAM2GDRAM);
}
__sync_all_ipu();
}
}
}
__mlu_device__ void softmaxKernelAxis_m(float* destination, float* source, int frontsize, int dimsize, int stride, int strideS) {
// 0<axis<dim -1
const int SRC_MAX_SIZE = 1024 * 64;//The subsequent tree summation must ensure that SRC-MAX-SIZE is a power of 2
const int maxNum = SRC_MAX_SIZE/sizeof(float);
if(stride >= maxNum){
//-----------------------------------------allocate memory
float *src = nram_buffer;
float *tmpSum = src + 3 * maxNum;
float *tmpNewMax = tmpSum + maxNum;
float *tmpOldMax = tmpNewMax + maxNum;
//-----------------------------------------
int remain = stride % maxNum;
int repeat = (stride - remain) / maxNum;
for(int ind = taskId; ind < frontsize; ind += taskDim){
int frontIdx = ind * dimsize * stride;
for(int j = 0; j < repeat; j++){
__bang_write_value(tmpNewMax, maxNum, -INFINITY);
__bang_write_zero(tmpSum, maxNum);
//__bang_write_zero(src, maxNum);
for(int i = 0; i < dimsize; i++){
__memcpy(src, source + frontIdx + i * stride + j * maxNum, maxNum * sizeof(float), GDRAM2NRAM);
__bang_maxequal(tmpNewMax, tmpNewMax, src, maxNum);//Continuously updating the maximum value
__bang_sub(src, src, tmpNewMax, maxNum);//x - M
__bang_active_exp_less_0(src, src, maxNum);//exp(x - M)
if(i > 0){
__bang_sub(tmpOldMax, tmpOldMax, tmpNewMax, maxNum);//oldM = oldM - newM
__bang_active_exp_less_0(tmpOldMax, tmpOldMax, maxNum);//exp(oldM - newM)
__bang_mul(tmpSum, tmpSum, tmpOldMax, maxNum);//sum = sum * exp(oldM - newM)
}
__bang_add(tmpSum, tmpSum, src, maxNum);//sum += exp(x - M)
__memcpy(tmpOldMax, tmpNewMax, maxNum * sizeof(float), NRAM2NRAM);//oldM = newM
}
__bang_active_reciphp(tmpSum, tmpSum, maxNum);//计算1/sum
//Start exponential transformation and write back to GDRAM
__bang_mul(src, src, tmpSum, maxNum);//The data stored in the src at the end of the loop above can be utilized
__memcpy(destination + (dimsize - 1) * stride + frontIdx + j * maxNum, src, maxNum * sizeof(float), NRAM2GDRAM);
for(int i = 0; i < dimsize - 1; i++){
__memcpy(src, source + frontIdx + i * stride + j * maxNum, maxNum * sizeof(float), GDRAM2NRAM);
__bang_sub(src, src, tmpNewMax, maxNum);//x - M
__bang_active_exp_less_0(src, src, maxNum);//exp(x - M)
__bang_mul(src, src, tmpSum, maxNum);
__memcpy(destination + frontIdx + i * stride + j * maxNum, src, maxNum * sizeof(float), NRAM2GDRAM);
}
}
if(remain){
__bang_write_value(tmpNewMax, maxNum, -INFINITY);
__bang_write_zero(tmpSum, maxNum);
__bang_write_value(src, maxNum, -INFINITY);
for(int i = 0; i < dimsize; i++){
__memcpy(src, source + frontIdx + i * stride + repeat * maxNum, remain * sizeof(float), GDRAM2NRAM);
__bang_maxequal(tmpNewMax, tmpNewMax, src, maxNum);
__bang_sub(src, src, tmpNewMax, maxNum);//x - M
__bang_active_exp_less_0(src, src, maxNum);//exp(x - M)
if(i > 0){
__bang_sub(tmpOldMax, tmpOldMax, tmpNewMax, maxNum);//oldM = oldM - newM
__bang_active_exp_less_0(tmpOldMax, tmpOldMax, maxNum);//exp(oldM - newM)
__bang_mul(tmpSum, tmpSum, tmpOldMax, maxNum); //sum = sum * exp(oldM - newM)
}
__bang_add(tmpSum, tmpSum, src, maxNum);//sum += exp(x - M)
__memcpy(tmpOldMax, tmpNewMax, maxNum * sizeof(float), NRAM2NRAM);//oldM = newM
}
//-------------------
__bang_active_reciphp(tmpSum, tmpSum, maxNum);//计算1/sum
//Start exponential transformation and write back to GDRAM
__bang_mul(src, src, tmpSum, maxNum);//The data stored in the src at the end of the loop above can be utilized
__memcpy(destination + (dimsize - 1) * stride + frontIdx + repeat * maxNum, src, remain * sizeof(float), NRAM2GDRAM);
for(int i = 0; i < dimsize - 1; i++){
__memcpy(src, source + i * stride + frontIdx + repeat * maxNum, remain * sizeof(float), GDRAM2NRAM);
__bang_sub(src, src, tmpNewMax, maxNum);//x - M
__bang_active_exp_less_0(src, src, maxNum);//exp(x - M)
__bang_mul(src, src, tmpSum, maxNum);
__memcpy(destination + i * stride + frontIdx + repeat * maxNum, src, remain * sizeof(float), NRAM2GDRAM);
}
//---------------------
}
}
}
else if(stride < maxNum && dimsize * stride >= maxNum){
//-----------------------------------------allocate memory
float* src = nram_buffer;
float* tmp = src + 3 * maxNum;
float* tmpOldMax = tmp + strideS;
float* tmpNewMax = tmpOldMax + strideS;
float* tmpSum = tmpNewMax + strideS;
//-----------------------------------------
int multiple = maxNum / stride;
int size = multiple * stride;//The maximum amount of data that can be stored in an SRC
int remain = dimsize % multiple;//If it cannot be divisible, this part of the data needs special processing
int repeat = (dimsize - remain) / multiple;//The total number of loops required to load the entire dimsize
int taskRemain = frontsize % taskDim;
int stepEasy = (frontsize - taskRemain) / taskDim;
int stepHard = stepEasy + 1;
int step = (taskId < taskRemain ? stepHard : stepEasy);//The number of frontsize processed per taskId
int indStart = (taskId < taskRemain ? taskId * stepHard : taskRemain * stepHard + (taskId - taskRemain) * stepEasy);
source = source + indStart * dimsize * stride;
destination = destination + indStart * dimsize * stride;
//printf("maxNum:%d, dimsize * stride:%d, multiple:%d, size:%d, repeat:%d,remain:%d\n",maxNum, dimsize * stride, multiple, size, repeat,remain);
for(int ind = 0; ind < step; ind++){
int frontIdx = ind * dimsize * stride;
__bang_write_value(tmpNewMax, strideS, -INFINITY);//Must be initialized to negative infinity
__bang_write_value(tmp, strideS, -INFINITY);//Must be initialized to negative infinity
__bang_write_zero(tmpSum, strideS);//Must be initialized to zero
for(int j = 0; j < repeat + 1; j++){
if(j < repeat){
__memcpy_async(src + j % 2 * maxNum, source + frontIdx + j * multiple * stride, size * sizeof(float), GDRAM2NRAM);
}
if(j > 0){
for(int m = 0; m < multiple; m++){
__memcpy(tmp, src + (j - 1) % 2 * maxNum + m * stride, stride * sizeof(float), NRAM2NRAM);
__bang_maxequal(tmpNewMax, tmpNewMax, tmp, strideS);//Although the stream S stream section after tmpNewMax is 0, there is no need to write back to GDRAM, which does not affect the result
__bang_sub(tmp, tmp, tmpNewMax, strideS);//The stripe S stripe section after tmp is 0
__bang_active_exp_less_0(tmp, tmp, strideS);
if(j != 1 || m != 0){
__bang_sub(tmpOldMax, tmpOldMax, tmpNewMax, strideS);//oldM = oldM - newM
__bang_active_exp_less_0(tmpOldMax, tmpOldMax, strideS);//exp(oldM - newM)
__bang_mul(tmpSum, tmpSum, tmpOldMax, strideS);//sum = sum * exp(oldM - newM)
}
__bang_add(tmpSum, tmpSum, tmp, strideS);//sum += exp(x - M)
__memcpy(tmpOldMax, tmpNewMax, stride * sizeof(float), NRAM2NRAM);//oldM = newM
}
}
__sync_all_ipu();
}
if(remain){
__memcpy(src, source + frontIdx + repeat * multiple * stride, remain * stride * sizeof(float), GDRAM2NRAM);
for(int m = 0; m < remain; m++){
__memcpy(tmp, src + m * stride, stride * sizeof(float), NRAM2NRAM);
__bang_maxequal(tmpNewMax, tmpNewMax, tmp, strideS);
__bang_sub(tmp, tmp, tmpNewMax, strideS);//The stripe S stripe section after tmp is 0
__bang_active_exp_less_0(tmp, tmp, strideS);
if(repeat != 0 || m != 0){
__bang_sub(tmpOldMax, tmpOldMax, tmpNewMax, strideS);//oldM = oldM - newM
__bang_active_exp_less_0(tmpOldMax, tmpOldMax, strideS);//exp(oldM - newM)
__bang_mul(tmpSum, tmpSum, tmpOldMax, strideS);//sum = sum * exp(oldM - newM)
}
__bang_add(tmpSum, tmpSum, tmp, strideS);//sum += exp(x - M)
__memcpy(tmpOldMax, tmpNewMax, stride * sizeof(float), NRAM2NRAM);//oldM = newM
}
}
//At this point, tmpNewMax stores the maximum value of the data corresponding to a fixed frontIdx and bedsize, while tmpSum stores the corresponding value sum
__bang_active_reciphp(tmpSum, tmpSum, strideS);
if(remain){
for(int m = 0; m < remain; m++){
__memcpy(tmp, src + m * stride, stride * sizeof(float), NRAM2NRAM);
__bang_sub(tmp, tmp, tmpNewMax, strideS);
__bang_active_exp_less_0(tmp, tmp, strideS);
__bang_mul(tmp, tmp, tmpSum, strideS);
__memcpy(destination + frontIdx + repeat * multiple * stride + m * stride, tmp, stride * sizeof(float), NRAM2GDRAM);
}
}
for(int j = 0 ; j < repeat + 2; j++){
if(j < repeat){
__memcpy_async(src + j % 3 * maxNum, source + frontIdx + j * multiple * stride, size * sizeof(float), GDRAM2NRAM);
}
if(j > 0 && j < repeat + 1){
for(int m = 0; m < multiple; m++){
__memcpy(tmp, src + (j - 1) % 3 * maxNum + m * stride, stride * sizeof(float), NRAM2NRAM);
__bang_sub(tmp, tmp, tmpNewMax, strideS);
__bang_active_exp_less_0(tmp, tmp, strideS);
__bang_mul(tmp, tmp, tmpSum, strideS);
__memcpy(src + (j - 1) % 3 * maxNum + m * stride, tmp, stride * sizeof(float), NRAM2NRAM);
}
}
if(j > 1){
__memcpy_async(destination + frontIdx + (j - 2) * multiple * stride, src + (j - 2) % 3 * maxNum, size * sizeof(float), NRAM2GDRAM);
}
__sync_all_ipu();
}
}
}
else if(dimsize * stride < maxNum){
//-----------------------------------------allocate memory
float* src = nram_buffer;
float* tmp = src + 3 * maxNum;
float* tmpOldMax = tmp + strideS;
float* tmpNewMax = tmpOldMax + strideS;
float* tmpSum = tmpNewMax + strideS;
//-----------------------------------------
int behindsize = dimsize * stride;
int multiple = maxNum / behindsize;//Represents the amount that a maxNum can share in frontsize
int remainF = frontsize % (taskDim * multiple);
int remainT = remainF % taskDim;
int stepEasy = (remainF - remainT) / taskDim;
int stepHard = stepEasy + 1;
int step = (taskId < remainT ? stepHard : stepEasy);
int taskRepeat = (frontsize - remainF) / (taskDim * multiple);
//At this point, corresponding to frontsize, the amount of data processed by each taskId is taskRepeat * multiple+step
int startHard = taskId * (taskRepeat * multiple + stepHard);
int startEasy = remainT * (taskRepeat * multiple + stepHard) + (taskId - remainT) * (taskRepeat * multiple + stepEasy);
int indStart = (taskId < remainT ? startHard: startEasy);
source = source + indStart * behindsize;//indStart * behindsize Indicates the offset corresponding to different taskIds
destination = destination + indStart * behindsize;
int tid;
for(int s = 0; s < taskRepeat + 2; s++){
if(s < taskRepeat){
tid = s * multiple * behindsize;
__memcpy_async(src + s % 3 * maxNum, source + tid, multiple * behindsize * sizeof(float), GDRAM2NRAM);
}
if(s > 0 && s < taskRepeat + 1){
for(int m = 0; m < multiple; m++){
__bang_write_zero(tmpSum, strideS);
__bang_write_value(tmp, strideS, -INFINITY);
__bang_write_value(tmpNewMax, strideS, -INFINITY);
for(int i = 0; i < dimsize; i++){
__memcpy(tmp, src + (s - 1) % 3 * maxNum + m * behindsize + i * stride, stride * sizeof(float), NRAM2NRAM);
__bang_maxequal(tmpNewMax, tmpNewMax, tmp, strideS);
__bang_sub(tmp, tmp, tmpNewMax, strideS);//x - M
__bang_active_exp_less_0(tmp, tmp, strideS);//exp(x - M)
if(i > 0){
__bang_sub(tmpOldMax, tmpOldMax, tmpNewMax, strideS);//oldM = oldM - newM
__bang_active_exp_less_0(tmpOldMax, tmpOldMax, strideS);//exp(oldM - newM)
__bang_mul(tmpSum, tmpSum, tmpOldMax, strideS); //sum = sum * exp(oldM - newM)
}
__bang_add(tmpSum, tmpSum, tmp, strideS);//sum += exp(x - M)
__memcpy(tmpOldMax, tmpNewMax, stride * sizeof(float), NRAM2NRAM);//oldM = newM
}
__bang_active_reciphp(tmpSum, tmpSum, strideS);
__bang_mul(tmp, tmp, tmpSum, strideS);//The data stored in tmp at the end of the loop above can be utilized
__memcpy(src + (s - 1) % 3 * maxNum + m * behindsize + (dimsize - 1) * stride, tmp, stride * sizeof(float), NRAM2NRAM);
for(int i = 0; i < dimsize - 1; i++){
__memcpy(tmp, src + (s - 1) % 3 * maxNum + m * behindsize + i * stride, stride * sizeof(float), NRAM2NRAM);
__bang_sub(tmp, tmp, tmpNewMax, strideS);//x - M
__bang_active_exp_less_0(tmp, tmp, strideS);//exp(x - M)
__bang_mul(tmp, tmp, tmpSum, strideS);
__memcpy(src + (s - 1) % 3 * maxNum + m * behindsize + i * stride, tmp, stride * sizeof(float), NRAM2NRAM);
}
}
}
if(s > 1){
tid = (s - 2) * multiple * behindsize;
__memcpy_async(destination + tid, src + (s - 2) % 3 * maxNum, multiple * behindsize * sizeof(float), NRAM2GDRAM);
}
__sync_all_ipu();
}
//__bang_printf("taskId:%d, multiple:%d, taskRepeat:%d, step:%d, indStart:%d\n",taskId, multiple, taskRepeat, step, indStart * behindsize);
if(step){
tid = taskRepeat * multiple * behindsize;
__memcpy(src, source + tid, step * behindsize * sizeof(float), GDRAM2NRAM);
for(int m = 0; m < step; m++){
__bang_write_zero(tmpSum, strideS);
__bang_write_value(tmp, strideS, -INFINITY);
__bang_write_value(tmpNewMax, strideS, -INFINITY);
for(int i = 0; i < dimsize; i++){
__memcpy(tmp, src + m * behindsize + i * stride, stride * sizeof(float), NRAM2NRAM);
__bang_maxequal(tmpNewMax, tmpNewMax, tmp, strideS);
__bang_sub(tmp, tmp, tmpNewMax, strideS);//x - M
__bang_active_exp_less_0(tmp, tmp, strideS);//exp(x - M)
if(i > 0){
__bang_sub(tmpOldMax, tmpOldMax, tmpNewMax, strideS);//oldM = oldM - newM
__bang_active_exp_less_0(tmpOldMax, tmpOldMax, strideS);//exp(oldM - newM)
__bang_mul(tmpSum, tmpSum, tmpOldMax, strideS); //sum = sum * exp(oldM - newM)
}
__bang_add(tmpSum, tmpSum, tmp, strideS);//sum += exp(x - M)
__memcpy(tmpOldMax, tmpNewMax, stride * sizeof(float), NRAM2NRAM);//oldM = newM
}
//__bang_printf("max:%.2f,%.2f, sum:%.2f,sum:%.2f\n", tmpNewMax[0], tmpNewMax[1], tmpSum[0], tmpSum[0]);
__bang_active_reciphp(tmpSum, tmpSum, strideS);
__bang_mul(tmp, tmp, tmpSum, strideS);//The data stored in tmp at the end of the loop above can be utilized
//__memcpy(destination + tid + m * behindsize + (dimsize - 1) * stride, tmp, stride * sizeof(float), NRAM2GDRAM);
__memcpy(src + m * behindsize + (dimsize - 1) * stride, tmp, stride * sizeof(float), NRAM2NRAM);
for(int i = 0; i < dimsize - 1; i++){
__memcpy(tmp, src + m * behindsize + i * stride, stride * sizeof(float), NRAM2NRAM);
__bang_sub(tmp, tmp, tmpNewMax, strideS);//x - M
__bang_active_exp_less_0(tmp, tmp, strideS);//exp(x - M)
__bang_mul(tmp, tmp, tmpSum, strideS);
//__memcpy(destination + tid + m * behindsize + i * stride, tmp, stride * sizeof(float), NRAM2GDRAM);
__memcpy(src + m * behindsize + i * stride, tmp, stride * sizeof(float), NRAM2NRAM);
}
}
__memcpy(destination + tid, src, step * behindsize * sizeof(float), NRAM2GDRAM);
}
}
}
__mlu_global__ void softmaxUnion1(float *mlu_destination, float *mlu_src, int othersize, int dimsize, int frontsize, int stride, int axis, int nDim){
if(axis == nDim - 1){
int dimS;
float mi = log2(dimsize);
if (floor(mi) == mi)
{
dimS = dimsize;
}
else
{
dimS = pow(2, floor(mi) + 1);
}
if (dimS < wSize)
{
dimS = wSize;
}
softmaxKernelAxis_e(mlu_destination, mlu_src, othersize, dimsize, dimS);
}
else if(axis == 0){
softmaxKernelAxis_s(mlu_destination, mlu_src, othersize, dimsize, stride);
}
else{
float mi = log2(stride);
int strideS;
if(floor(mi) == mi){
strideS = stride;
}
else{
strideS = pow(2,floor(mi) + 1);
}
softmaxKernelAxis_m(mlu_destination, mlu_src, frontsize, dimsize, stride, strideS);
}
}
void softmaxParallel(float *host_destination, float *host_src, int axis, int nDim, int *shape){
int stride = 1;
int dimsize = shape[axis];
int num = 1;
int othersize = 1;
int frontsize = 1;
for (int s = nDim - 1; s >= 0; s--) {
num *= shape[s];
if (s > axis) {
stride *= shape[s];
}
if (s < axis) {
frontsize *= shape[s];
}
if (s != axis) {
othersize *= shape[s];
}
}
printf("num:%d, stride:%d, dimsize:%d\n", num, stride, dimsize);
cnrtQueue_t queue;
CNRT_CHECK(cnrtSetDevice(0));
CNRT_CHECK(cnrtQueueCreate(&queue));
cnrtDim3_t dim = {16, 1, 1};
cnrtFunctionType_t ktype = CNRT_FUNC_TYPE_UNION1;
cnrtNotifier_t start, end;
CNRT_CHECK(cnrtNotifierCreate(&start));
CNRT_CHECK(cnrtNotifierCreate(&end));
float *mlu_destination;
float *mlu_src;
CNRT_CHECK(cnrtMalloc((void **)&mlu_destination, num * sizeof(float)));
CNRT_CHECK(cnrtMalloc((void **)&mlu_src, num * sizeof(float)));
CNRT_CHECK(cnrtMemcpy(mlu_src, host_src, num * sizeof(float), cnrtMemcpyHostToDev));
//----------------------------
CNRT_CHECK(cnrtPlaceNotifier(start, queue));
softmaxUnion1<<<dim, ktype, queue>>>(mlu_destination, mlu_src, othersize, dimsize, frontsize, stride, axis, nDim);
CNRT_CHECK(cnrtPlaceNotifier(end, queue));
cnrtQueueSync(queue);
//---------------------------
CNRT_CHECK(cnrtMemcpy(host_destination, mlu_destination, num * sizeof(float), cnrtMemcpyDevToHost));
float timeTotal;
CNRT_CHECK(cnrtNotifierDuration(start, end, &timeTotal));
printf("Total Time: %.3f ms\n", timeTotal / 1000.0);
CNRT_CHECK(cnrtQueueDestroy(queue));
cnrtFree(mlu_destination);
cnrtFree(mlu_src);
}
include/softmax.h
#pragma once // 只编译一次
void softmaxParallel(float *host_destination, float *host_src, int axis, int nDim, int *shape);
void softmaxCnnl(float *host_destination, float *host_src, int nDim, int axis, int *shape);
CMakeLists.txt
cmake_minimum_required(VERSION 3.5)
project(softmax)
###############################################
include_directories("${CMAKE_CURRENT_SOURCE_DIR}/include")
set(EXECUTABLE_OUTPUT_PATH "${CMAKE_BINARY_DIR}/bin")
set(LIBRARY_OUTPUT_PATH "${CMAKE_BINARY_DIR}/lib")
set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -Werror -fPIC -std=c++11 -pthread -pipe")
set(CMAKE_CXX_FLAGS_RELEASE "${CMAKE_CXX_FLAGS_RELEASE} ${CMAKE_CXX_FLAGS} -O3")
set(CMAKE_EXE_LINKER_FLAGS_RELEASE "${CMAKE_EXE_LINKER_FLAGS_RELEASE} -Wl,--gc-sections -fPIC")
################################################################################
# Environment and BANG Setup
################################################################################
# check `NEUWARE_HOME` env
if(NOT DEFINED ENV{NEUWARE_HOME})
set(NEUWARE_HOME "/usr/local/neuware" CACHE PATH "Path to NEUWARE installation")
else()
set(NEUWARE_HOME $ENV{NEUWARE_HOME} CACHE PATH "Path to NEUWARE installation" FORCE)
endif()
message(${NEUWARE_HOME})
if(EXISTS ${NEUWARE_HOME})
include_directories("${NEUWARE_HOME}/include")
link_directories("${NEUWARE_HOME}/lib64")
link_directories("${NEUWARE_HOME}/lib")
set(NEUWARE_ROOT_DIR "${NEUWARE_HOME}")
else()
message(FATAL_ERROR "NEUWARE directory cannot be found, refer README.md to prepare NEUWARE_HOME environment.")
endif()
# setup cmake search path
set(CMAKE_MODULE_PATH ${CMAKE_MODULE_PATH}
"${NEUWARE_HOME}/cmake"
"${NEUWARE_HOME}/cmake/modules"
)
# include FindBANG.cmake and check cncc
find_package(BANG)
if(NOT BANG_FOUND)
message(FATAL_ERROR "BANG cannot be found.")
elseif (NOT BANG_CNCC_EXECUTABLE)
message(FATAL_ERROR "cncc not found, please ensure cncc is in your PATH env or set variable BANG_CNCC_EXECUTABLE from cmake. Otherwise you should check path used by find_program(BANG_CNCC_EXECUTABLE) in FindBANG.cmake")
endif()
# setup cncc flags
set(BANG_CNCC_FLAGS "${BANG_CNCC_FLAGS} -fPIC -Wall -Werror -std=c++11 -pthread")
set(BANG_CNCC_FLAGS "${BANG_CNCC_FLAGS} -O3")
set(BANG_CNCC_FLAGS "${BANG_CNCC_FLAGS}" "--bang-mlu-arch=mtp_372"
)
# build project
file(GLOB_RECURSE src_files
"${CMAKE_CURRENT_SOURCE_DIR}/src/*.mlu"
"${CMAKE_CURRENT_SOURCE_DIR}/src/*.cpp"
)
bang_add_executable(so ${src_files})
target_link_libraries(so cnnl cnnl_extra cnrt cndrv)
run.sh
rm -rf build
mkdir build
cd build
cmake ../
make
./bin/so


















 4023
4023

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











