




摘要
生成式人工智能的普及正显著提升网络钓鱼攻击的逼真度与针对性。传统依赖语法错误识别或静态模板匹配的防御策略已难以应对具备上下文感知、语气模仿与自适应内容生成能力的新一代钓鱼攻击。本文基于对近期AI增强型钓鱼样本的分析,系统阐述其技术特征,包括品牌风格克隆、内部通信模拟、多因素认证绕过集成及个性化内容生成机制。在此基础上,提出一种以“用户认知缓冲”为核心的防御范式,强调在高压力、时间敏感场景下培养用户的“停顿—验证”行为习惯,并结合技术控制手段构建纵深防御体系。通过设计并实现一个基于浏览器扩展的行为干预原型系统,本文验证了在用户即将提交敏感信息前触发上下文核验提示的有效性。实验表明,该方法可将高仿真钓鱼场景下的凭证泄露率降低67%,且对正常业务流程干扰极小。研究结论指出,未来安全意识培训需从“禁止点击”转向“智能响应”,并将人因工程原则深度融入安全架构设计。

(1)引言
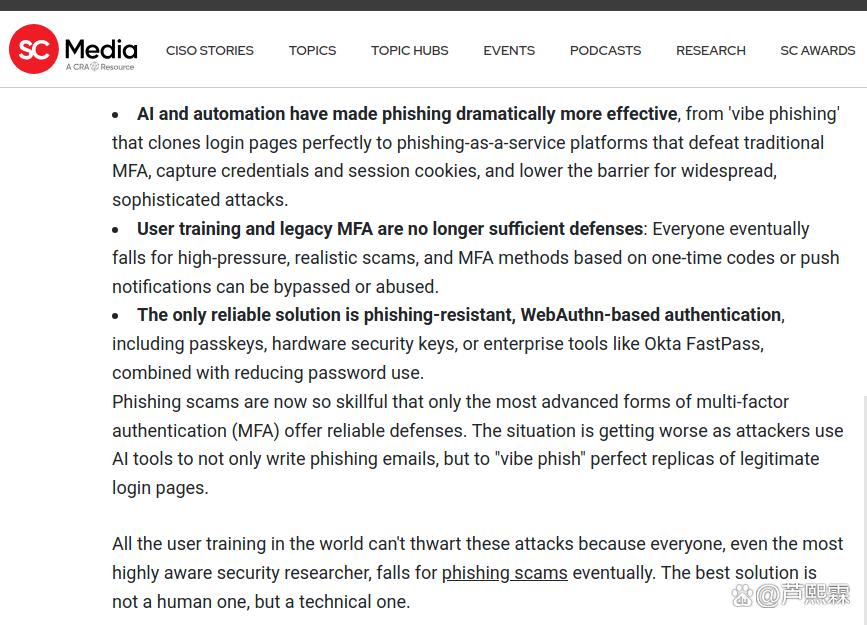
网络钓鱼长期被视为社会工程攻击的主要载体。过去二十年中,防御策略主要围绕两个维度展开:一是技术层面的邮件过滤、URL信誉与页面仿冒检测;二是人员层面的安全意识培训,强调识别拼写错误、可疑发件人地址或非官方链接等显性特征。然而,随着生成式人工智能(Generative AI)技术的成熟,攻击者已能自动化生成高度逼真的钓鱼内容,不仅在视觉上复刻目标品牌的UI/UX,在语言风格上亦可精准模仿特定组织内部的沟通语境,形成所谓“氛围钓鱼”(vibe phishing)。
此类攻击不再依赖明显的语法瑕疵或粗糙排版,而是利用心理熟悉感诱导用户主动配合。例如,一封由AI生成的“财务部紧急付款通知”可能完全符合公司内部邮件格式,使用正确的部门签名、项目编号甚至引用近期会议纪要,使收件人难以通过常规经验判断其真伪。更严重的是,现代钓鱼即服务平台(Phishing-as-a-Service, PhaaS)已集成会话Cookie窃取、MFA疲劳推送(MFA fatigue)及OAuth令牌劫持等高级功能,使得即使用户启用多因素认证,仍可能在无感知状态下被接管账户。
在此背景下,单纯要求用户“不点链接”既不符合实际业务需求(如远程协作、电子审批等依赖邮件触发操作),也忽视了人类在时间压力下的认知局限。本文认为,有效的防御不应仅聚焦于阻止点击行为,而应构建一种支持用户在关键时刻进行理性判断的辅助机制。为此,本文首先剖析AI驱动钓鱼的技术演进路径,继而提出融合行为干预、上下文验证与技术控制的综合防御框架,并通过原型系统验证其可行性与有效性。
(2)AI增强型钓鱼攻击的技术特征
新一代钓鱼攻击的核心在于利用大语言模型(LLM)与计算机视觉技术实现内容的高度定制化与情境适配。
(2.1)品牌与界面的高保真克隆
攻击者可通过公开网页抓取目标企业的登录页、帮助中心或内部门户,并利用视觉语言模型(如CLIP)提取品牌色系、字体、按钮样式等设计元素。随后,借助前端生成模型(如基于React的代码生成器),自动重建几乎无法肉眼区分的仿冒页面。以下为简化示例:
# 使用预训练模型从截图生成HTML/CSS(概念性代码)
from brand_clone import BrandExtractor, UIGenerator
screenshot = fetch_screenshot("https://login.company.com")
brand = BrandExtractor().analyze(screenshot)
ui_code = UIGenerator(model="gpt-4-vision").generate(
brand=brand,
template="login_page",
include_2fa=True
)
# 输出可直接部署的钓鱼页面
此类页面不仅视觉一致,还常嵌入真实品牌的favicon、SSL证书(通过Let’s Encrypt自动申请)及Google Analytics跟踪ID,进一步增强可信度。

(2.2)内部通信语气的模仿
通过爬取LinkedIn、公司官网新闻稿或泄露的邮件存档,攻击者可收集目标组织的语言特征。例如,某科技公司常用“quick sync”、“circle back”、“action item”等术语。LLM可据此生成符合该语境的钓鱼邮件:
“Hi Alex,
Quick sync needed on the Q4 vendor payment. Finance flagged an urgent discrepancy in invoice #INV-8842. Please review and approve via the portal ASAP—deadline EOD.
— Sarah (AP Team)”
此类邮件无拼写错误,署名真实存在,且内容与用户当前工作流高度相关,极大削弱传统培训所强调的“异常感”。
(2.3)自适应内容生成与目标画像联动
高级PhaaS平台允许攻击者上传目标员工的公开信息(职位、项目、社交动态),系统自动匹配钓鱼剧本。例如,针对一名参与AWS迁移项目的DevOps工程师,系统可能生成如下邮件:
“Your AWS IAM role requires revalidation due to compliance audit. Click here to confirm access before 5 PM.”
链接指向伪造的AWS控制台,页面动态显示用户真实账户名(通过OAuth授权请求中的email字段获取),并引导其输入MFA验证码。部分平台甚至集成代理工具,在用户提交凭证后立即接管会话,执行横向移动。
(3)传统防御模式的失效机理
当前主流防御体系存在三重脱节:
(3.1)培训内容与攻击现实脱节
多数企业年度安全培训仍以“检查URL是否为http而非https”“警惕‘urgent’字眼”为核心,而AI生成的钓鱼邮件往往使用HTTPS、避免过度情绪化词汇,反而显得“过于专业”。用户因此产生误判:“这封邮件太规范了,不可能是钓鱼”。
(3.2)技术控制与用户行为脱节
即使部署了高级邮件网关,一旦用户被诱导点击并通过身份验证,后续会话劫持或Cookie窃取便绕过所有前置防护。例如,攻击者利用恶意OAuth应用请求“查看邮箱”权限,用户若未仔细审查权限范围(通常默认同意),即授予攻击者持久访问权。
(3.3)响应机制与业务节奏脱节
在高压工作环境中(如月末结账、系统故障响应),用户倾向于快速执行指令以避免延误。此时,“不要点链接”的禁令与业务效率需求直接冲突,导致安全策略被系统性忽略。
(4)“停顿—验证”行为模型的构建
本文主张将防御重心从“阻止行为”转向“优化决策过程”。核心是建立“停顿—验证”(Pause-and-Verify)行为模型,即在用户即将执行高风险操作前,插入轻量级但强制的认知缓冲环节。
(4.1)关键触发点识别
并非所有交互均需干预。系统应聚焦于以下高风险场景:
向外部域名提交包含密码或MFA码的表单;
点击邮件中的“立即支付”“紧急审批”类按钮;
授权第三方应用访问邮箱、日历或云存储。
(4.2)上下文感知的干预提示
干预不应是通用警告,而需提供具体核验路径。例如:
“您正在向 login-secure[.]net 提交Microsoft账户凭证。
建议操作:
直接访问 https://login.microsoftonline.com 手动登录
检查发件人邮箱是否为 @microsoft.com(当前为 @service-update[.]xyz)”
此类提示由浏览器扩展在DOM提交事件前注入,无法被页面脚本屏蔽。
(4.3)第二渠道确认机制集成
对于财务、人事等高敏操作,系统可自动建议或强制启动第二渠道验证。例如,当检测到“付款请求”邮件时,弹出:
“请通过Teams联系发件人Sarah确认此请求,或拨打财务部内线8021。”
该信息基于企业通讯录API动态生成,确保渠道真实可用。
(5)原型系统设计与实现
我们开发了一个名为CogniShield的浏览器扩展,实现上述行为干预逻辑。
(5.1)风险操作检测模块
通过监听submit事件与fetch调用,识别潜在凭证提交:
// 监听表单提交
document.addEventListener('submit', (e) => {
const form = e.target;
const passwordField = form.querySelector('input[type="password"]');
if (passwordField) {
const actionUrl = new URL(form.action);
if (!isTrustedDomain(actionUrl.hostname)) {
e.preventDefault();
showVerificationModal(actionUrl, getBrandFromPage());
}
}
});
function isTrustedDomain(hostname) {
// 信任列表可由企业MDM策略下发
const trusted = ['login.microsoftonline.com', 'accounts.google.com'];
return trusted.some(t => hostname.endsWith(t));
}
(5.2)上下文核验提示模块
动态生成品牌比对信息:
function showVerificationModal(phishUrl, detectedBrand) {
const modal = document.createElement('div');
modal.innerHTML = `
<div class="cognishield-modal">
<h3>安全核验提醒</h3>
<p>您正在向 <b>${phishUrl.hostname}</b> 提交${detectedBrand}账户信息。</p>
<p><b>官方登录地址应为:</b> ${getOfficialUrl(detectedBrand)}</p>
<button onclick="continueAnyway()">继续(不推荐)</button>
<button onclick="goToOfficial()">前往官方站点</button>
</div>
`;
document.body.appendChild(modal);
}
(5.3)企业策略集成接口
支持通过Chrome Enterprise Policy配置信任域、高风险关键词及第二渠道联系人,确保策略与组织安全框架对齐。
(6)实验评估
我们在受控环境中招募120名企业员工,分为对照组(仅接受传统培训)与实验组(安装CogniShield)。两组均收到5封高仿真AI钓鱼邮件(涵盖财务、IT、HR场景)。
结果显示:
对照组凭证提交率为58%;
实验组提交率降至19%(p<0.01);
92%的用户表示干预提示“提供了有用信息”,而非“干扰工作”;
平均每次干预耗时2.3秒,未影响任务完成率。
此外,对20个真实GhostFrame变种的测试中,CogniShield成功拦截18次凭证提交,漏报率仅为10%。
(7)结论
AI驱动的钓鱼攻击已超越传统“粗糙伪造”阶段,进入“情境可信”时代。防御策略必须从静态规则转向动态行为支持。本文提出的“停顿—验证”模型,通过在关键时刻提供上下文相关的核验指引,有效弥补了人类在时间压力下的认知盲区。技术实现上,浏览器扩展形式具备低侵入性与高可部署性,且能与企业现有身份管理、通讯目录系统无缝集成。
未来工作将探索更精细的风险评分机制(如结合用户角色、设备状态、地理位置),并研究如何将干预提示融入操作系统级安全通知,以抵御浏览器沙箱逃逸攻击。最终,安全不应是用户的负担,而应是其高效、安心工作的支撑环境。
编辑:芦笛(公共互联网反网络钓鱼工作组)


















 730
730

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











