






 本文详细介绍了B树和B+树的概念及其在数据库索引中的应用,对比了这两种树形结构的特点,并探讨了它们相对于哈希索引的优势。
本文详细介绍了B树和B+树的概念及其在数据库索引中的应用,对比了这两种树形结构的特点,并探讨了它们相对于哈希索引的优势。
1. Btree:
-
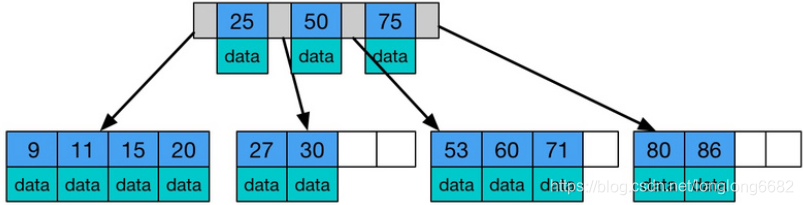
B-tree是一种多路自平衡搜索树,它类似普通的二叉树,但是Btree允许每个节点有更多的子节点。Btree示意图如下:
-
B树的搜索,从根结点开始,如果查询的关键字与结点的关键字相等,那么就命中;否则,如果查询关键字比结点关键字小,就进入左儿子;如果比结点关键字大,就进入右儿子;如果左儿子或右儿子的指针为空,则报告找不到相应的关键字;
-
如果B树的所有非叶子结点的左右子树的结点数目均保持差不多(平衡),那么B树的搜索性能逼近二分查找;但它比连续内存空间的二分查找的优点是,改变B树结构(插入与删除结点)不需要移动大段的内存数据,甚至通常是常数开销;
-
右边也是一个B树,但它的搜索性能已经是线性的了;同样的关键字集合有可能导致不同的树结构索引;所以,使用B树还要考虑尽可能让B树保持左图的结构,和避免右图的结构,也就是所谓的“平衡”问题;
-
实际使用的B树都是在原B树的基础上加上平衡算法,即“平衡二叉树”;如何保持B树结点分布均匀的平衡算法是平衡二叉树的关键;平衡算法是一种在B树中插入和删除结点的策略;
由上图可知 Btree 的一些特点:
- 所有键值分布在整个树中
- 任何关键字出现且只出现在一个节点中
- 搜索有可能在非叶子节点结束
- 在关键字全集内做一次查找,性能逼近二分查找算法
2. B+tree:
B+tree是Btree的变体,也是一种多路搜索树:
1.其定义基本与B-树同,除了:
2.非叶子结点的子树指针与关键字个数相同;
3.非叶子结点的子树指针P[i],指向关键字值属于[K[i], K[i+1])的子树(B-树是开区间);
5.为所有叶子结点增加一个链指针;
6.所有关键字都在叶子结点出现;
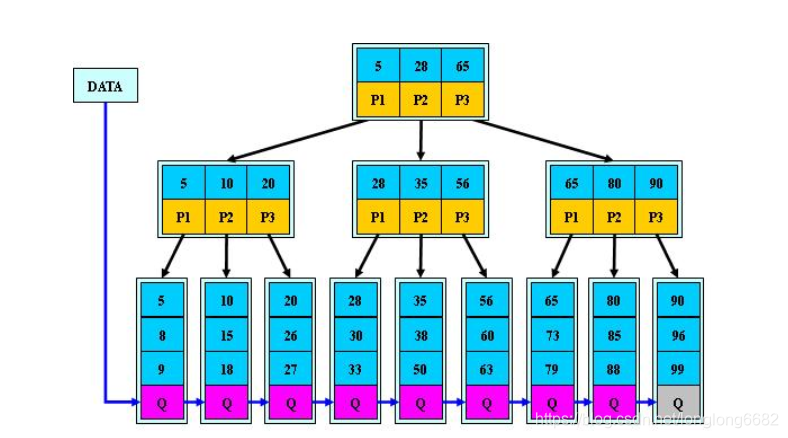
- B+的搜索与B-树也基本相同,区别是B+树只有达到叶子结点才命中(B-树可以在非叶子结点命中),其性能也等价于在关键字全集做一次二分查找;
B+tree的特性:
1.所有关键字都出现在叶子结点的链表中(稠密索引),且链表中的关键字恰好是有序的;
2.不可能在非叶子结点命中;
3.非叶子结点相当于是叶子结点的索引(稀疏索引),叶子结点相当于是存储(关键字)数据的数据层;
4.更适合文件索引系统;
btree和B+tree的区别:
- (1)B+tree的非叶子节点不存储真正的data,而btree可以
- (2)增加了一个链指针
- (3)btree支持数据的延展性,B+tree支持数据的扩展性
B*Tree:
是B+树的变体,在B+树的非根和非叶子结点再增加指向兄弟的指针;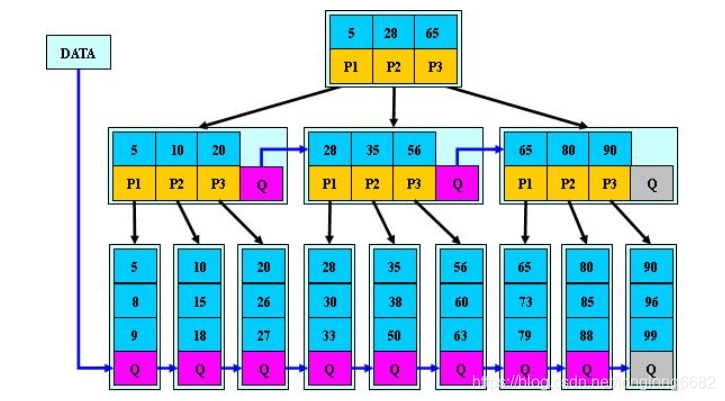
- B*树定义了非叶子结点关键字个数至少为(2/3)*M,即块的最低使用率为2/3(代替B+树的1/2);
- B+树的分裂:当一个结点满时,分配一个新的结点,并将原结点中1/2的数据复制到新结点,最后在父结点中增加新结点的指针;B+树的分裂只影响原结点和父结点,而不会影响兄弟结点,所以它不需要指向兄弟的指针;
- B*树的分裂:当一个结点满时,如果它的下一个兄弟结点未满,那么将一部分数据移到兄弟结点中,再在原结点插入关键字,最后修改父结点中兄弟结点的关键字(因为兄弟结点的关键字范围改变了);如果兄弟也满了,则在原结点与兄弟结点之间增加新结点,并各复制1/3的数据到新结点,最后在父结点增加新结点的指针;
- 所以,B*树分配新结点的概率比B+树要低,空间使用率更高;
三. B-tree与哈希索引的区别
1)B+tree的索引:
- 是按照顺序存储的,所以,如果按照B+tree索引,可以直接返回,带顺序的数据,但这个数据只是该索引列含有的信息。因此是顺序I/O
- 适用于: 精确匹配 、范围匹配 、最左匹配
2)Hash索引:
为什么mysql的索引使用B+树而不是B树呢??
(1)B+树更适合外部存储(一般指磁盘存储),由于内节点(非叶子节点)不存储data,所以一个节点可以存储更多的内节点,每个节点能索引的范围更大更精确。也就是说使用B+树单次磁盘IO的信息量相比较B树更大,IO效率更高。
(2)mysql是关系型数据库,经常会按照区间来访问某个索引列,B+树的叶子节点间按顺序建立了链指针,加强了区间访问性,所以B+树对索引列上的区间范围查询很友好。而B树每个节点的key和data在一起,无法进行区间查找。
(1)由于磁盘顺序读取的效率很高(不需要寻道时间,只需很少的旋转时间),
因此对于具有局部性的程序来说,预读可以提高I/O效率.预读的长度一般为页(page)的整倍数。
(2)MySQL(默认使用InnoDB引擎),将记录按照页的方式进行管理,每页大小默认为16K(这个值可以修改)。linux 默认页大小为4K。
B-Tree借助计算机磁盘预读的机制,并使用如下技巧:
每次新建节点时,直接申请一个页的空间,这样就保证一个节点物理上也存储在一个页里,加之计算机存储分配都是按页对齐的,就实现了一个结点只需一次I/O。
假设 B-Tree 的高度为 h,B-Tree中一次检索最多需要h-1次I/O(根节点常驻内存),渐进复杂度为O(h)=O(logdN)O(h)=O(logdN)。一般实际应用中,出度d是非常大的数字,通常超过100,因此h非常小(通常不超过3,也即索引的B+树层次一般不超过三层,所以查找效率很高)。
而红黑树这种结构,h明显要深的多。由于逻辑上很近的节点(父子)物理上可能很远,无法利用局部性,所以红黑树的I/O渐进复杂度也为O(h),效率明显比B-Tree差很多。
- 索引列值的哈希值+数据行指针:因此找到后还需要根据指针去找数据,造成随机I/O
- 适合: 精确匹配
- 不适合: 模糊匹配 、范围匹配 、不能排序
那么问题来了,为什么用B/B+树这种结构来实现索引呢??
答:红黑树等结构也可以用来实现索引,但是文件系统及数据库系统普遍使用B/B+树结构来实现索引。mysql是基于磁盘的数据库,索引是以索引文件的形式存在于磁盘中的,索引的查找过程就会涉及到磁盘IO(为什么涉及到磁盘IO请看文章后面的附加理解部分)消耗,磁盘IO的消耗相比较于内存IO的消耗要高好几个数量级,所以索引的组织结构要设计得在查找关键字时要尽量减少磁盘IO的次数。为什么要使用B/B+树,跟磁盘的存储原理有关。局部性原理与磁盘预读
为了提升效率,要尽量减少磁盘IO的次数。实际过程中,磁盘并不是每次严格按需读取,而是每次都会预读。磁盘读取完需要的数据后,会按顺序再多读一部分数据到内存中,这样做的理论依据是计算机科学中注明的局部性原理: -
当一个数据被用到时,其附近的数据也通常会马上被使用 -
程序运行期间所需要的数据通常比较集中
(1)由于磁盘顺序读取的效率很高(不需要寻道时间,只需很少的旋转时间),
因此对于具有局部性的程序来说,预读可以提高I/O效率.预读的长度一般为页(page)的整倍数。
(2)MySQL(默认使用InnoDB引擎),将记录按照页的方式进行管理,每页大小默认为16K(这个值可以修改)。linux 默认页大小为4K。
B-Tree借助计算机磁盘预读的机制,并使用如下技巧:
每次新建节点时,直接申请一个页的空间,这样就保证一个节点物理上也存储在一个页里,加之计算机存储分配都是按页对齐的,就实现了一个结点只需一次I/O。
假设 B-Tree 的高度为 h,B-Tree中一次检索最多需要h-1次I/O(根节点常驻内存),渐进复杂度为O(h)=O(logdN)O(h)=O(logdN)。一般实际应用中,出度d是非常大的数字,通常超过100,因此h非常小(通常不超过3,也即索引的B+树层次一般不超过三层,所以查找效率很高)。
而红黑树这种结构,h明显要深的多。由于逻辑上很近的节点(父子)物理上可能很远,无法利用局部性,所以红黑树的I/O渐进复杂度也为O(h),效率明显比B-Tree差很多。
为什么mysql的索引使用B+树而不是B树呢??
(1)B+树更适合外部存储(一般指磁盘存储),由于内节点(非叶子节点)不存储data,所以一个节点可以存储更多的内节点,每个节点能索引的范围更大更精确。也就是说使用B+树单次磁盘IO的信息量相比较B树更大,IO效率更高。
(2)mysql是关系型数据库,经常会按照区间来访问某个索引列,B+树的叶子节点间按顺序建立了链指针,加强了区间访问性,所以B+树对索引列上的区间范围查询很友好。而B树每个节点的key和data在一起,无法进行区间查找。


















 2362
2362

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











