










程序是由多条指令构成的,程序的运行便是cpu一条一条执行程序指令的过程。一条指令的执行过程大致可以分为加载指令,翻译指令,加载数据,执行运算,更新数据几个阶段,每个阶段都由单独的运算单元去执行。为了提高性能,各阶段是并行执行的,即当前指令的流程到了执行运算阶段,下一条指令的流程有可能已经到了加载数据阶段。这样做至少有两个优点:单元复用和并行执行。即使同一个阶段,多条指令流程也是可以并行执行的,如执行运算阶段,加法运算和乘法运算时可以同时执行的。下图是一张现代cpu运算单元的简单模型(摘自《深入理解计算机系统》):
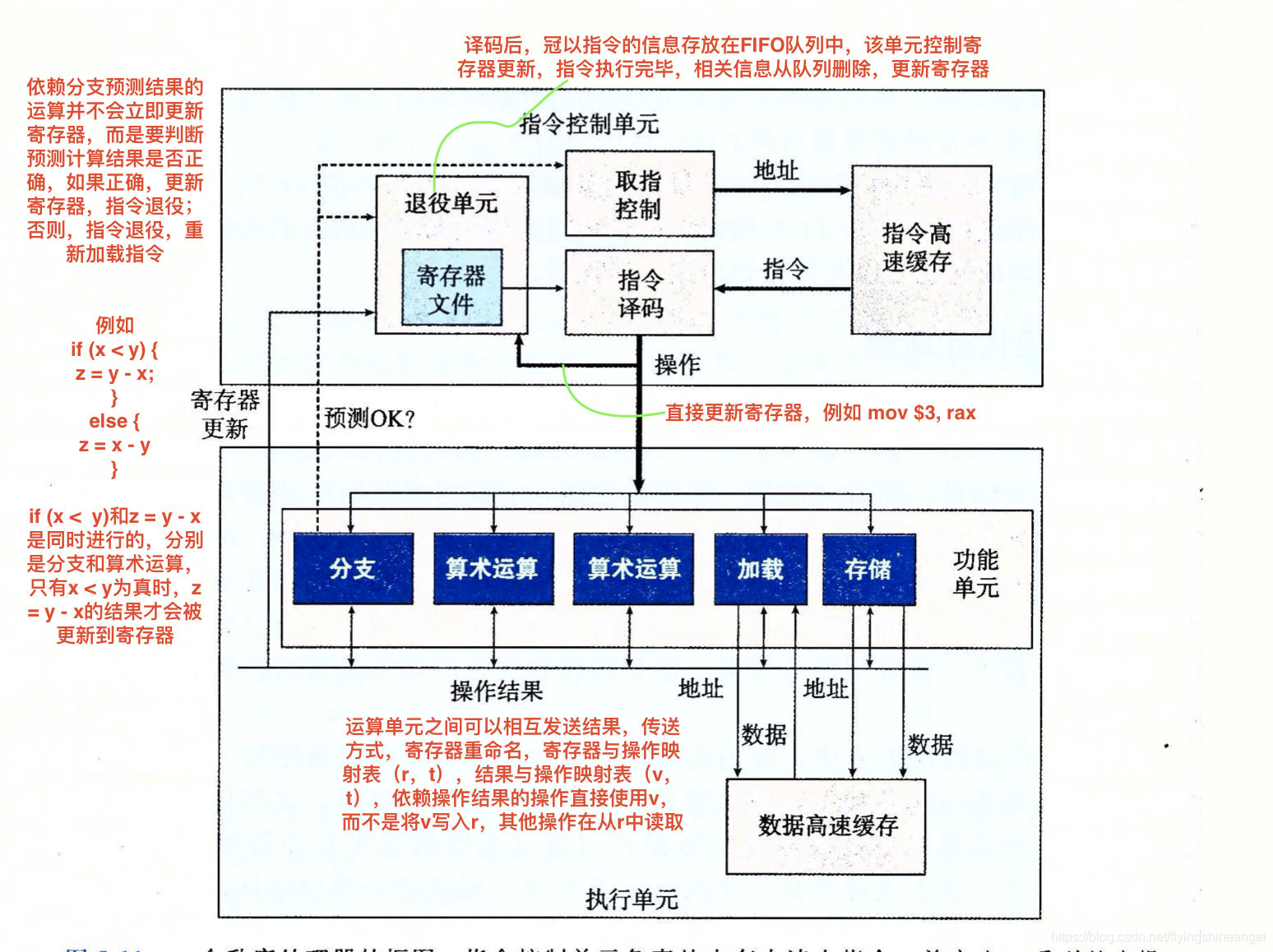
只有到了执行运算阶段,cpu才知道具体的指令是什么。对于分支结构程序的处理,cpu采取了非常精密的分支预测逻辑。即遇到分支运算时,cpu根据自己的猜测去加载分支代码。尽管现在cpu分支预测的命中率很高,但仍然有猜错的概率,出现错误,之前的所有结果将会全部被丢弃,然后流程重新开始,这便是分支预测错误的惩罚。下面将通过两段程序来说明分支预测。
环境:centos 7.2,gcc 4.8.5
程序1源码:
#include <stdio.h>
#include <math.h>
#include <stdlib.h>
//通过对一个数组中的奇数偶数做不同的处理,进行分支预测失败的惩罚
//为了能够统计时间,该值尽量大,否则所有的时间都会为0
#define ARRAY_SIZE 100000000
char buffer[1024];
//对奇数进行处理
void proc_odd(long num)
{
float ret = tanl(sinl(num));
sprintf(buffer, "%0.4f", ret);
}
long calc(long num)
{
num = num / 10 + num;
}
//对偶数进行处理
void proc_even(long num)
{
num = calc(num);
}
void iftest1(long *array)
{
for (long i = 0; i < ARRAY_SIZE; ++i) {
if (array[i] % 2 == 0)
proc_even(array[i]);
else
proc_odd(array[i]);
}
}
void iftest2(long *array)
{
for (long i = 0; i < ARRAY_SIZE; ++i) {
if (array[i] % 2 == 0)
proc_even(array[i]);
else
proc_odd(array[i]);
}
}
void iftest3(long *array)
{
for (long i = 0; i < ARRAY_SIZE; ++i)
array[i] % 2 == 0 ? proc_even(array[i]) : proc_odd(array[i]);
}
void iftest4(long *array)
{
for (long i = 0; i < ARRAY_SIZE; ++i) {
if (array[i] % 2 == 0)
proc_even(array[i]);
else
proc_odd(array[i]);
}
}
int main(int argc, char **argv)
{
//按顺序准备数据,使用条件分支处理数据
long *array = new long[ARRAY_SIZE];
for (long i = 0; i < ARRAY_SIZE; ++i)
array[i] = i;
iftest1(array);
//准备数据时,前半部分为偶数,后半部分为奇数,使用条件分支处理数据
long half = ARRAY_SIZE / 2;
for (long i = 0; i < ARRAY_SIZE; ++i)
array[i] = i < half ? i * 2 : (i - half) * 2 + 1;
iftest2(array);
//正常准备数据,使用条件传送处理数据
for (long i = 0; i < ARRAY_SIZE; ++i)
array[i] = i;
iftest3(array);
//乱序处理
for (long i = 0; i < ARRAY_SIZE; ++i) {
srand(i);
long j = rand() % ARRAY_SIZE;
long tmp = array[i];
array[i] = array[j];
array[j] = tmp;
}
//for (long i = 0; i < ARRAY_SIZE; ++i) {
// printf("%lld\n", array[i]);
//}
iftest4(array);
delete[] array;
return 0;
}
该程序对一个整型数组中的奇数,偶数分别做不同的运算。为了方便使用分析工具,通过函数名对不同的处理方式进行区分。iftest1使用顺序数组;iftest2使用前半部分为偶数,后半部分为奇数的数组;iftest3使用顺序数组,但处理使用条件传输语句;iftest4对数据组做了乱序处理。实验结果如下:
第一次运行结果:

第二次运行结果:

第三次运行结果:

实验证明:
1.分支预测失败错误惩罚确实存在,乱序时体现的更明显;
2.理论上iftest2要比iftest1快很多(iftest1相邻的元素总是执行不同的分支),但事实并非如此,说明cpu的分支预测逻辑要比想象中“聪明”;
3.分支预测错误惩罚要在元素数量达到某一量级时才会体现出来;


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









