




 本文详细介绍Caffe实战过程,包括数据集准备、lmdb文件生成、网络结构与训练规则设定及模型训练步骤。涵盖从数据预处理到模型部署全流程。
本文详细介绍Caffe实战过程,包括数据集准备、lmdb文件生成、网络结构与训练规则设定及模型训练步骤。涵盖从数据预处理到模型部署全流程。
原文:https://blog.youkuaiyun.com/hellohaibo/article/details/77761880
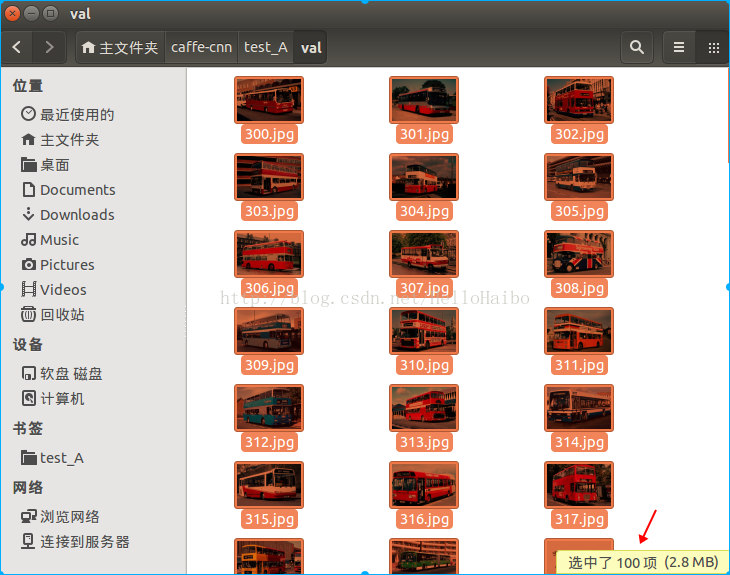
Caffe实战Day1-准备训练数据
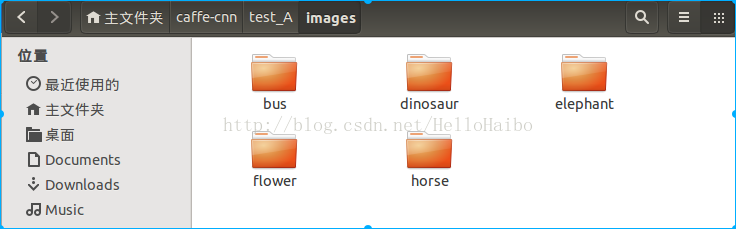
- # -*- coding: UTF-8 -*-
- # Author:dasuda
- # Date:2017.8.18
- import os
- import re
- path_train = "train文件夹路径" #建议是用绝对路径
- path_val = "val文件夹路径"
- if not os.path.exists(path_train):
- print "path_train not exist!!!"
- ox._exit()
- else:
- print "path_train exist!!!"
- if not os.path.exists(path_val):
- print "path_val not exist!!!"
- ox._exit()
- else:
- print "path_val exist!!!"
- file_train = open('train.txt的路径','wt')
- file_val = open('val.txt的路径','wt')
- file_train.truncate()
- file_val.truncate()
- pa = r".+(?=\.)"
- pattern = re.compile(pa)
- print "now,creating train.txt..."
- for filename in os.listdir(path_train):
- # print filename
- # abspath = os.path.join(path_train,filename);
- group_lable = pattern.search(filename)
- str_label = str(group_lable.group())
- if str_label[0]=='3':
- train_lable = '0'
- elif str_label[0]=='4':
- train_lable = '1'
- elif str_label[0]=='5':
- train_lable = '2'
- elif str_label[0]=='6':
- train_lable = '3'
- elif str_label[0]=='7':
- train_lable = '4'
- else:
- print "error data!!!"
- ox._exit()
- # print abspath,train_lable.group()
- file_train.write(filename+' '+train_lable+'\n')
- print "train.txt created!!!"
- print "-----------------------------------"
- print "now,creating val.txt..."
- for filename in os.listdir(path_val):
- # print filename
- # abspath = os.path.join(path_val,filename);
- group_lable = pattern.search(filename)
- str_label = str(group_lable.group())
- if str_label[0]=='3':
- val_lable = '0'
- elif str_label[0]=='4':
- val_lable = '1'
- elif str_label[0]=='5':
- val_lable = '2'
- elif str_label[0]=='6':
- val_lable = '3'
- elif str_label[0]=='7':
- val_lable = '4'
- else:
- print "error data!!!"
- ox._exit()
- # print abspath,train_lable.group()
- file_val.write(filename+' '+val_lable+'\n')
- print "val.txt created!!!"
- print "function over!!!"
# -*- coding: UTF-8 -*-
import os
import re
path_train = "/home/hp/caffe/mytest1/re/train/" #建议是用绝对路径
path_val = "/home/hp/caffe/mytest1/re/test/"
if not os.path.exists(path_train):
print "path_train not exist!!!"
ox._exit()
else:
print "path_train exist!!!"
if not os.path.exists(path_val):
print "path_val not exist!!!"
ox._exit()
else:
print "path_val exist!!!"
file_train = open('/home/hp/caffe/mytest1/zhn/train.txt','wt')
file_val = open('/home/hp/caffe/mytest1/zhn/val.txt','wt')
file_train.truncate()
file_val.truncate()
pa = r".+(?=\.)"
pattern = re.compile(pa)
print "now,creating train.txt..."
for filename in os.listdir(path_train):
# print filename
#abspath = os.path.join(path_train,filename);
group_lable = pattern.search(filename)
str_label = str(group_lable.group())
if str_label[0]=='3':
train_lable = '0'
elif str_label[0]=='4':
train_lable = '1'
elif str_label[0]=='5':
train_lable = '2'
elif str_label[0]=='6':
train_lable = '3'
elif str_label[0]=='7':
train_lable = '4'
else:
print "error data!!!"
ox._exit()
# print abspath,train_lable.group()
file_train.write(filename+' '+train_lable+'\n')
print "train.txt created!!!"
print "-----------------------------------"
print "now,creating val.txt..."
for filename in os.listdir(path_val):
# print filename
#abspath = os.path.join(path_val,filename);
group_lable = pattern.search(filename)
str_label = str(group_lable.group())
if str_label[0]=='3':
val_lable = '0'
elif str_label[0]=='4':
val_lable = '1'
elif str_label[0]=='5':
val_lable = '2'
elif str_label[0]=='6':
val_lable = '3'
elif str_label[0]=='7':
val_lable = '4'
else:
print "error data!!!"
ox._exit()
# print abspath,train_lable.group()
file_val.write(filename+' '+val_lable+'\n')
print "val.txt created!!!"
print "function over!!!" 
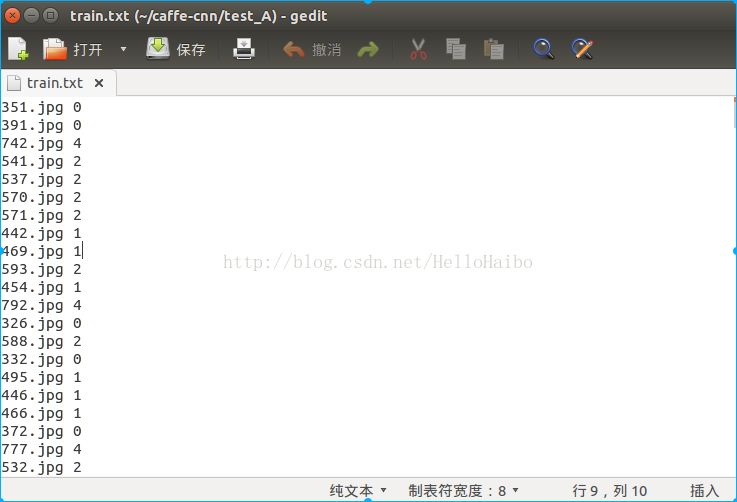
这里提一下:网上各种各样的教程txt文件格式可谓是五花八门,谁也没说清楚,为什么是这样的格式,为什么不是那样的格式,在这里澄清一下,这里的txt格式没有固定的格式,他只是生成lmdb的中间文件,他这里的格式只与生成lmdb时有关,等到下一节讲解怎样生成lmdb文件时候,你就会恍然大悟。我的建议是:txt里面命名尽可能简单,最好是像我这样,直接-文件名 标签。
Caffe实战Day2-准备lmdb文件和均值文件
- #!/usr/bin/env sh
- EXAMPLE=/home/dasuda/caffe-cnn/test_A #工程的路径
- DATA=/home/dasuda/caffe-cnn/test_A #工程的路径
- TOOLS=/home/dasuda/caffe/tools #caffe工具路径
- TRAIN_DATA_ROOT=/home/dasuda/caffe-cnn/test_A/train/ #训练集路径
- VAL_DATA_ROOT=/home/dasuda/caffe-cnn/test_A/val/ #测试集路径
- # Set RESIZE=true to resize the images to 256x256. Leave as false if images have
- # already been resized using another tool.
- RESIZE=true #这里是resize图片,我这里时开启此功能,resize成256*256
- if $RESIZE; then
- RESIZE_HEIGHT=256
- RESIZE_WIDTH=256
- else
- RESIZE_HEIGHT=0
- RESIZE_WIDTH=0
- fi
- if [ ! -d "$TRAIN_DATA_ROOT" ]; then
- echo "Error: TRAIN_DATA_ROOT is not a path to a directory: $TRAIN_DATA_ROOT"
- echo "Set the TRAIN_DATA_ROOT variable in create_imagenet.sh to the path" \
- "where the ImageNet training data is stored."
- exit 1
- fi
- if [ ! -d "$VAL_DATA_ROOT" ]; then
- echo "Error: VAL_DATA_ROOT is not a path to a directory: $VAL_DATA_ROOT"
- echo "Set the VAL_DATA_ROOT variable in create_imagenet.sh to the path" \<strong>
- </strong> "where the ImageNet validation data is stored."
- exit 1
- fi
- #训练_lmdb
- echo "Creating train lmdb..."
- #生成前需要先删除已有的文件夹 必须,不然会报错
- rm -rf $EXAMPLE/train_lmdb
- rm -rf $EXAMPLE/val_lmdb
- echo "have remove lmdb folder..."<strong>
- </strong>GLOG_logtostderr=1 $TOOLS/convert_imageset \
- --resize_height=$RESIZE_HEIGHT \
- --resize_width=$RESIZE_WIDTH \
- --shuffle \
- $TRAIN_DATA_ROOT \
- $DATA/train.txt \ #之前生成的train.txt
- $EXAMPLE/train_lmdb #生成的训练lmdb文件所在文件夹,注意train_lmdb是文件夹名称
- #测试_lmdb
- echo "Creating val lmdb..."
- GLOG_logtostderr=1 $TOOLS/convert_imageset \
- --resize_height=$RESIZE_HEIGHT \
- --resize_width=$RESIZE_WIDTH \
- --shuffle \<strong>
- </strong> $VAL_DATA_ROOT \
- $DATA/val.txt \ #之前生成的val.txt
- $EXAMPLE/val_lmdb #生成的测试lmdb文件所在文件夹,注意val_lmdb文件夹名称
- echo "Done."
MY=mytest1/zhn
echo "Create train lmdb.."
rm -rf $MY/img_train_lmdb
build/tools/convert_imageset \
--shuffle \
--resize_height=256 \
--resize_width=256 \
/home/hp/caffe/mytest1/re/train/ \
$MY/train.txt \
$MY/img_train_lmdb
echo "Create test lmdb.."
rm -rf $MY/img_test_lmdb
build/tools/convert_imageset \
--shuffle \
--resize_width=256 \
--resize_height=256 \
/home/hp/caffe/mytest1/re/val/ \
$MY/val.txt \
$MY/img_test_lmdb
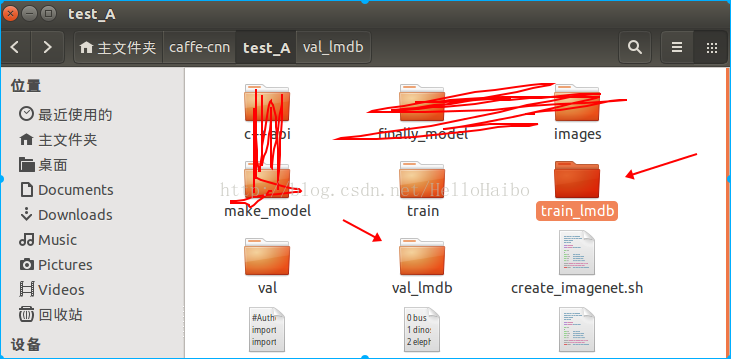
echo "All Done.."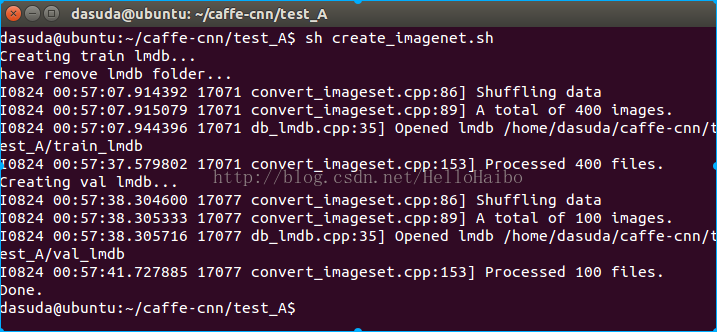
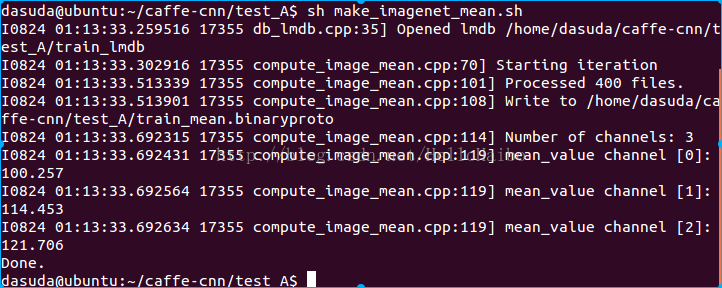
- <span style="font-size:18px;">#!/usr/bin/env sh
- #以下三个路径跟生成lmdb脚本中的一致,可以直接copy过来
- EXAMPLE=/home/dasuda/caffe-cnn/test_A
- DATA=/home/dasuda/caffe-cnn/test_A
- TOOLS=/home/dasuda/caffe/tools
- $TOOLS/compute_image_mean $EXAMPLE/train_lmdb \ #传人训练lmdb文件夹,注意这里只传入train_lmdb
- $DATA/train_mean.binaryproto ¥生成的均值文件名称,后缀为binaryproto
- echo "Done."</span>
sudo build/tools/compute_image_mean mytest1/zhn/img_train_lmdb mytest1/mean.binaryproto
Caffe实战Day3-准备网络结构文件和训练文件(重点)
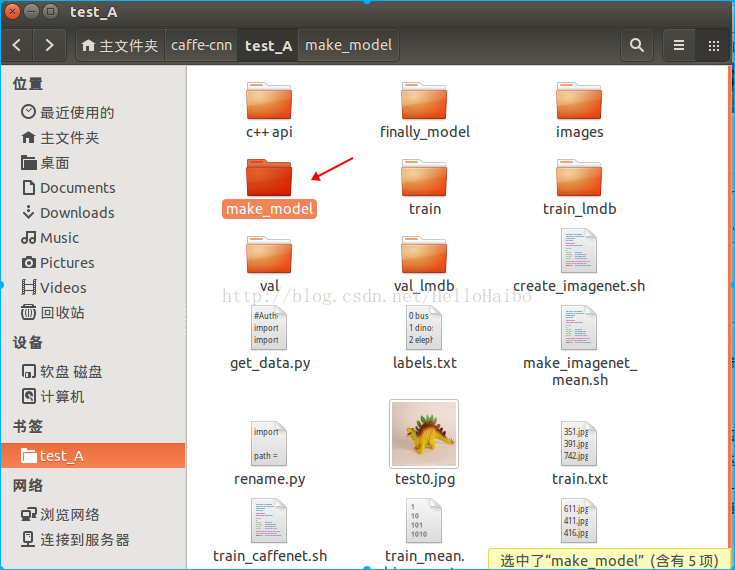
- name: "CaffeNet"
- layer {
- name: "data"
- type: "Data"
- top: "data"
- top: "label"
- include {
- phase: TRAIN
- }
- transform_param {
- mirror: true
- crop_size: 227
- mean_file: "/home/dasuda/caffe-cnn/test_A/train_mean.binaryproto" //这里是训练的均值文件
- }
- data_param {
- source: "/home/dasuda/caffe-cnn/test_A/train_lmdb" //训练的数据库文件
- batch_size: 32 #每次训练的熟练,这里说明每次训练32张图片
- backend: LMDB #传入的文件格式为lmdb
- }
- }
- layer {
- name: "data"
- type: "Data"
- top: "data"
- top: "label"
- include {
- phase: TEST
- }
- transform_param {
- mirror: false
- crop_size: 227
- mean_file: "/home/dasuda/caffe-cnn/test_A/train_mean.binaryproto" #训练的均值文件
- }
- data_param {
- source: "/home/dasuda/caffe-cnn/test_A/val_lmdb" //测试的数据库文件
- batch_size: 50 //每次测试多少张,这个与solver文件里面的参数有关
- backend: LMDB
- }
- }
- layer {
- name: "conv1"
- type: "Convolution"
- bottom: "data"
- top: "conv1"
- param {
- lr_mult: 1
- decay_mult: 1
- }
- param {
- lr_mult: 2
- decay_mult: 0
- }
- convolution_param {
- num_output: 96
- kernel_size: 11
- stride: 4
- weight_filler {
- type: "gaussian"
- std: 0.01
- }
- bias_filler {
- type: "constant"
- value: 0
- }
- }
- }
- layer {
- name: "relu1"
- type: "ReLU"
- bottom: "conv1"
- top: "conv1"
- }
- layer {
- name: "pool1"
- type: "Pooling"
- bottom: "conv1"
- top: "pool1"
- pooling_param {
- pool: MAX
- kernel_size: 3
- stride: 2
- }
- }
- layer {
- name: "norm1"
- type: "LRN"
- bottom: "pool1"
- top: "norm1"
- lrn_param {
- local_size: 5
- alpha: 0.0001
- beta: 0.75
- }
- }
- layer {
- name: "conv2"
- type: "Convolution"
- bottom: "norm1"
- top: "conv2"
- param {
- lr_mult: 1
- decay_mult: 1
- }
- param {
- lr_mult: 2
- decay_mult: 0
- }
- convolution_param {
- num_output: 256
- pad: 2
- kernel_size: 5
- group: 2
- weight_filler {
- type: "gaussian"
- std: 0.01
- }
- bias_filler {
- type: "constant"
- value: 1
- }
- }
- }
- layer {
- name: "relu2"
- type: "ReLU"
- bottom: "conv2"
- top: "conv2"
- }
- layer {
- name: "pool2"
- type: "Pooling"
- bottom: "conv2"
- top: "pool2"
- pooling_param {
- pool: MAX
- kernel_size: 3
- stride: 2
- }
- }
- layer {
- name: "norm2"
- type: "LRN"
- bottom: "pool2"
- top: "norm2"
- lrn_param {
- local_size: 5
- alpha: 0.0001
- beta: 0.75
- }
- }
- layer {
- name: "conv3"
- type: "Convolution"
- bottom: "norm2"
- top: "conv3"
- param {
- lr_mult: 1
- decay_mult: 1
- }
- param {
- lr_mult: 2
- decay_mult: 0
- }
- convolution_param {
- num_output: 384
- pad: 1
- kernel_size: 3
- weight_filler {
- type: "gaussian"
- std: 0.01
- }
- bias_filler {
- type: "constant"
- value: 0
- }
- }
- }
- layer {
- name: "relu3"
- type: "ReLU"
- bottom: "conv3"
- top: "conv3"
- }
- layer {
- name: "conv4"
- type: "Convolution"
- bottom: "conv3"
- top: "conv4"
- param {
- lr_mult: 1
- decay_mult: 1
- }
- param {
- lr_mult: 2
- decay_mult: 0
- }
- convolution_param {
- num_output: 384
- pad: 1
- kernel_size: 3
- group: 2
- weight_filler {
- type: "gaussian"
- std: 0.01
- }
- bias_filler {
- type: "constant"
- value: 1
- }
- }
- }
- layer {
- name: "relu4"
- type: "ReLU"
- bottom: "conv4"
- top: "conv4"
- }
- layer {
- name: "conv5"
- type: "Convolution"
- bottom: "conv4"
- top: "conv5"
- param {
- lr_mult: 1
- decay_mult: 1
- }
- param {
- lr_mult: 2
- decay_mult: 0
- }
- convolution_param {
- num_output: 256
- pad: 1
- kernel_size: 3
- group: 2
- weight_filler {
- type: "gaussian"
- std: 0.01
- }
- bias_filler {
- type: "constant"
- value: 1
- }
- }
- }
- layer {
- name: "relu5"
- type: "ReLU"
- bottom: "conv5"
- top: "conv5"
- }
- layer {
- name: "pool5"
- type: "Pooling"
- bottom: "conv5"
- top: "pool5"
- pooling_param {
- pool: MAX
- kernel_size: 3
- stride: 2
- }
- }
- layer {
- name: "fc6"
- type: "InnerProduct"
- bottom: "pool5"
- top: "fc6"
- param {
- lr_mult: 1
- decay_mult: 1
- }
- param {
- lr_mult: 2
- decay_mult: 0
- }
- inner_product_param {
- num_output: 4096
- weight_filler {
- type: "gaussian"
- std: 0.005
- }
- bias_filler {
- type: "constant"
- value: 1
- }
- }
- }
- layer {
- name: "relu6"
- type: "ReLU"
- bottom: "fc6"
- top: "fc6"
- }
- layer {
- name: "drop6"
- type: "Dropout"
- bottom: "fc6"
- top: "fc6"
- dropout_param {
- dropout_ratio: 0.5
- }
- }
- layer {
- name: "fc7"
- type: "InnerProduct"
- bottom: "fc6"
- top: "fc7"
- param {
- lr_mult: 1
- decay_mult: 1
- }
- param {
- lr_mult: 2
- decay_mult: 0
- }
- inner_product_param {
- num_output: 4096
- weight_filler {
- type: "gaussian"
- std: 0.005
- }
- bias_filler {
- type: "constant"
- value: 1
- }
- }
- }
- layer {
- name: "relu7"
- type: "ReLU"
- bottom: "fc7"
- top: "fc7"
- }
- layer {
- name: "drop7"
- type: "Dropout"
- bottom: "fc7"
- top: "fc7"
- dropout_param {
- dropout_ratio: 0.5
- }
- }
- layer {
- name: "fc8"
- type: "InnerProduct"
- bottom: "fc7"
- top: "fc8"
- param {
- lr_mult: 1
- decay_mult: 1
- }
- param {
- lr_mult: 2
- decay_mult: 0
- }
- inner_product_param {
- num_output: 5 #这个时最后一层全连接层,这个参数说明你要输出的类别数,我们这里有五类图片,故值为5
- weight_filler {
- type: "gaussian"
- std: 0.01
- }
- bias_filler {
- type: "constant"
- value: 0
- }
- }
- }
- layer {
- name: "accuracy"
- type: "Accuracy"
- bottom: "fc8"
- bottom: "label"
- top: "accuracy"
- include {
- phase: TEST
- }
- }
- layer {
- name: "loss"
- type: "SoftmaxWithLoss"
- bottom: "fc8"
- bottom: "label"
- top: "loss"
- }
- name: "CaffeNet"
- layer {
- name: "data"
- type: "Input"
- top: "data"
- input_param { shape: { dim: 10 dim: 3 dim: 227 dim: 227 } }
- }
- layer {
- name: "conv1"
- type: "Convolution"
- bottom: "data"
- top: "conv1"
- convolution_param {
- num_output: 96
- kernel_size: 11
- stride: 4
- }
- }
- layer {
- name: "relu1"
- type: "ReLU"
- bottom: "conv1"
- top: "conv1"
- }
- layer {
- name: "pool1"
- type: "Pooling"
- bottom: "conv1"
- top: "pool1"
- pooling_param {
- pool: MAX
- kernel_size: 3
- stride: 2
- }
- }
- layer {
- name: "norm1"
- type: "LRN"
- bottom: "pool1"
- top: "norm1"
- lrn_param {
- local_size: 5
- alpha: 0.0001
- beta: 0.75
- }
- }
- layer {
- name: "conv2"
- type: "Convolution"
- bottom: "norm1"
- top: "conv2"
- convolution_param {
- num_output: 256
- pad: 2
- kernel_size: 5
- group: 2
- }
- }
- layer {
- name: "relu2"
- type: "ReLU"
- bottom: "conv2"
- top: "conv2"
- }
- layer {
- name: "pool2"
- type: "Pooling"
- bottom: "conv2"
- top: "pool2"
- pooling_param {
- pool: MAX
- kernel_size: 3
- stride: 2
- }
- }
- layer {
- name: "norm2"
- type: "LRN"
- bottom: "pool2"
- top: "norm2"
- lrn_param {
- local_size: 5
- alpha: 0.0001
- beta: 0.75
- }
- }
- layer {
- name: "conv3"
- type: "Convolution"
- bottom: "norm2"
- top: "conv3"
- convolution_param {
- num_output: 384
- pad: 1
- kernel_size: 3
- }
- }
- layer {
- name: "relu3"
- type: "ReLU"
- bottom: "conv3"
- top: "conv3"
- }
- layer {
- name: "conv4"
- type: "Convolution"
- bottom: "conv3"
- top: "conv4"
- convolution_param {
- num_output: 384
- pad: 1
- kernel_size: 3
- group: 2
- }
- }
- layer {
- name: "relu4"
- type: "ReLU"
- bottom: "conv4"
- top: "conv4"
- }
- layer {
- name: "conv5"
- type: "Convolution"
- bottom: "conv4"
- top: "conv5"
- convolution_param {
- num_output: 256
- pad: 1
- kernel_size: 3
- group: 2
- }
- }
- layer {
- name: "relu5"
- type: "ReLU"
- bottom: "conv5"
- top: "conv5"
- }
- layer {
- name: "pool5"
- type: "Pooling"
- bottom: "conv5"
- top: "pool5"
- pooling_param {
- pool: MAX
- kernel_size: 3
- stride: 2
- }
- }
- layer {
- name: "fc6"
- type: "InnerProduct"
- bottom: "pool5"
- top: "fc6"
- inner_product_param {
- num_output: 4096
- }
- }
- layer {
- name: "relu6"
- type: "ReLU"
- bottom: "fc6"
- top: "fc6"
- }
- layer {
- name: "drop6"
- type: "Dropout"
- bottom: "fc6"
- top: "fc6"
- dropout_param {
- dropout_ratio: 0.5
- }
- }
- layer {
- name: "fc7"
- type: "InnerProduct"
- bottom: "fc6"
- top: "fc7"
- inner_product_param {
- num_output: 4096
- }
- }
- layer {
- name: "relu7"
- type: "ReLU"
- bottom: "fc7"
- top: "fc7"
- }
- layer {
- name: "drop7"
- type: "Dropout"
- bottom: "fc7"
- top: "fc7"
- dropout_param {
- dropout_ratio: 0.5
- }
- }
- layer {
- name: "fc8"
- type: "InnerProduct"
- bottom: "fc7"
- top: "fc8"
- inner_product_param {
- num_output: 5 #输出的类别
- }
- }
- layer {
- name: "prob"
- type: "Softmax"
- bottom: "fc8"
- top: "prob"
- }
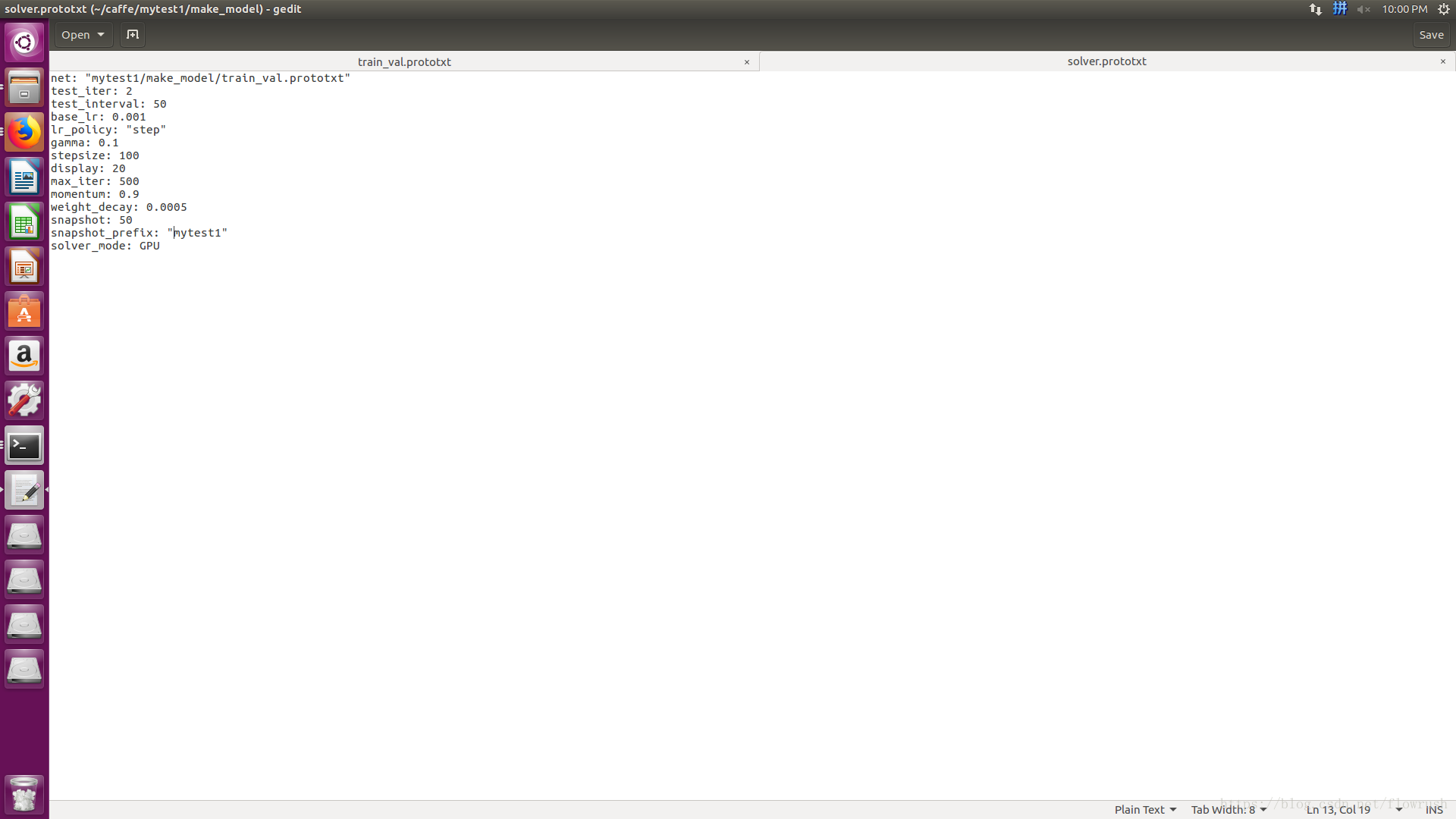
- net: "/home/dasuda/caffe-cnn/test_A/make_model/train_val.prototxt" #这里时train_val.prototxt文件的路径 把/home/dasuda/caffe-cnn/去掉
- test_iter: 2 #这个值乘以train_val.prototxt中第二个layer里面的batch_size等与你训练集的大小,我这里时50*2=100
- test_interval: 50
- base_lr: 0.001 #学习率
- lr_policy: "step"
- gamma: 0.1
- stepsize: 100
- display: 20
- max_iter: 500 #最大训练次数
- momentum: 0.9
- weight_decay: 0.0005
- snapshot: 50 #每50次保存一次模型快照,以便中断训练时继续训练,也可以
- snapshot_prefix: "/home/dasuda/caffe-cnn/test_A/finally_model/caffenet_train" #生成快照的路径
- solver_mode: CPU #训练的模式
Caffe实战Day4-开始模型训练
OK,我们已经来到了最后一步-模型的训练,前三篇文章,我们已经将训练模型所需的文件、数据都准备好了,接下来一条命令就可开始模型的训练。新建脚本或者你也可以直接输入命令:
- #!/usr/bin/env sh
- /home/dasuda/caffe/build/tools/caffe train \
- --solver=/home/dasuda/caffe-cnn/test_A/make_model/solver.prototxt
其中第一行是调用了caffe的工具train命令,第二行开头的参数--solver说明接下来是调用solver文件,后面跟你的solver文件路径即可,建议路径全部使用绝对路径。
运行脚本后:
- I0829 19:47:28.209851 3457 layer_factory.hpp:77] Creating layer data
- I0829 19:47:28.266258 3457 db_lmdb.cpp:35] Opened lmdb /home/dasuda/caffe-cnn/test_A/train_lmdb
- I0829 19:47:28.286499 3457 net.cpp:84] Creating Layer data
- I0829 19:47:28.286763 3457 net.cpp:380] data -> data
- I0829 19:47:28.288883 3457 net.cpp:380] data -> label
- I0829 19:47:28.288946 3457 data_transformer.cpp:25] Loading mean file from: /home/dasuda/caffe-cnn/test_A/train_mean.binaryproto
- I0829 19:47:28.314162 3457 data_layer.cpp:45] output data size: 32,3,227,227
- I0829 19:47:28.657215 3457 net.cpp:122] Setting up data
- I0829 19:47:28.657289 3457 net.cpp:129] Top shape: 32 3 227 227 (4946784)
- I0829 19:47:28.657311 3457 net.cpp:129] Top shape: 32 (32)
- I0829 19:47:28.657333 3457 net.cpp:137] Memory required for data: 19787264
- I0829 19:47:28.657356 3457 layer_factory.hpp:77] Creating layer conv1
- I0829 19:47:28.657395 3457 net.cpp:84] Creating Layer conv1
- I0829 19:47:28.657428 3457 net.cpp:406] conv1 <- data
- I0829 19:47:28.657459 3457 net.cpp:380] conv1 -> conv1
- I0829 19:47:28.663385 3457 net.cpp:122] Setting up conv1
- I0829 19:47:28.663475 3457 net.cpp:129] Top shape: 32 96 55 55 (9292800)
- I0829 19:47:28.663489 3457 net.cpp:137] Memory required for data: 56958464
- I0829 19:47:28.663663 3457 layer_factory.hpp:77] Creating layer relu1
- I0829 19:47:28.663693 3457 net.cpp:84] Creating Layer relu1
- I0829 19:47:28.663720 3457 net.cpp:406] relu1 <- conv1
- I0829 19:47:28.663738 3457 net.cpp:367] relu1 -> conv1 (in-place)
- I0829 19:47:28.664847 3457 net.cpp:122] Setting up relu1
- I0829 19:47:28.664887 3457 net.cpp:129] Top shape: 32 96 55 55 (9292800)
- I0829 19:47:28.664894 3457 net.cpp:137] Memory required for data: 94129664
- I0829 19:47:28.664899 3457 layer_factory.hpp:77] Creating layer pool1
- I0829 19:47:28.664932 3457 net.cpp:84] Creating Layer pool1
- I0829 19:47:28.664980 3457 net.cpp:406] pool1 <- conv1
- I0829 19:47:28.665011 3457 net.cpp:380] pool1 -> pool1
- I0829 19:47:28.665050 3457 net.cpp:122] Setting up pool1
- I0829 19:47:28.665076 3457 net.cpp:129] Top shape: 32 96 27 27 (2239488)
- I0829 19:47:28.665087 3457 net.cpp:137] Memory required for data: 103087616
- I0829 19:47:28.665094 3457 layer_factory.hpp:77] Creating layer norm1
- I0829 19:47:28.665136 3457 net.cpp:84] Creating Layer norm1
- I0829 19:47:28.665164 3457 net.cpp:406] norm1 <- pool1
- I0829 19:47:28.665223 3457 net.cpp:380] norm1 -> norm1
- I0829 19:47:28.665256 3457 net.cpp:122] Setting up norm1
- I0829 19:47:28.665285 3457 net.cpp:129] Top shape: 32 96 27 27 (2239488)
- I0829 19:47:28.665310 3457 net.cpp:137] Memory required for data: 112045568
- I0829 19:47:28.665323 3457 layer_factory.hpp:77] Creating layer conv2
- I0829 19:47:28.665351 3457 net.cpp:84] Creating Layer conv2
- I0829 19:47:48.050531 3457 solver.cpp:397] Test net output #0: accuracy = 0.2
- I0829 19:47:48.050607 3457 solver.cpp:397] Test net output #1: loss = 1.69832 (* 1 = 1.69832 loss)
- I0829 19:47:59.574867 3457 solver.cpp:218] Iteration 0 (-1.4013e-45 iter/s, 25.163s/20 iters), loss = 2.14062
- I0829 19:47:59.575369 3457 solver.cpp:237] Train net output #0: loss = 2.14062 (* 1 = 2.14062 loss)
- I0829 19:47:59.575387 3457 sgd_solver.cpp:105] Iteration 0, lr = 0.001
- I0829 19:49:30.509104 3460 data_layer.cpp:73] Restarting data prefetching from start.
- I0829 19:51:40.608665 3457 solver.cpp:218] Iteration 20 (0.0904842 iter/s, 221.033s/20 iters), loss = 3.89005
- I0829 19:51:40.608927 3457 solver.cpp:237] Train net output #0: loss = 3.89005 (* 1 = 3.89005 loss)
- I0829 19:51:40.608942 3457 sgd_solver.cpp:105] Iteration 20, lr = 0.001
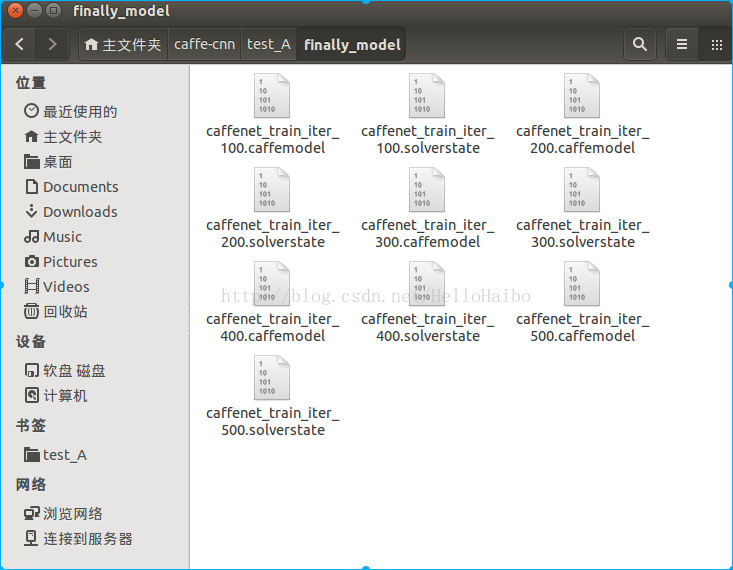
- I0829 20:05:52.601330 3457 solver.cpp:447] Snapshotting to binary proto file /home/dasuda/caffe-cnn/test_A/finally_model/caffenet_train_iter_100.caffemodel
- I0829 20:06:02.162716 3457 sgd_solver.cpp:273] Snapshotting solver state to binary proto file /home/dasuda/caffe-cnn/test_A/finally_model/caffenet_train_iter_100.solverstate
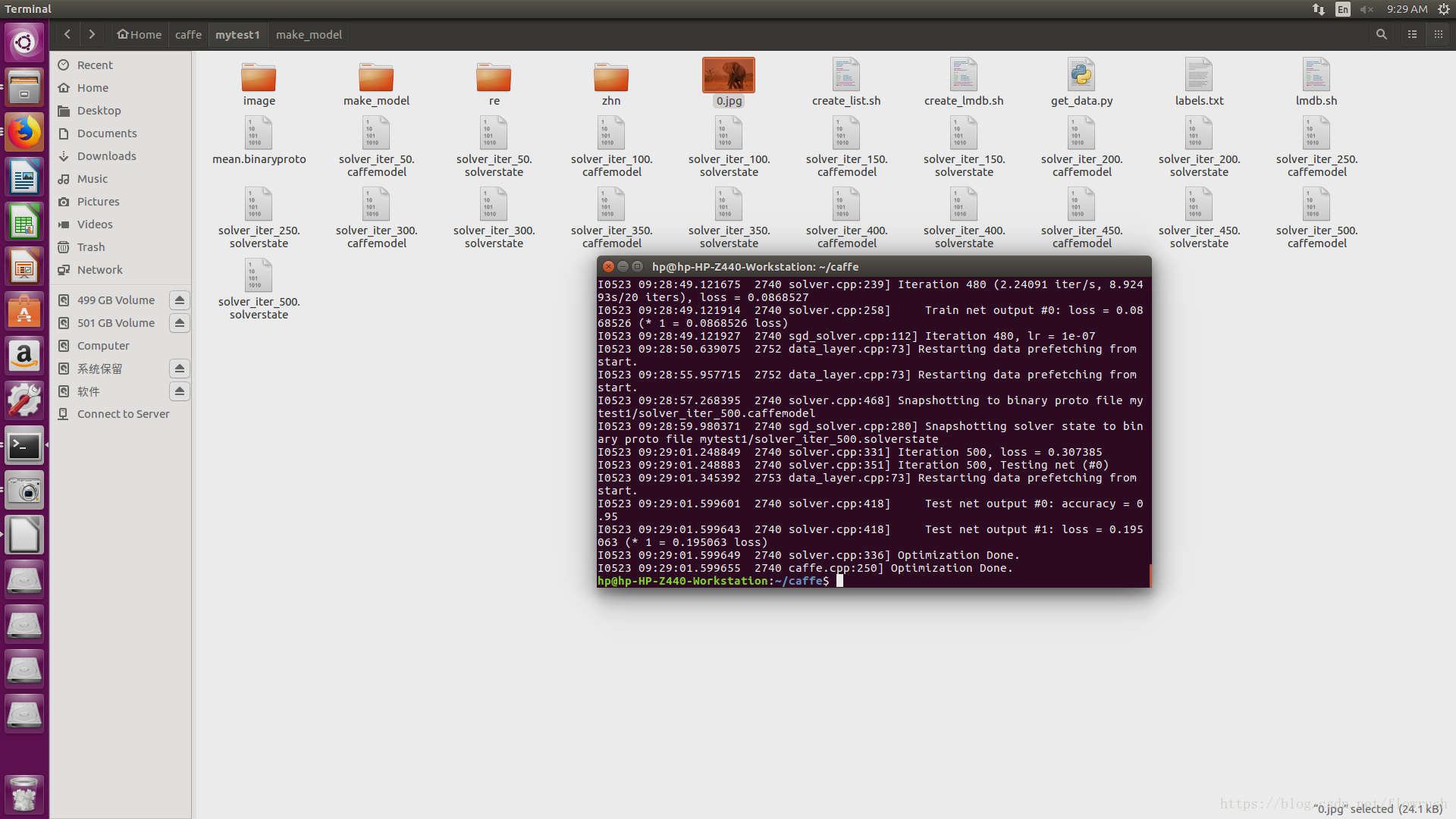
对于我来说,我用的虚拟机,CPU训练,大概需要1个半小时:
- I0829 21:16:03.929659 3457 sgd_solver.cpp:105] Iteration 480, lr = 1e-07
- I0829 21:16:34.835683 3460 data_layer.cpp:73] Restarting data prefetching from start.
- I0829 21:18:37.894023 3460 data_layer.cpp:73] Restarting data prefetching from start.
- I0829 21:19:19.841223 3457 solver.cpp:447] Snapshotting to binary proto file /home/dasuda/caffe-cnn/test_A/finally_model/caffenet_train_iter_500.caffemodel
- I0829 21:19:22.285903 3457 sgd_solver.cpp:273] Snapshotting solver state to binary proto file /home/dasuda/caffe-cnn/test_A/finally_model/caffenet_train_iter_500.solverstate
- I0829 21:19:28.835945 3457 solver.cpp:310] Iteration 500, loss = 0.143794
- I0829 21:19:28.836014 3457 solver.cpp:330] Iteration 500, Testing net (#0)
- I0829 21:19:28.877216 3463 data_layer.cpp:73] Restarting data prefetching from start.
- I0829 21:19:40.881701 3457 solver.cpp:397] Test net output #0: accuracy = 0.94
- I0829 21:19:40.881819 3457 solver.cpp:397] Test net output #1: loss = 0.232396 (* 1 = 0.232396 loss)
- I0829 21:19:40.881839 3457 solver.cpp:315] Optimization Done.
- I0829 21:19:40.881863 3457 caffe.cpp:259] Optimization Done.
注意:前面生成txt的label一定要从零开始,不然可能会出现loss=87.33情况。还有输出一定要改成你需要的。
其中caffenet_train_iter_500.caffemodel就是最终训练好的模型参数文件。
下面我们开始测试我们训练的网络:
从网上找到一张恐龙的照片命名为test0.jpg

然后cd到caffe/example/cpp_classification输入以下命令:
sudo ./classification.bin /home/dasuda/caffe-cnn/test_A/make_model/deploy.prototxt /home/dasuda/caffe-cnn/test_A/finally_model/caffenet_train_iter_500.caffemodel /home/dasuda/caffe-cnn/test_A/train_mean.binaryproto /home/dasuda/caffe-cnn/test_A/labels.txt /home/dasuda/caffe-cnn/test_A/test0.jpg
其中./classification.bin为当前目录下的一个文件,是官方提供的C++接口,是用来测试的,后面跟了5个参数分别是:网络结构文件,训练的模型参数文件,均值文件,标签文件,测试图片
标签文件格式:
新建txt文档labels.txt
0 bus
1 dinosaur
2 elephant
3 flower
4 horse
即序号和你之前的训练数据标签一致,至于后面的英文名称是方面你测试的。
预测输出:
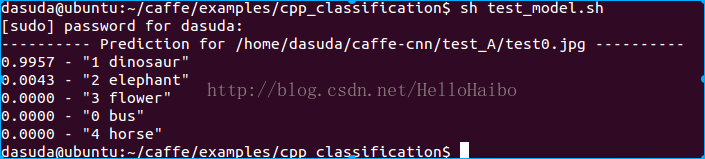
可见网络输出99.57%是恐龙,符合预期。
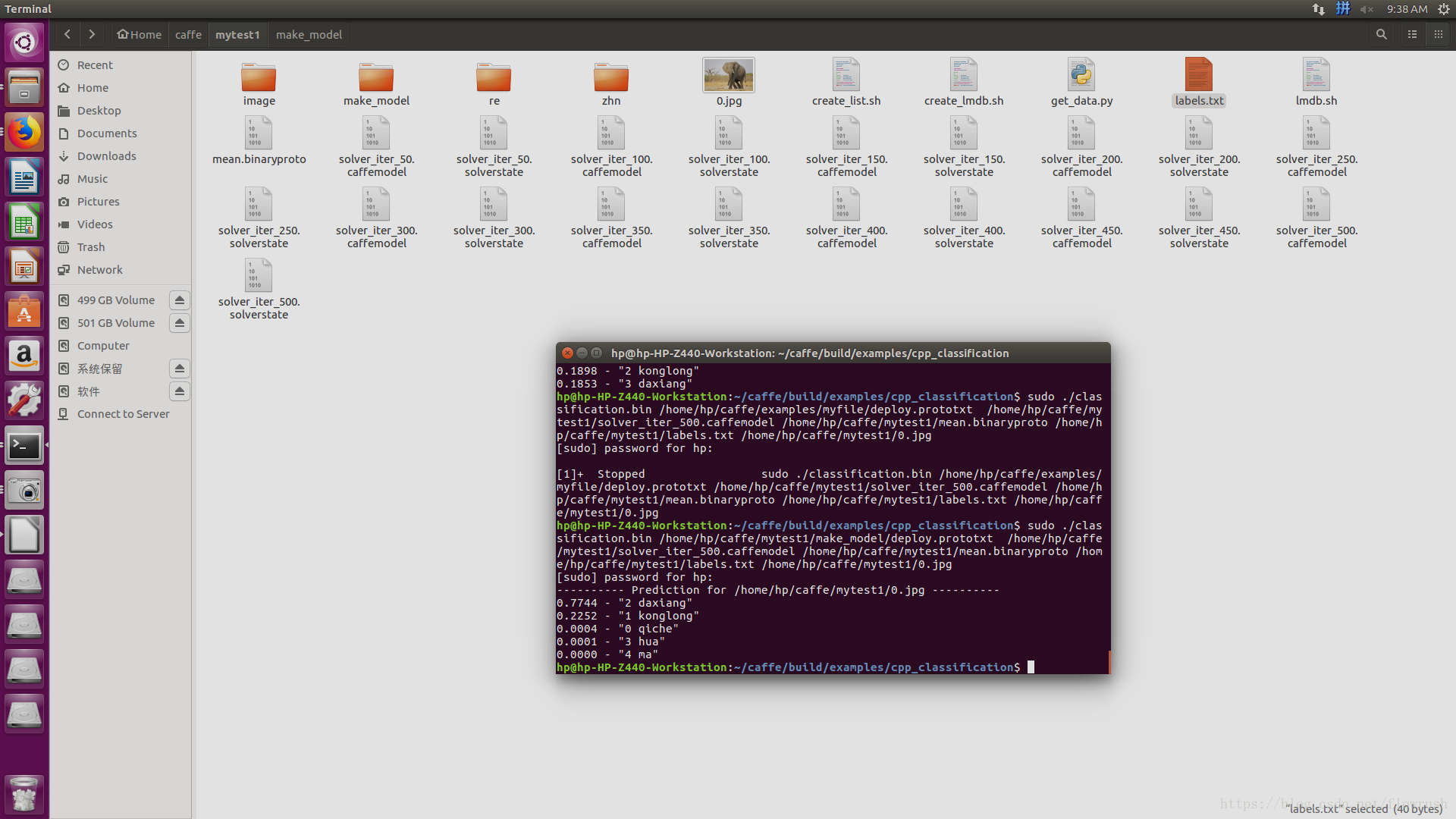
下面附上我的代码于结果
sudo ./classification.bin /home/hp/caffe/examples/myfile/deploy.prototxt /home/hp/caffe/mytest1/solver_iter_500.caffemodel /home/hp/caffe/mytest1/mean.binaryproto /home/hp/caffe/mytest1/labels.txt /home/hp/caffe/mytest1/0.jpg
Caffe实战Day5-使用opencv调用caffe模型进行分类
通过前面的文章,我们已经使用caffe训练了一个模型,下面我们在opencv中使用模型进行预测吧!
环境:OpenCV 3.3+VS2017
准备好三个文件:deploy.prototxt、caffemdel文件、标签文件labels.txt,建议大家按照前面的文章生成相应的文件,因为格式不同,可能程序运行会有错误。
1、修改deploy.prototxt文件
只需将输入层的格式修改一下:
将
- name: "CaffeNet"
- layer {
- name: "data"
- type: "Input"
- top: "data"
- input_param { shape: { dim: 10 dim: 3 dim: 227 dim: 227 } }
- }
- name: "CaffeNet"
- input: "data"
- input_dim: 10
- input_dim: 3
- input_dim: 227
- input_dim: 227
2、我将三个文件命名为:caffenet.prototxt、caffenet.caffemodel、labels.txt
3、VS新建工程,复制下面代码:
- #include <opencv2/dnn.hpp>
- #include <opencv2/imgproc.hpp>
- #include <opencv2/highgui.hpp>
- #include <opencv2/core/utils/trace.hpp>
- using namespace cv;
- using namespace cv::dnn;
- #include <fstream>
- #include <iostream>
- #include <cstdlib>
- using namespace std;
- //寻找出概率最高的一类
- static void getMaxClass(const Mat &probBlob, int *classId, double *classProb)
- {
- Mat probMat = probBlob.reshape(1, 1);
- Point classNumber;
- minMaxLoc(probMat, NULL, classProb, NULL, &classNumber);
- *classId = classNumber.x;
- }
- //从标签文件读取分类 空格为标志
- static std::vector<String> readClassNames(const char *filename = "labels.txt")
- {
- std::vector<String> classNames;
- std::ifstream fp(filename);
- if (!fp.is_open())
- {
- std::cerr << "File with classes labels not found: " << filename << std::endl;
- exit(-1);
- }
- std::string name;
- while (!fp.eof())
- {
- std::getline(fp, name);
- if (name.length())
- classNames.push_back(name.substr(name.find(' ') + 1));
- }
- fp.close();
- return classNames;
- }
- //主程序
- int main(int argc, char **argv)
- {
- //初始化
- CV_TRACE_FUNCTION();
- //读取模型参数和模型结构文件
- String modelTxt = "caffenet.prototxt";
- String modelBin = "caffenet.caffemodel";
- //读取图片
- String imageFile = (argc > 1) ? argv[1] : "test0.jpg";
- //合成网络
- Net net = dnn::readNetFromCaffe(modelTxt, modelBin);
- //判断网络是否生成成功
- if (net.empty())
- {
- std::cerr << "Can't load network by using the following files: " << std::endl;
- exit(-1);
- }
- cerr << "net read successfully" << endl;
- //读取图片
- Mat img = imread(imageFile);
- imshow("image", img);
- if (img.empty())
- {
- std::cerr << "Can't read image from the file: " << imageFile << std::endl;
- exit(-1);
- }
- cerr << "image read sucessfully" << endl;
- /* Mat inputBlob = blobFromImage(img, 1, Size(224, 224),
- Scalar(104, 117, 123)); */
- //构造blob,为传入网络做准备,图片不能直接进入网络
- Mat inputBlob = blobFromImage(img, 1, Size(227, 227));
- Mat prob;
- cv::TickMeter t;
- for (int i = 0; i < 10; i++)
- {
- CV_TRACE_REGION("forward");
- //将构建的blob传入网络data层
- net.setInput(inputBlob,"data");
- //计时
- t.start();
- //前向预测
- prob = net.forward("prob");
- //停止计时
- t.stop();
- }
- int classId;
- double classProb;
- //找出最高的概率ID存储在classId,对应的标签在classProb中
- getMaxClass(prob, &classId, &classProb);
- //打印出结果
- std::vector<String> classNames = readClassNames();
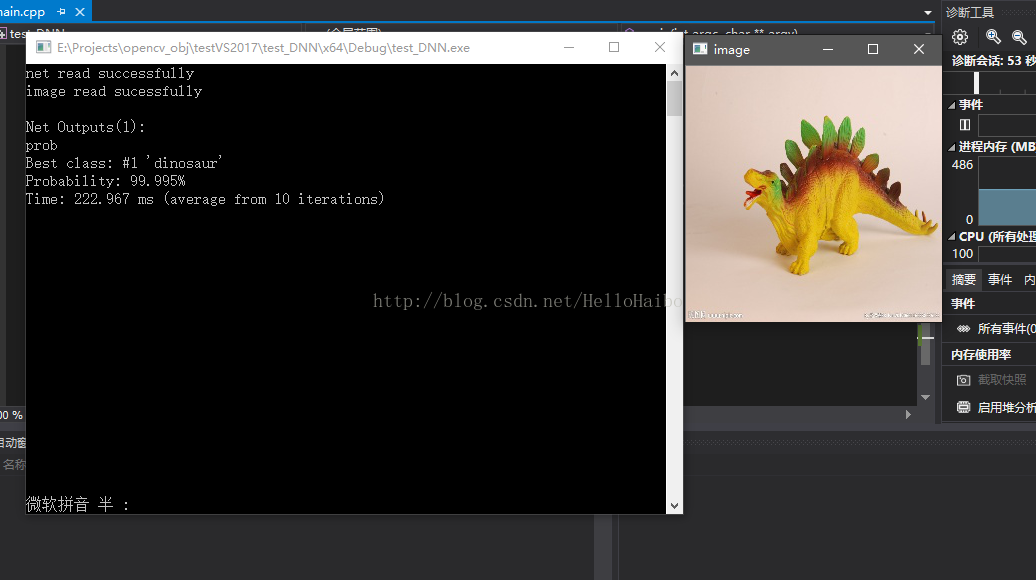
- std::cout << "Best class: #" << classId << " '" << classNames.at(classId) << "'" << std::endl;
- std::cout << "Probability: " << classProb * 100 << "%" << std::endl;
- //打印出花费时间
- std::cout << "Time: " << (double)t.getTimeMilli() / t.getCounter() << " ms (average from " << t.getCounter() << " iterations)" << std::endl;
- //便于观察结果
- waitKey(0);
- return 0;
- }

















 395
395

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









