




👋hi,我不是一名外包公司的员工,也不会偷吃茶水间的零食,我的梦想是能写高端CRUD
🔥 2025本人正在沉淀中… 博客更新速度++
👍 欢迎点赞、收藏、关注,跟上我的更新节奏
📚欢迎订阅专栏,专栏别名《在2B工作中寻求并发是否搞错了什么》
前言
在上一篇中,【Java并发】【volatile】适合初学者体质的volatile
我们知道了volatile的特性,而这一篇,我们将更进一步,我们这次要明白这些特性是怎么实现的
👆点上关注不迷路,让我们速速开始,探索这volatile的原理吧!
JMM
首先是要从JMM来说起。
Java 内存模型(Java Memory Model, JMM) 是 Java 并发编程的核心规范,它定义了 多线程环境下共享变量的访问规则,确保程序在不同硬件和操作系统上的行为一致且可预测。
😄简答的可以理解为
● JMM 是交通规则:规定红灯停、绿灯行。
● JVM 是司机和车辆:不同司机(x86/ARM)用不同方式遵守规则,但结果一致。
● 硬件是道路:平坦高速(x86)或崎岖山路(ARM),影响实现效率,但规则不变。
为什么需要 JMM?
- 硬件差异的抽象
不同 CPU 架构(如 x86、ARM)的内存一致性模型不同(如缓存一致性协议、指令重排序规则),JMM 通过统一规范屏蔽底层差异,使 Java 程序能跨平台运行。 - 解决多线程的核心问题
- 可见性:一个线程修改了共享变量,其他线程能否立即看到?
- 有序性:代码的执行顺序是否会被编译器或 CPU 重排序?
- 原子性:多线程操作共享变量时,是否能保证操作的完整性?
JMM 定义内容 & JVM 实现
因为我们这篇说的是volatile关键字,尽量说和volatile不相关的定义内容。
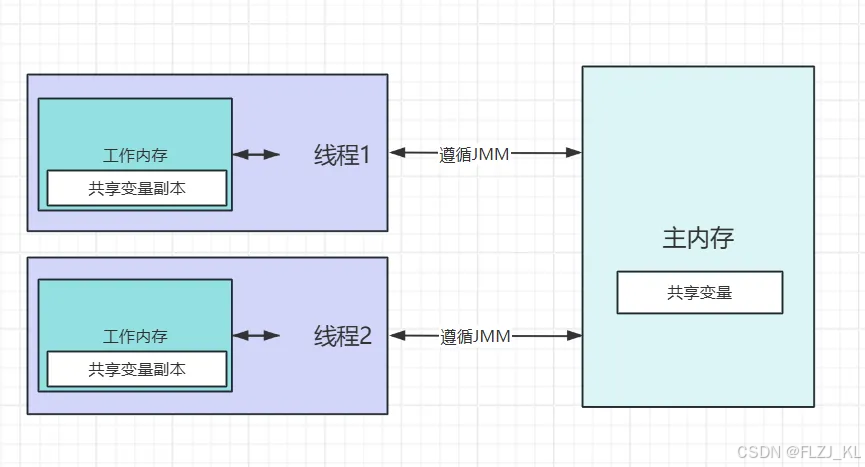
1. 主内存与工作内存
在 Java 内存模型(JMM)中,主内存 和 工作内存 是两个核心概念,用于描述多线程环境下共享变量的存储和访问规则。
- 主内存(Main Memory):所有线程共享的内存区域,存储共享变量的实际值。
- 工作内存(Working Memory):每个线程私有的内存区域,存储线程操作共享变量时的副本。线程对共享变量的操作必须先在工作内存中进行,再同步到主内存。
2.happens-before 原则
happens-before 是 Java 内存模型(JMM)中定义的一种 偏序关系,用于描述多线程操作之间的 可见性 和 顺序性。
它的核心思想是:如果一个操作 A happens-before 操作 B,那么 A 的结果对 B 可见,且 A 的执行顺序在 B 之前。
public class HappensBeforeExample {
private int x = 0;
private volatile boolean flag = false;
public void writer() {
x = 42; // 操作 A
flag = true; // 操作 B(volatile 写)
}
public void reader() {
if (flag) { // 操作 C(volatile 读)
System.out.println(x); // 操作 D
}
}
}
- happens-before 关系:
- 操作 A happens-before 操作 B(程序顺序规则)。
- 操作 B happens-before 操作 C(volatile 变量规则)。
- 操作 C happens-before 操作 D(程序顺序规则)。
结果:如果线程 1 调用 writer(),线程 2 调用 reader(),那么线程 2 一定能看到 x=42。
JVM实现
- 编译器约束:在编译阶段禁止违反
happens-before的代码重排序 - 内存屏障插入:在字节码或机器码层面插入屏障指令,强制内存操作顺序
- 锁机制同步:通过
monitorenter/monitorexit(synchronized 底层)建立临界区顺序
3.禁止指令重排序(Reordering Constraints)
规则:编译器和处理器不能对 volatile 变量的读写操作与其他内存操作进行重排序
为什么会有指令重排序的说法呢?这就说说我们的as-if-serial了
as-if-serial 语义:编译器和处理器 在单线程程序中遵循的一种优化规则。
优化规则:通过重排序指令,充分利用 CPU 流水线和缓存,提高程序执行效率。
核心思想:无论指令如何重排序,单线程程序的执行结果必须与代码顺序执行的结果一致。
指令重排序可能发生在 :Java 编译器、JVM(JIT 编译器) 和 CPU
那如何避免重排序的机制呢?通过插入 内存屏障(Memory Barrier) 实现:
- 写操作前:插入
StoreStore屏障(保证该屏障前的所有写操作完成) - 写操作后:插入
StoreLoad屏障(保证该写操作对其他处理器可见) - 读操作前:插入
LoadLoad + LoadStore屏障(保证先完成读操作,再执行后续操作)
| 屏障类型 | 作用描述 | 对应场景 |
|---|---|---|
| LoadLoad | 禁止下方普通读与上方读重排序 | volatile读之后 |
| StoreStore | 禁止上方普通写与下方写重排序 | volatile写之前 |
| LoadStore | 禁止下方普通写与上方读重排序 | volatile读之后 |
| StoreLoad | 禁止上方写与下方读/写重排序(全能屏障) | volatile写之后(开销最大) |
4.内存可见性(Memory Visibility)
规则:对 volatile 变量的读写直接作用于主内存(跳过工作内存副本)
具体表现:
- 写操作:立即将新值刷新到主内存(相当于自动执行 store + write 原子操作)
- 读操作:直接从主内存读取最新值(相当于自动执行 read + load 原子操作)
实现机制:通过缓存一致性协议和内存屏障来实现的。
下面是因为指令重排,导致可能看到旧值的情况:
// 线程A
sharedVar = 42; // 普通变量写入
flag = true; // volatile变量写入
// 线程B
while (!flag); // volatile读取
System.out.println(sharedVar); // 期望看到42,但可能看到旧值
编译器重排序:编译器可能将 sharedVar = 42 和 flag = true 重排序(若无 volatile)。
CPU 写缓冲区延迟:即使 MESI 生效,sharedVar 的写入可能仍在写缓冲区未提交到缓存。
volatile 的补救措施:插入内存屏障:禁止编译器重排序,并强制刷新写缓冲区。
缓存一致性
你是否会惊讶?这是啥?给我干哪来了?缓存一致性协议,是硬件的协议,这要干嘛?这里为什么要说缓存一致性?它是JMM保证内存可见性的硬件基础。上面说到了一堆,工作内存的副本要立即将新值刷新到主内存,这就需要缓存一致性的支持。
缓存一致性是计算机系统中用于解决多核 CPU 缓存数据不一致问题的机制。在多核系统中,每个 CPU 核心都有自己的缓存(如 L1、L2、L3 缓存),这些缓存可能存储同一主内存地址的副本。缓存一致性协议确保所有核心看到的共享数据是一致的。

MESI协议
现代 CPU 通过 缓存一致性协议 自动维护一致性,以 MESI 协议 为例:
MESI 协议
- M(Modified):缓存行已被修改(与主存不一致),需写回内存。
- E(Exclusive):缓存行是独占的(其他核心无副本),可安全修改。
- S(Shared):缓存行与其他核心共享(只读)。
- I(Invalid):缓存行无效(需重新加载)。
MESI 的工作原理
- 读操作:
当一个核心读取缓存行时,如果状态为I,则从主内存或其他核心的缓存中加载数据,并将状态设置为S或E。 - 写操作:
当一个核心修改缓存行时,如果状态为S或E,则将其状态改为M,并通知其他核心将其缓存行状态改为I(失效)。 - 写回操作:
当一个核心需要替换M状态的缓存行时,必须将其写回主内存。
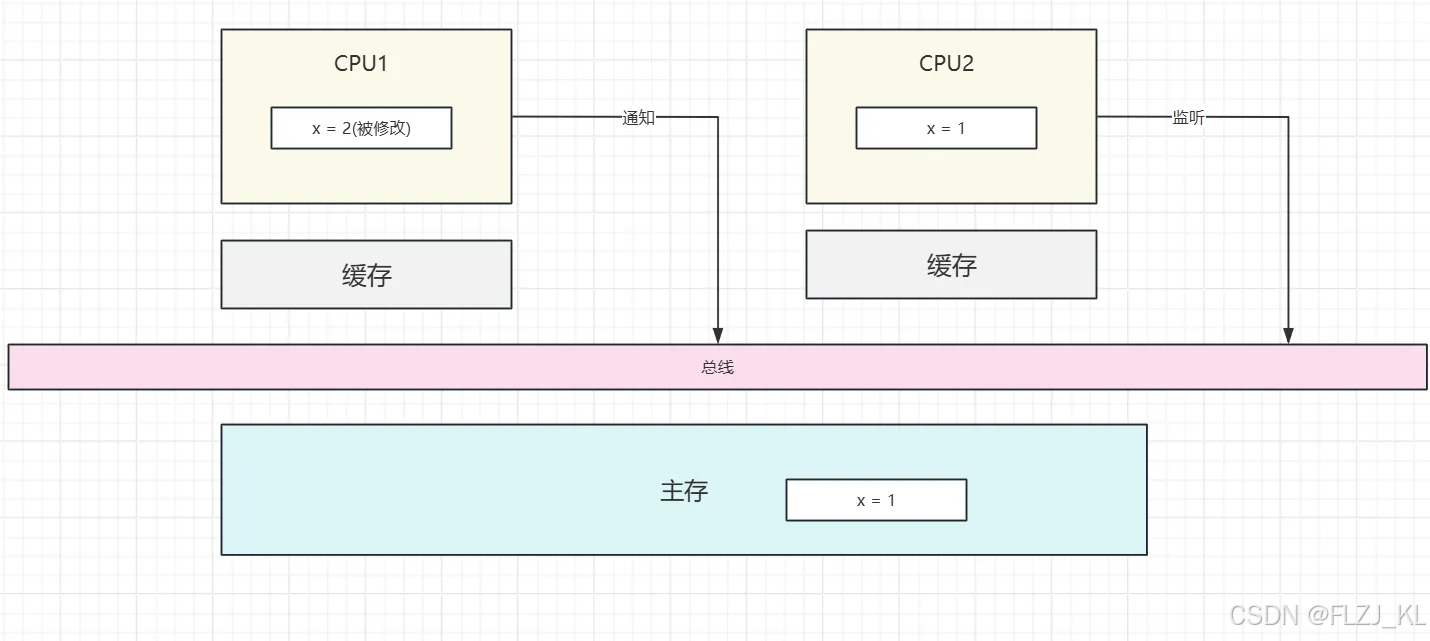
总线嗅探
当有一个核CPU的变量被修改的时候,其他CPU是怎么知道自己要不更新的呢?这就引出了这个总线嗅探。
总线嗅探是多核处理器中维护缓存一致性(Cache Coherence)的核心机制。其核心思想是:当某个CPU核心修改了缓存中的数据时,会通过总线(Bus)广播这一事件,其他核心监听到广播后,会同步更新自己的缓存,确保所有核心看到的数据一致。
总线风暴
由于MESI缓存一致性协议,需要不断对主线进行内存嗅探,大量的交互会导致总线带宽达到峰值。因此不要滥用volatile。
这时候,比较活跃的同学就会想说,我就是想多用怎么办?有没有什么优化方案?有的,兄弟,有的。
避免伪共享
缓存行填充(Padding):
通过填充变量,确保每个变量独占一个缓存行,避免多个变量共享同一缓存行。
class PaddedAtomicLong {
private volatile long value;
private long p1, p2, p3, p4, p5, p6, p7; // 填充
}
使用 @Contended 注解:
在 Java 中,可以使用 @Contended 注解自动填充变量,避免伪共享。
@Contended
class ContendedAtomicLong {
private volatile long value;
volatile特性原理
😎前面铺垫了这么久,现在终于可以到原理了。
可见性原理
volatile 关键字在 Java 中通过 强制内存可见性 和 即时刷新内存 的机制来保证变量的可见性。其底层原理与 Java 内存模型(JMM)、CPU 缓存一致性协议(如 MESI) 和 内存屏障(Memory Barrier) 密切相关。
可见性问题根源:在多线程环境中,每个线程都有自己的 本地缓存(如 CPU 寄存器、L1/L2 缓存等),对变量的修改可能不会立即同步到主内存,导致其他线程无法感知到变量的最新值。例如:
// 线程A
flag = true; // 修改后未同步到主内存
// 线程B
while (!flag) { // 仍然读取本地缓存中的旧值(false)
// 死循环
}
可见性的保证
- 规范层(JMM)
- 规则:对
volatile变量的写操作必须立即对其他线程可见,读操作必须读取最新值。 - Happens-Before 规则:volatile 写操作 Happens-Before 后续的volatile 读操作。
- 规则:对
- 实现层(JVM)
- 内存屏障插入:
- 写操作后插入
StoreLoad屏障:强制将写缓冲区的数据刷新到内存,并触发缓存一致性协议。 - 读操作前插入
LoadLoad屏障:确保从主内存重新加载最新值。
- 写操作后插入
- 编译优化限制:禁止编译器将 volatile 变量的读写优化为寄存器缓存(强制每次读写内存)。
- 内存屏障插入:
- 硬件层(CPU)
- 缓存一致性协议(如 MESI):
- 当 CPU 修改 volatile 变量时,其他 CPU 的对应缓存行会被标记为 Invalid(失效)。
- 其他 CPU 读取失效的缓存行时,必须从主内存或其他 CPU 缓存中重新加载最新值。
- 内存屏障指令:例如 x86 的 mfence 指令会强制刷新写缓冲区,确保数据对其他 CPU 可见。
- 缓存一致性协议(如 MESI):
有序性原理
volatile 关键字在 Java 中通过 内存屏障(Memory Barrier) 和 禁止指令重排序 来保证有序性。它的底层实现与 Java 内存模型(JMM)和硬件层面的 CPU 指令密切相关。
在程序执行时,为了提高性能,编译器、JIT 编译器和 CPU 可能会对指令进行重排序。例如:
int a = 1; // 普通写
volatile int b = 2; // volatile 写
int c = 3; // 普通写
如果没有 volatile,编译器或 CPU 可能会将 c = 3 重排序到 b = 2 之前执行。但在多线程环境下,这种重排序可能导致其他线程观察到不一致的状态。
有序性保证
- 规范层(JMM)
- 规则:
- volatile 写操作前的所有普通读写操作不能重排序到写之后。
- volatile 读操作后的所有普通读写操作不能重排序到读之前。
- 禁止重排序类型:
- 规则:
| 操作类型 | 是否允许重排序 |
|---|---|
| 普通写 → volatile 写 | ❌ 禁止 |
| volatile 读 → 普通读/写 | ❌ 禁止 |
- 实现层(JVM)
- 内存屏障插入:
- 写操作后插入
StoreStore+StoreLoad屏障:- StoreStore:禁止普通写重排序到 volatile 写之后。
- StoreLoad:禁止 volatile 写后的读操作重排序到写之前。
- 写操作后插入
- 读操作前插入
LoadLoad+LoadStore屏障:- LoadLoad:禁止普通读重排序到 volatile 读之前。
- LoadStore:禁止普通写重排序到 volatile 读之前。
- 内存屏障插入:
- 编译优化限制:禁止编译器对
volatile变量附近的指令进行重排序。
- 硬件层(CPU)
- 内存屏障指令:
- x86 的
mfence指令会限制指令重排序。 - ARM 的
dmb指令会限制内存访问顺序。
- CPU 重排序限制:内存屏障指令会告诉 CPU:“屏障前的操作必须在屏障前完成,屏障后的操作必须在屏障后开始”。
不保证原子性-volatile的局限性
volatile int count = 0;
// 线程A
count++; // 实际是 read → modify → write 三步操作,可能被其他线程打断
// 线程B
count++; // 最终结果可能小于预期
解决方案:使用 AtomicInteger 或 synchronized
参考
反制面试官 | 14张原理图 | 再也不怕被问 volatile!
面霸的自我修养:volatile专题
面试官没想到一个Volatile,我都能跟他扯半小时
(一)玩命死磕Java内存模型(JMM)与Volatile关键字底层原理
面试官问我什么是JMM

















 528
528

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









