




What?Why?How?
启蒙很重要!:学习知识的时候要去搞明白它存在的意义,这样学习的成本才会低,才会高效!
处理大数据问题的辩证
先思考这样一下需求:
我有一万个元素(比如数字或单词)需要存储,你会怎么存?
如果查找某一个元素,最简单的遍历方式复杂的是多少?
如果我期望复杂度是O(4)呢?

分治思想
简单的分治思路:为了说而说的
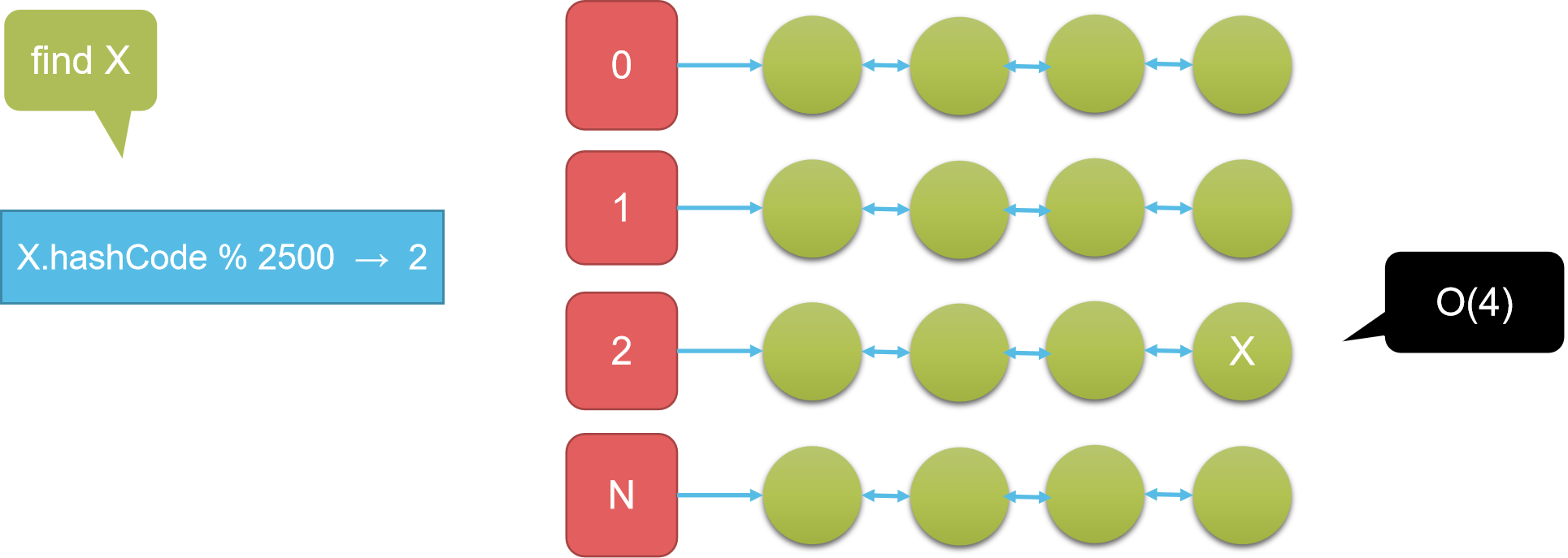
一个对象取hashCode,简单来说就是一个“唯一的”数值
模2500,1万个就分为了0~2499即2500组,每组长度平均是4,查找一个元素的时间复杂度就是TO(4)
数组管理这些链
分而治之的思想出现在了很多地方:很重要
Redis 集群、ElasticSearch、Hbase
Hadoop 生态中分治更是无处不在!
大数据:首先是数据量特别大,就以1TB为例
1TB = 1024GB = 1024MB * 1024(记住这个)
提需求:
有一个非常大的文本文件1TB,里面有很多很多的行,只有两行一样,它们出现在未知的位置,现在我就想找到它们,你来帮我找到它
单机(分钟级)
单机想处理1TB的数据,而且你是个小白,想想单机的过程是什么、会有什么缺点:
单机,想想你装的虚拟机,可用的内存很少,也就几G、最多十几B
所以:单机处理大数据就要多次 IO ,因此,
IO 是单机最大的瓶颈,大牛很多高级技术都是在尽可能的规避 IO
IO 时间单位 毫秒ms级别
测试,网络就是一个 IO
ping ali.com / 3.33.139.32
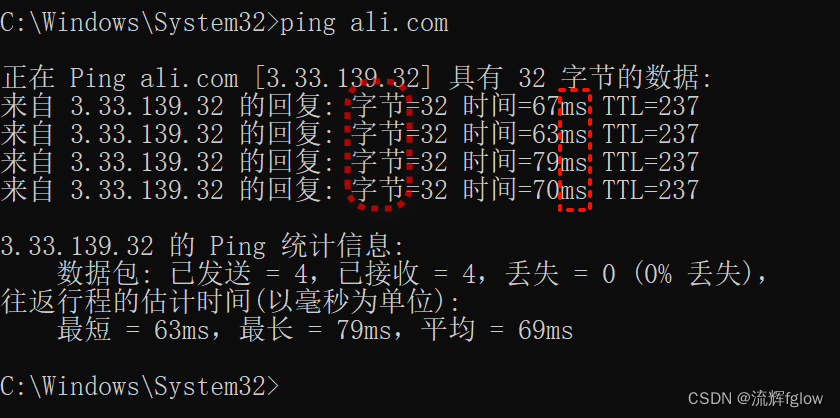
从感受来说,还是需要点时间的吧,那么想想:很多次这样后会怎样?
回到这个需求
寻找重复行
常规:读一行就要跟剩下的比较,复杂度就是读n次文件
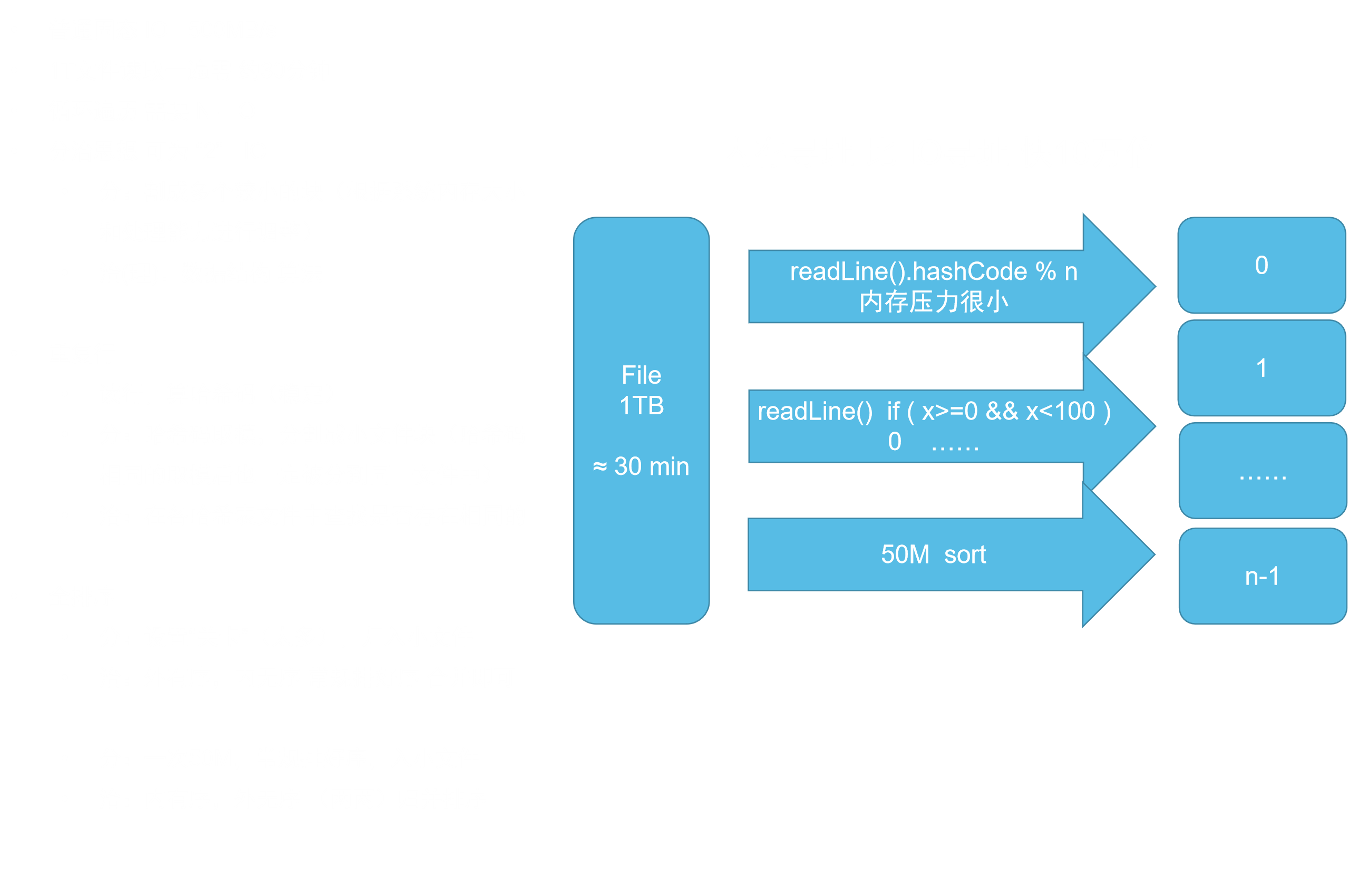
分治:按行读为一个字符串对象,相同的字符串,hashCode必然相同,就被分到同一文件中,再遍历一次这些小文件就能找到;即:只需读两次文件
再送你一个例子:1T的全排序
根本不可能将1T的数据都读到内存后,再一次排好序的
全排序的两种分治思路,且“分”后的数据情况 会影响 “治”的算法
- 设“关卡”,遍历一次,分配到不同的小文件,如0100的是file0,100200是file1,……
- 数据情况:小文件间是有序的,小文件内无序
- 治:每个文件内常规排好序,再将文件按顺序合并即可
- 一次取50MB,排好序,存到小文件中,重复此操作
- 数据情况:小文件内有序,小文件间无序
- 治:使用归并排序思路,两两小文件合并
分治法:
- 将一次处理不了的大数据量,分为多次小数据量的,变为可以处理了
- 大大减少了IO的次数
现有硬件IO速度读1T的数据根本不可能达到秒级
单机的瓶颈在IO:硬盘太慢,内存太小
当然也有内存大的,但只有超级大公司能消费得起
SAP 公司的 HANA DB 是内存级的关系型数据库,软硬件要绑定着卖一套(2亿↑),服务器内存(2T↑)
集群分布式(秒级)
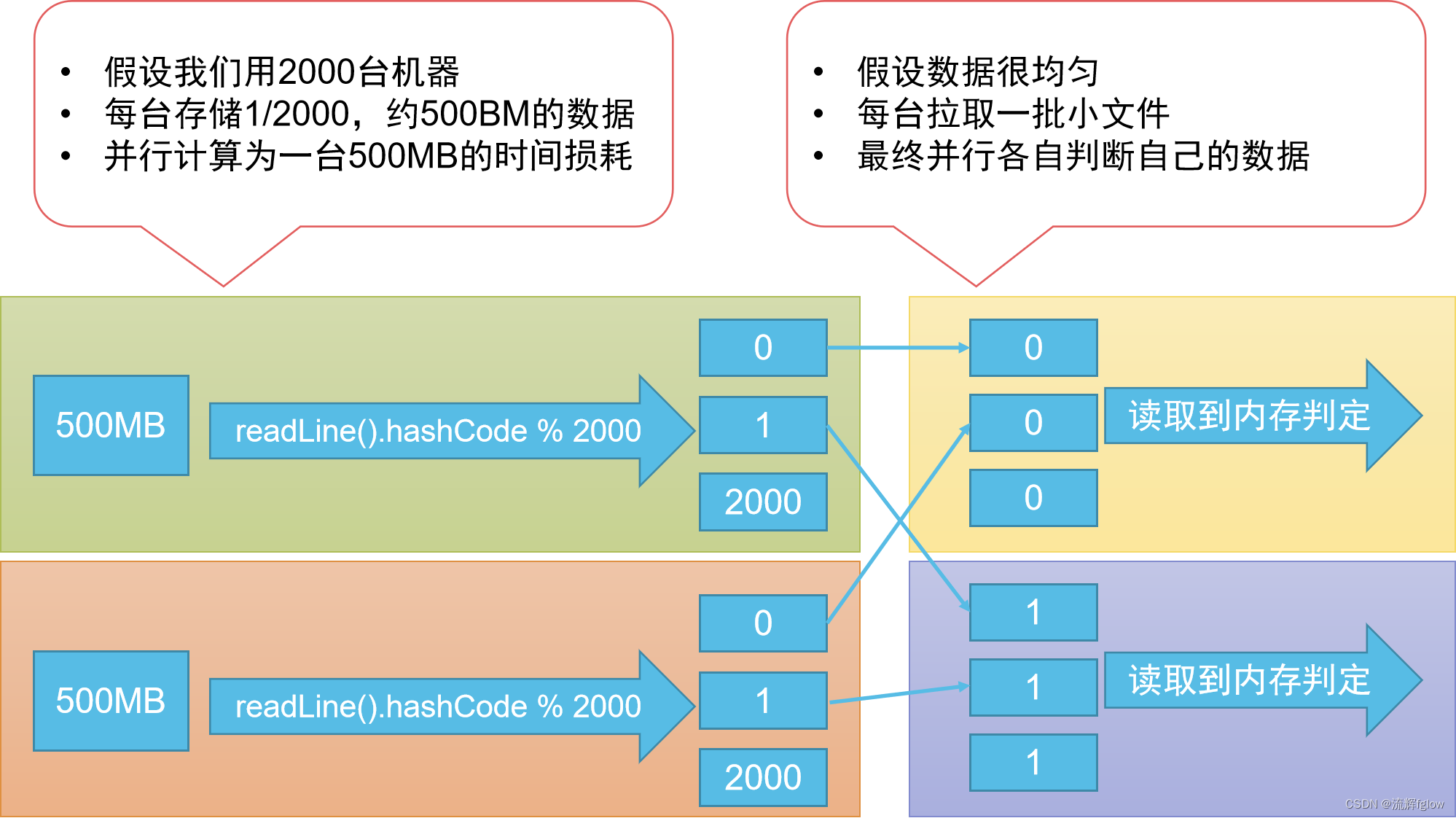
多机并行协同,先跟着我的思路看:怎么达到“秒级”
因为并行的,就想想两台机是怎么工作的就可以了,再推广到更多也是一样的
- 2000台机,每台机就拿500M的数据处理
- readLine算hashCode,将readLine分到2000个小文件中,时间是稳定的吧,秒级
- 每台机都有两千个小文件,将编号相同的合并?因为编号相同的原本在单机的时候,就是在一个小文件中的,现在多机分开了,自然要给合并的。就解释到这,点到为止,可以自己想想
- 合并好了很小的文件,以下都是说这个合并好的文件,还是有2000个,那么每台只有一个文件,都是500MB(别说特殊情况,“分治”的算法是好算法,那么就是500M加点误差)
- 读到内存去处理,从硬盘读500M,秒级
- 500M的计算也快,秒级
那么,你会感觉是不是:中间的过程最复杂,应该耗时也最多,上述的其他操作都是秒级
因为数据量很小,可以粗略估计一下中间过程,最多就1分钟
那么总体就是秒级
现在,你心中肯定会有疑问:这500M文件是怎么来的?
按照上述能达到秒级的过程,是漏了上传1T文件和分配的过程
现在就来看看该过程:
集群怎么通信的?网络
网络IO多快呢?肯定比硬盘慢,网卡就100MB/s
读和分文件的时间 5 倍,近三个小时
这里三个小时,你其他的再快也没用啊,集群真辣鸡!
花了两千台的钱,还没单机的快!还更慢了
更本质的原因在于:
移动/拷贝 数据的成本很高,不把数据向计算移动,
另辟蹊径:计算向数据移动
不要将数据移动到计算,应该将计算移动到数据
数据向计算移动:数据读到内存,再计算,因为传统计算程序只能到内存拿数据
计算向数据移动:数据不动,计算程序移到你的数据上,代价就很小
小数据量时,两者没差距
集群分布式处理大数据的辩证
集群分布式处理大数据的辩证 :2000台真的比一台速度快吗?
思考一下问题:
- 如果考虑分发上传文件的时间呢?
- 如果考虑每天都有1T数据的产生呢?
- 如果增量了一年,最后一天计算数据呢?
单机和多机的区别:能否存数据、每次需要都需要重新读
多机-可存,单机-不可存
集群主要处理增量,因为并行计算很快占比小
问题最主要在于:数据的移动传输
在上面见识到,集群干不过单机。主要的原因:一个数据是本地化读取,一个是通过网络读取
要意识到这是单次的差别
那么以动态发展的眼光,假设一天新增1T
集群 什么时候能追平 单机
假设:机子数(定值) = 数据增量 / 传输速率,知道是个定值即可
1T / 500M ≈ 2000台
过程:
多机每天都是“固定”时长(只需着重处理增量网络上传即可,以前的已存在,并行计算很快)
单机每天的时长时递增的(存不了,需重新上传)
一年后,就读365T的数据,需要180h,一个多星期了,时效性都没了
结论:
第 速率倍数 天能追平,就慢你这几次,反超后,越后面就越“遥遥领先”了
即 第5天 = 500M/s / 100M/s
只有当数据量达到一定程度,也就是大公司,才开始要考虑部署集群,企业要考虑经济效益嘛
例:
某付宝 年终报表(钱都花去哪里了),且是每个人过去一年的数据
发现在新年第一天就生成好了(且包含了昨天的数据)
反推是用集群的

















 1633
1633

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









