







 超级会员免费看
超级会员免费看
 针对高并发系统,文章提出了数据库分层解决方案,包括使用Redis集群处理高频操作,红黑树处理查找数据,以及根据操作类型选择Sqlite或MySQL集群。通过红黑树优化数据库操作,包括创建、装载、操作红黑树并保持与MySQL同步,以提升数据操作效率。
针对高并发系统,文章提出了数据库分层解决方案,包括使用Redis集群处理高频操作,红黑树处理查找数据,以及根据操作类型选择Sqlite或MySQL集群。通过红黑树优化数据库操作,包括创建、装载、操作红黑树并保持与MySQL同步,以提升数据操作效率。
对于高并发系统来说,如果涉及到数据库中数据的增删改查操作,
为了提高并发量,我们要做的第一件事情是对数据进行分层。
下图是一个基本的数据库数据分层实现方案
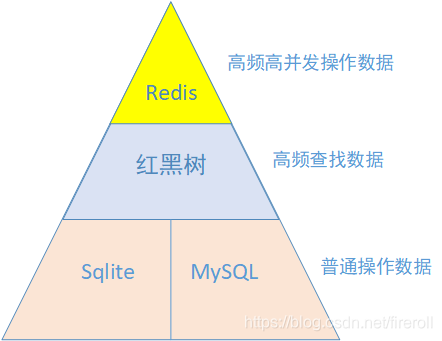
> 对于高频高并发操作数据, 可以使用Redis集群,并应用其Hash模式来存储和操作数据;
> 对于高频的查找数据(较少的修改数据)操作,可以使用红黑树来操作数据;
> 对于普通操作的数据,
如果只涉及到本机的操作数据,可以用Linux自带的轻量级的Sqlite数据库来操作;
如果涉及到多机的数据共享,则可以使用读写分离的MySQL集群来操作。
下面再介绍如何使用红黑树来优化数据库的数据操作。
Step1: 为每个数据库表的数据创建一棵对应的红黑树对象;
Step2: 构建红黑树对应查找,修改等的关键字及比较关系操作,
这里的关键字不是和数据库表的关键字对应,它可以根据业务需要使用多个表中的项来组成;
Step3: 使用构建好的红黑树关键字及比较关系操作,将数据库表中的数据装载进对应的红黑树对象中,
从而完成了红黑树的建立;
Step4: 对于程序本身对MySql的增删改查操作,程序直接将其定向到对红黑树的操作,<

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 192
192

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











