




在3.3.3节,我们看到,对于新的输⼊xxx,线性回归模型的预测的形式为训练数据集的⽬标值的线性组合,组合系数由“等价核”(3.62)给出,其中等价核满⾜加和限制(3.64)。
我们可以从核密度估计开始,以⼀个不同的角度研究核回归模型(3.61)。假设我们有⼀个训练集{
xn,tn}\{\textbf{x}_n, t_n\}{
xn,tn},我们使⽤Parzen密度估计来对联合分布p(x,t)p(x,t)p(x,t)进⾏建模,即
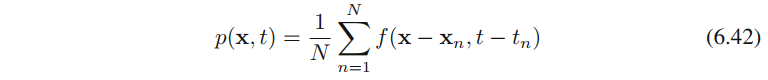
其中f(x,t)f(\textbf{x},t)f(x,t)是分量密度函数,每个数据点都有⼀个以数据点为中⼼的这种分量。我们现在要找到回归函数y(x)y(\textbf{x})y(x)的表达式
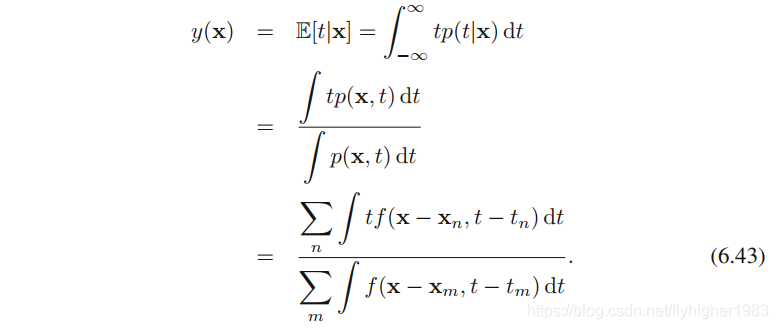
简单起见,我们现在假设分量的密度函数的均值为零(对所有x\textbf{x}x都成立),即
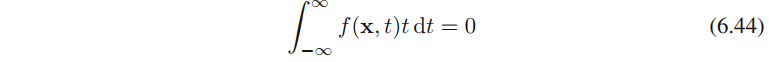
使⽤⼀个简单的变量替换,我们有(公式6.45的推导见附录“公式推导”)
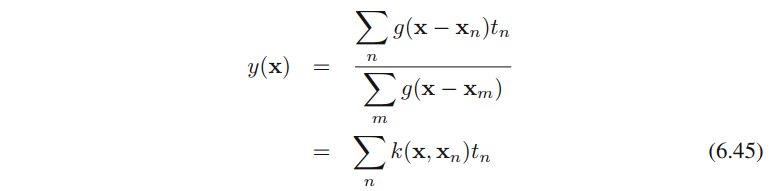
其中n,m=1,...,Nn,m = 1,...,Nn,m=1,...,N,且核函数k(x,xn)k(\textbf{x}, \textbf{x}_n)k(x,xn)为
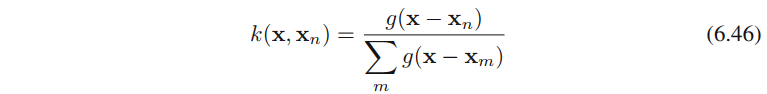
其中
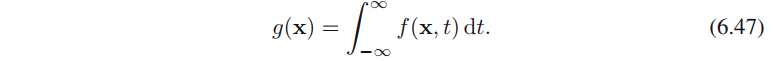
公式(6.45)给出的结果被称为Nadaraya-Watson模型,或者称为核回归。对于⼀个局部核函数,它的性质为:给距离x\textbf{x}x较近的数据点
6.3.1 Nadaraya-Watson模型(PRML读书笔记)
最新推荐文章于 2025-10-15 00:23:33 发布
 本文深入探讨了核回归模型,从核密度估计出发,详细解析了Nadaraya-Watson模型的形成过程,揭示了局部核函数如何赋予近点较高权重的机制,并讨论了核函数的加和限制条件。
本文深入探讨了核回归模型,从核密度估计出发,详细解析了Nadaraya-Watson模型的形成过程,揭示了局部核函数如何赋予近点较高权重的机制,并讨论了核函数的加和限制条件。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1758
1758



 到【灌水乐园】发言
到【灌水乐园】发言







