






 大家好,我是HxShine
大家好,我是HxShine
今天分享DeepSeek R1 ,Title: DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning:通过强化学习激励LLM的推理能力。
这篇文章介绍了DeepSeek的第一代推理模型 DeepSeek-R1-Zero 和 DeepSeek-R1。DeepSeek-R1-Zero 模型通过大规模强化学习 (RL) 训练,没有监督微调 (SFT) 作为初步步骤,展示了RL的潜力及其带来的卓越的推理能力。 通过强化学习,DeepSeek-R1-Zero 自然而然地涌现出许多强大而有趣的推理行为。为了进一步优化R1-Zero存在的一些问题(语言混乱,综合能力提升),他们推出了 DeepSeek-R1,它在强化学习之前结合了多阶段训练和冷启动数据微调。 DeepSeek-R1 在推理任务上取得了与 OpenAI-01-1217 相媲美的性能。为了支持研究社区,他们开源了 DeepSeek-R1-Zero、DeepSeek-R1 以及六个从 DeepSeek-R1 提炼出来的密集模型(1.5B、7B、8B、14B、32B、70B),这些模型基于 Qwen 和 Llama。
该方法特点总结如下:
1)直接将强化学习应用于基础模型,无需依赖监督微调(SFT)作为初步步骤。
2)引入 DeepSeek-R1 开发流程,该流程结合了两个强化学习阶段和两个监督微调阶段,为模型的推理和非推理能力奠定基础。
3)通过蒸馏技术将大型模型的推理模式转移到小型模型中,提高了小型模型在推理任务上的性能。
一、概述
• Title: DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
• Authors: DeepSeek-AI
• Github: https://github.com/deepseek-ai/DeepSeek-R1
1 Motivation
• 当前的大型语言模型(LLMs)在推理任务上取得了显著进展,但仍然面临挑战。
• 纯粹的强化学习(RL)在提升LLMs推理能力方面的潜力尚未充分探索,尤其是在不依赖监督数据的情况下。
• 通过RL训练的模型,如DeepSeek-R1-Zero,在可读性和语言混合方面(例如中英文混着说)存在问题,需要进一步改进以提升用户友好性。
2 Methods
省流版总结:

DeepSeek-R1-Zero: 使用DeepSeek-V3-Base作为基础模型,采用GRPO(Group Relative Policy Optimization)作为强化学习框架,在没有监督数据的情况下提升模型在推理方面的性能。
DeepSeek-R1:
• 冷启动(Cold Start): 收集少量高质量的长CoT(Chain-of-Thought)数据,对DeepSeek-V3-Base模型进行微调,作为强化学习的初始actor。
• 面向推理的强化学习(Reasoning-oriented Reinforcement Learning): 应用与DeepSeek-R1-Zero相同的强化学习训练过程,但侧重于增强模型在编码、数学、科学和逻辑推理等方面的推理能力。引入语言一致性奖励,以减轻CoT中出现的语言混合问题。
• 拒绝抽样和监督微调(Rejection Sampling and Supervised Fine-Tuning): 利用强化学习收敛后的checkpoint收集SFT(Supervised Fine-Tuning)数据,用于后续训练。
• 所有场景的强化学习(Reinforcement Learning for all Scenarios): 实施二级强化学习阶段,旨在提高模型的帮助性和无害性,同时优化其推理能力。
• 知识蒸馏: 使用DeepSeek-R1精心策划的800k个样本,直接微调开源模型Qwen和Llama。
详细方法和步骤:
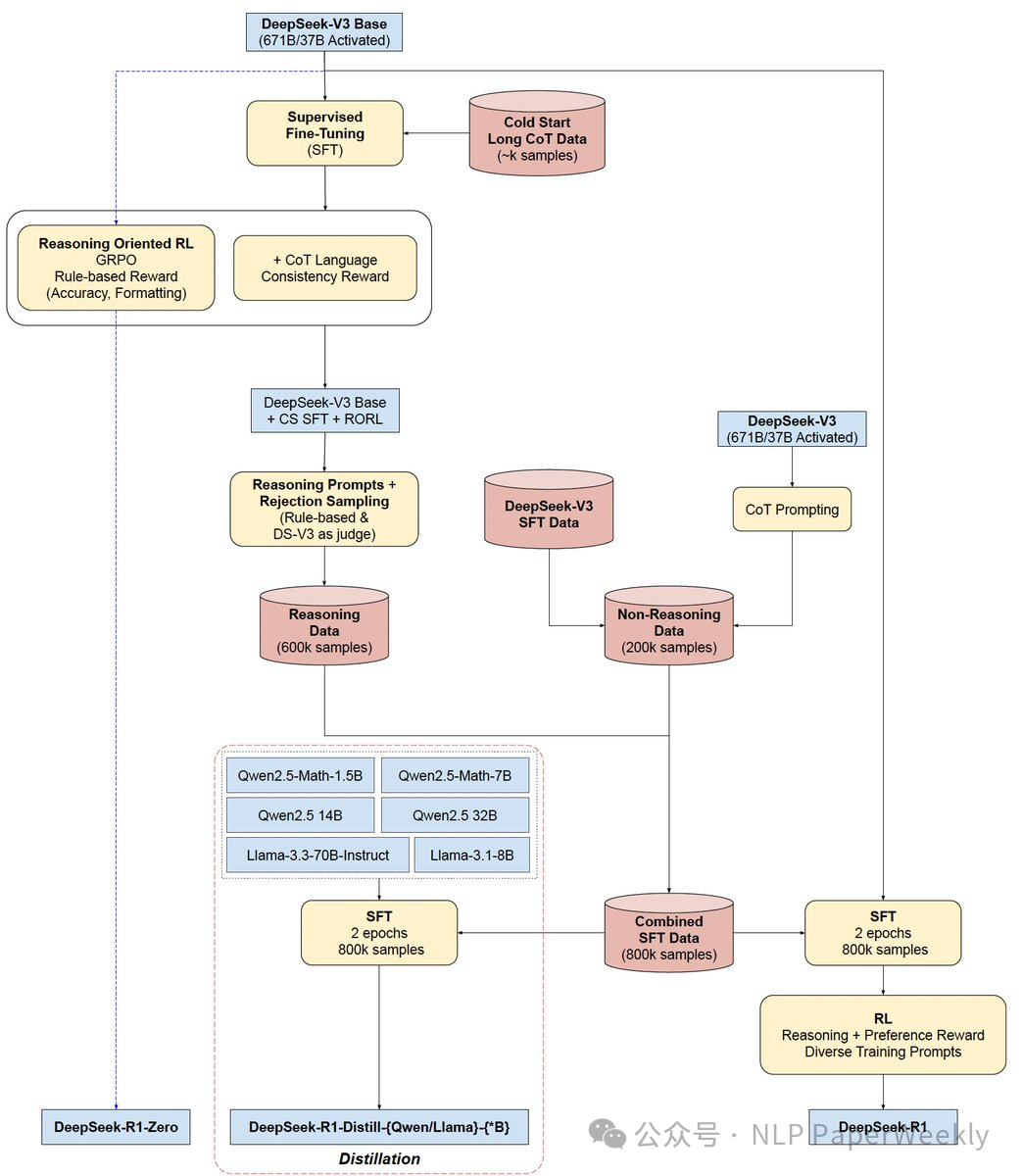
DeepSeek-R1-Zero:基础模型的强化学习
• 强化学习算法: 采用 Group Relative Policy Optimization (GRPO) 算法,该算法无需 critic 模型,通过组内分数估计基线,降低了训练成本。
• Reward奖励建模: 使用基于规则的奖励系统,包括:

• 准确性奖励: 评估答案是否正确,例如数学题答案最终结果的正确性,代码题编译器的反馈。
• 格式奖励: 鼓励模型将思考过程置于
<think>和</think>标签之间。
• 训练模板: 设计了包含
<think>和</think>标签的模板,引导模型先输出思考过程,再输出最终答案。

• 自进化过程: DeepSeek-R1-Zero 在训练过程中展现出自进化特性,能够自主学习更复杂的推理策略,例如反思和探索多种问题解决路径。
DeepSeek-R1:结合冷启动的强化学习
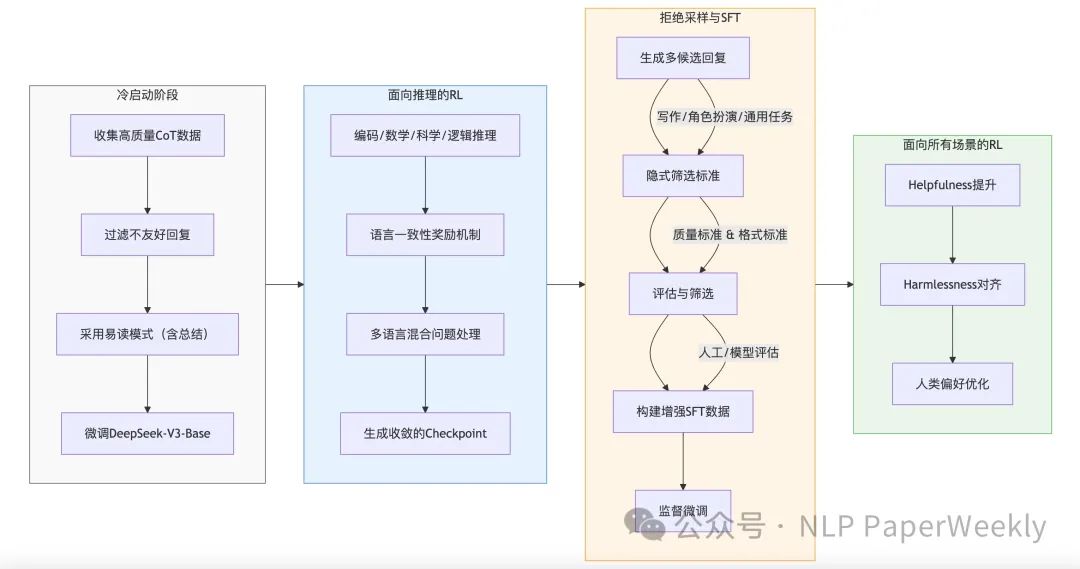
• 冷启动 (Cold Start): 为了解决 DeepSeek-R1-Zero 的可读性问题,DeepSeek-R1 首先收集少量高质量的 CoT 数据,对 DeepSeek-V3-Base 模型进行微调,作为强化学习的初始 actor。冷启动数据采用包含总结标记,并过滤掉不友好的回复。
• 方法:1) 挑选高质量Long COT数据。2) 添加 和标记。
• 优点:1) 优化可读性(解决R1-Zero的多语言问题或者markdown格式问题)。2) 精心挑选的符合人类偏好的数据可以在R1-zero上继续提升performance。
• 问题:为啥要解决可读性问题?不解决是不是可能会更好(例如降低输出长度,更高效的推理)。
• 面向推理的强化学习 (Reasoning-oriented RL): 在冷启动模型的基础上,应用与 DeepSeek-R1-Zero 类似的强化学习过程,侧重于提升模型在编码、数学、科学和逻辑推理等任务上的能力。为了解决多语言混合(多语言推理)问题,引入了语言一致性奖励。
• 问题:科学和逻辑推理任务以及数据集是怎么训练的?
• 拒绝采样和监督微调 (Rejection Sampling and SFT): 当推理导向的强化学习收敛后,利用得到的 checkpoint 进行拒绝采样,生成新的 SFT 数据,并结合 DeepSeek-V3 的数据,增强模型在写作、角色扮演和通用任务上的能力。
• 目的:
• 此阶段在面向推理的强化学习(RL)过程收敛后启动。
• 主要目的是收集监督微调(SFT)数据,用于后续的训练轮次。
• 与最初的冷启动数据仅关注推理不同,此阶段旨在扩展模型的能力,使其涵盖写作、角色扮演和其他通用任务,而不仅仅是推理。
• 数据收集 - 推理数据:
• 方法: 使用从推理导向的 RL 阶段获得的检查点,通过拒绝采样生成推理轨迹。
• 数据集扩展: 不同于前面 RL 阶段仅仅使用的基于规则的奖励数据。这里引入了非ru le-based reward的数据,在某些情况下使用**生成式奖励模型(DeepSeek-V3)**来判断响应。
• 数据过滤: 为了确保质量和可读性,输出结果会经过过滤,以移除:
• 包含混合语言的思维链
• 过长的段落
• 代码块
• 采样与选择: 对于每个提示,会生成多个响应。仅保留“正确”的响应用于数据集。
• 数据集大小: 以这种方式收集了大约 60 万个与推理相关的训练样本。
• 数据收集 - 非推理数据:
• 涵盖范围:写作、事实性问答(QA)、自我认知和翻译等领域。
• 论文中提到采用 DeepSeek-V3 的流程并重用 DeepSeek-V3 SFT 数据集的部分内容 来处理这些非推理任务。大约收集了 20 万个与推理无关的样本。 (注意:非推理数据的收集细节在 2.3.4 节中进一步阐述)
• 收集数据的使用:
• 收集到的推理和非推理数据(总计约 80 万个样本 - 60 万个推理样本 + 20 万个非推理样本)随后用于对 DeepSeek-V3-Base 模型进行两个 epoch 的微调。然后,这个微调后的模型进入 2.3.4 节描述的最终 RL 阶段。
• **总结:**该步骤利用通过 RL 学习到的推理能力来生成多样化和高质量的 SFT 数据集。这个数据集加强了推理能力,还扩展了模型的通用能力,用于最终的对齐和改进阶段的训练。
• 面向所有场景的强化学习 (Reinforcement Learning for all Scenarios): 为了进一步对齐人类偏好,实施了第二阶段强化学习,旨在提高模型的helpfulness和harmlessness。
• 推理数据:例如数学、代码、逻辑推理还是用rule base方法监督。
• 一般数据:还是用reward模型来提供复杂和微妙场景的偏好信息。估计还是采用pairwise的数据训练的模型。
• 有用性:只关注最终summary的结果,减少对推理过程的干扰。
• 无害性:对整个response进行监督,降低任何存在的风险。
模型蒸馏 (Distillation):
• 为了获得更高效的小型推理模型,论文将 DeepSeek-R1 的推理能力蒸馏到 Qwen 和 Llama 系列的开源模型中。蒸馏过程仅使用监督微调 (SFT),未使用强化学习阶段。
3 Conclusion
• DeepSeek-R1-Zero:展示了纯强化学习在激励LLM推理能力方面的潜力,无需依赖监督数据即可实现强大的性能。
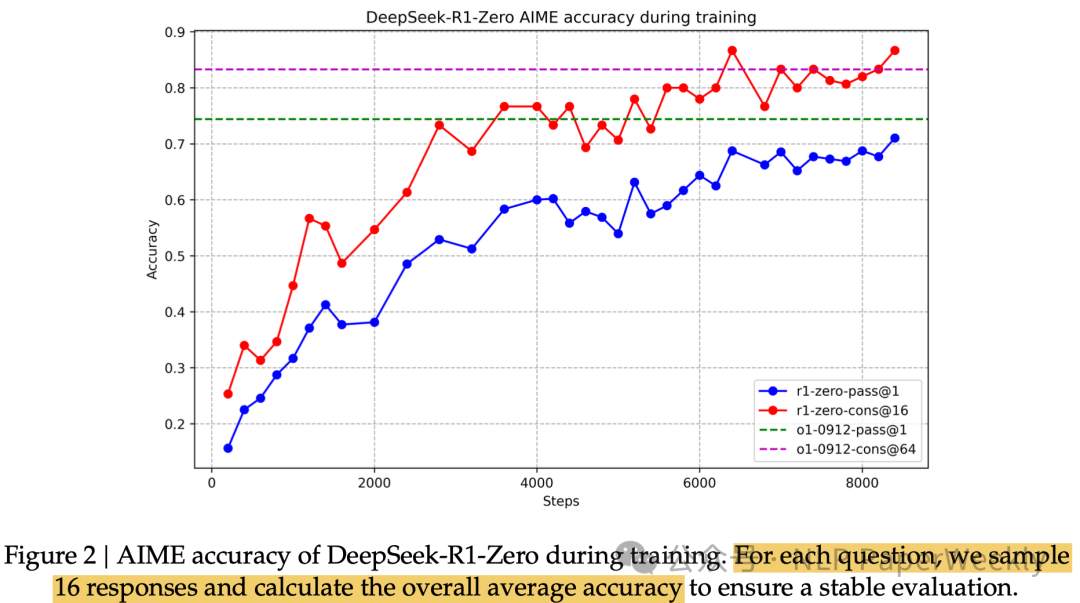

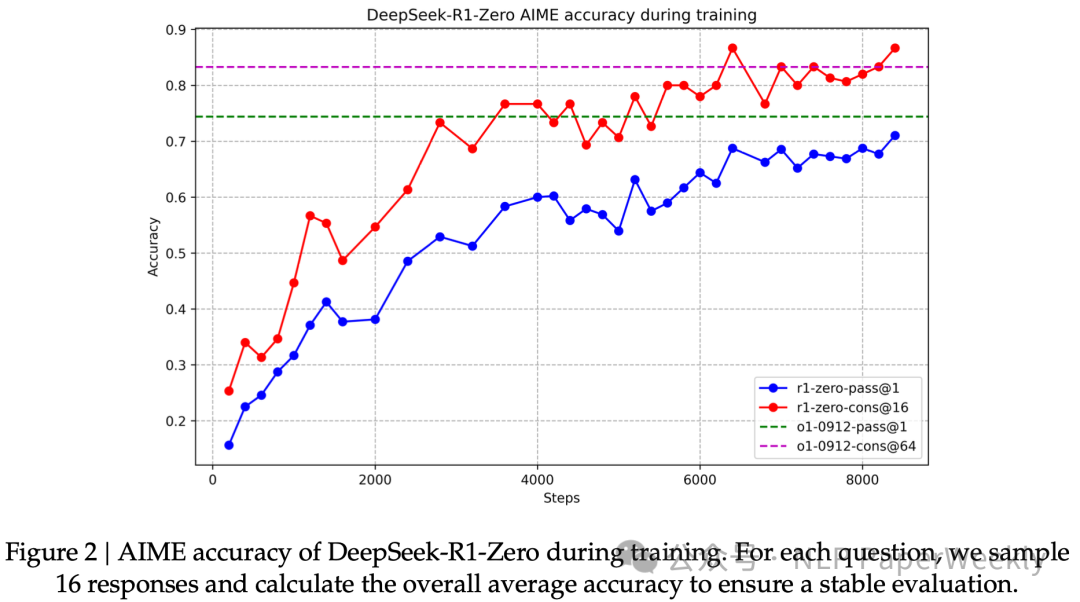
• Aha-moment: 强化学习之美(模型的顿悟时刻,通过学会重新评估初始方法来为问题分配更多的思考时间)
• 输出长度持续增加(思考时间持续增加)
• 准确率持续提升(采样16个response计算精度)

• DeepSeek-R1:通过结合冷启动数据和迭代强化学习微调,进一步提升了模型性能,实现了与OpenAI-01-1217在各种任务上相媲美的水平。
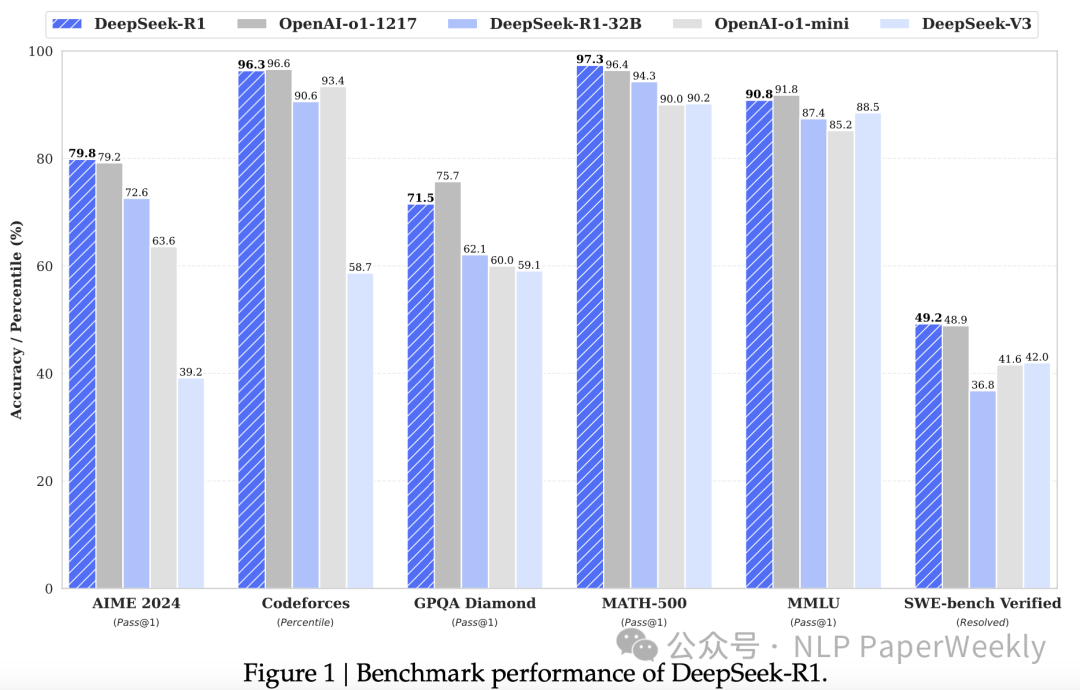
• 知识蒸馏:通过使用DeepSeek-R1作为教师模型,生成800K训练样本,并微调几个小型密集模型。结果表明,这种蒸馏方法能够显著提高小型模型的推理能力。
4 Limitation
• 局限性 1: DeepSeek-R1 的通用能力有待提升。 在函数调用、多轮对话、复杂角色扮演和 JSON 输出等任务上,DeepSeek-R1 的能力仍不及 DeepSeek-V3。
• 局限性 2: 语言混合问题。 DeepSeek-R1 在处理非中英文查询时,可能会出现语言混合问题,例如用英文进行推理和回复。
• 局限性 3: 提示敏感性。 DeepSeek-R1 对提示词比较敏感,少样本提示 (few-shot prompting) 会降低其性能。
• 局限性 4: 软件工程任务上的应用受限。 由于评估时间较长,大规模强化学习在软件工程任务上的应用尚不充分,DeepSeek-R1 在软件工程基准测试上相比 DeepSeek-V3 提升有限。
二、详细内容
1 Why DeepSeek Zero Work?
1. 基于deepseek v3,其具备强大的基座能力。
2. 基于GRPO,对长文本(long cot),GRPO的loss函数训练更稳定,容易激发出长推理能力,并且同样对于长文本,可能PPO的Critical Model更不准,反而不利于监督。
3. 为什么模型能自主出现自进化现象和“aha moment”?
• 可能答案1: 模型真的从0到1学会了深度推理,出现了顿悟。
• 感觉难度系数太高,rule-base方式监督信号比较稀疏,只能说base-model足够强,才有一定概率能激发。
• 可能答案2: 基座模型其实见过非常多的深度推理的数据,包括数学,代码,科学等,我们只需要适当的监督(Rule-base RL),激活这些能力即可。
• 如工作[1]中提到:整个 RL 过程是将原本肤浅的自我反思转变为有效的自我反思,以最大化预期奖励,从而提高推理能力。
• 可能答案3:数据污染,可能预训练已经见过非常多的这种深度推理的数据了。
• 感觉也有可能,[1]中提到llama3不太行,qwen2.5,deepseek这类模型反而效果不错。
4. 为什么rule-base的监督信号能work?
• 任务可能其实比较简单,例如[1]提到epoch=0就有这种反思,但是可能不太对,适当监督下就OK了?
5. 为什么不用prm监督?
• 数据集构建成本高,这里可能openai走了不少弯路,标注了非常多的数据,所以特宝贝他们的cot过程。
• prm可能效果不一定好?可能并不太能准确判断中间过程的好坏。例如开始想错了,不代表我后面不能做对
• 容易被reward hacking?这个不确定,但是感觉限制了llm的发挥,其实任何任务的推理过程都可以有很多种。或许这是缩短推理路径可以尝试的一些方法。
6. 自主挖掘推理过程可能比模仿人类推理更简单!!!
• 原因假设:模型通过实践和试错来发现解决问题的最佳方法。
• 如[2]提出:人类标注者在创建训练数据时,很难知道哪种解决方案最适合模型。人类标注者可能会注入模型不理解的知识,或者忽略模型已有的知识,导致模型难以理解。而强化学习让模型通过试错来自主发现适合自己的解决方案。
2 Why DeepSeek R1 Work?
1. 数据,数据还是数据!
1. 高质量的Long Cot Reasoning数据600k:基于Zero超低低成本 收集了600k高质量的Long COT Reasoning的数据。这里主要数学,编程,科学等领域的数据,也包括经过推理强化后的Zero模型生成的通用场景的推理数据。
2. 通用推理能力:非推理数据,通用场景高质量数据收集;prompt deepseek v3生成高质量的通用数据集。
2. Q:为啥感觉DeepSeek-R1能力主要来自于蒸馏DeepSeek-Zero的能力?
1. 能力来源于DeepSeek-Zero蒸馏(600k高质量的数据):前面高质量的冷启动数据提升了Zero推理结果的可读性,可能还有通用能力,同时这些Long COT数据模型学起来可能非常快,因为就是同一个base模型调教出来的。同时还能拓展到其他非数学推理等场景。
2. 但也不只是蒸馏: 最后阶段10k step的全场景RL训练也能继续提升performance,但是论文没放出具体指标收益,不确定各部分的收益,猜测可能第一步有比较多的简单易学的Long COT数据来学习了,收益可能还比较大,后面RL能继续提升能力?
3. Q:为什么冷启动阶段还采用高质量的数据SFT的老路子?
1. 提升DeepSeek-Zero模型生成的Long COT数据的可读性,可能是为了方便后续基于Zero生成和筛选高质量的生成数据?
2. 使Zero模型生成结果更符合人类偏好。
4. Q:如何提高Zero模型生成的数据集质量?
1. 利用基于人类偏好优化数据集SFT以及RL微调后的Zero模型(增强版Zero模型)生成。其优点是可读性好,同时推理能力强,并且还能泛化到了其他领域。同时可能模型还更容易学习。
2. Rule base方法筛选。
3. deepseek v3模型筛选。
4. 可能人工筛洗?
5. 背景:其实可能反而LLM自己生成的推理路径更容易学[2]!!!
5. Q:如何对齐人类偏好?
1. 推理数据:例如数学、代码、逻辑推理还是用rule base方法监督。
2. 一般数据:还是用reward模型来提供复杂和微妙场景的偏好信息。估计还是采用pairwise的数据训练的模型。
3. 有用性:只关注最终summary的结果,减少对推理过程的干扰。
4. 无害性:对整个response进行监督,降低任何存在的风险。
三、总结
结论1: 纯强化学习 (DeepSeek-R1-Zero) 可以在不依赖监督数据的情况下,有效激励LLMs的推理能力。 本文成功探索了使用纯强化学习激励LLMs推理能力的方法 (DeepSeek-R1-Zero),验证了 RL 在提升模型推理能力方面的有效性,无需依赖大量的监督数据。 这一发现为未来研究纯 RL 方法在 LLMs 推理能力提升方面的应用奠定了基础。
结论2: 提出的 DeepSeek-R1 训练流程,通过结合冷启动、多阶段 RL 和蒸馏等技术,有效提升了模型的推理能力、用户友好性和效率。 DeepSeek-R1 在多个推理基准测试中取得了优异的成绩,并开源了模型和蒸馏版本,为研究社区提供了宝贵的资源。
结论3: 论文深入分析了模型训练过程中的自进化现象和“aha moment”,揭示了强化学习在驱动模型自主学习复杂推理策略方面的潜力。 这些发现有助于研究者更深入地理解 RL 的工作机制,并为未来开发更智能、更自主的模型提供启示。
结论4: DeepSeek-R1 模型也存在一些局限性,例如通用能力不足、语言混合问题和提示敏感性等,并提出了未来的改进方向,包括提升通用能力、解决语言混合问题、优化提示工程和探索在软件工程任务上的应用等。 这些分析为未来的研究工作提供了明确的方向。
四、参考
[1] https://oatllm.notion.site/oat-zero
[2]https://mp.weixin.qq.com/s/lBc0-8ByRxJ3JBJpMcfzkQ
也欢迎找我交流:个人介绍
👇关注公众号NLP PaperWeekly,对话框输入“DeepSeekR1”,即可领取上述论文👇
进技术交流请添加我微信(FlyShines)请备注昵称+公司/学校+研究方向,否则不予通过

















 6337
6337

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









