




一、文件打开、关闭

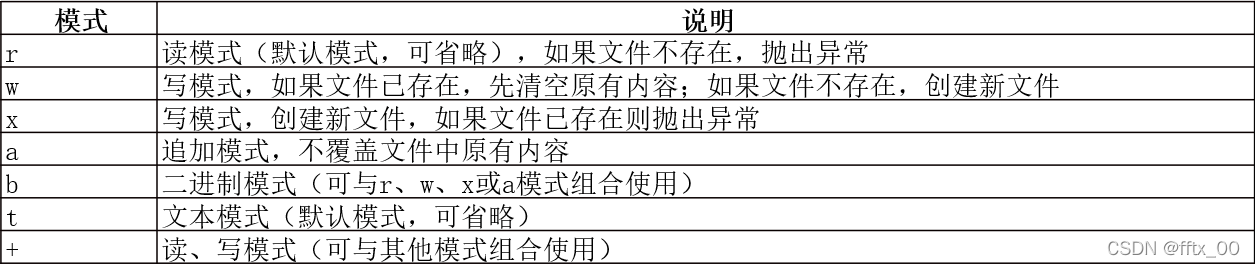
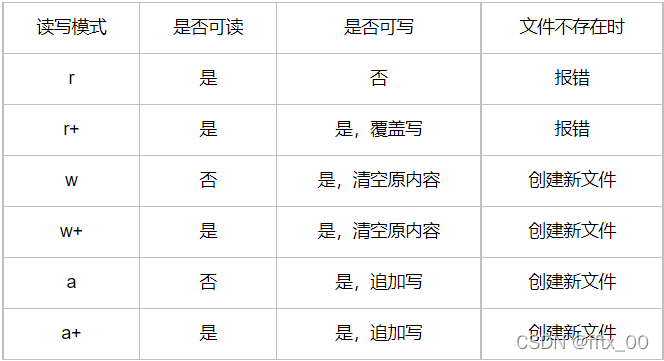
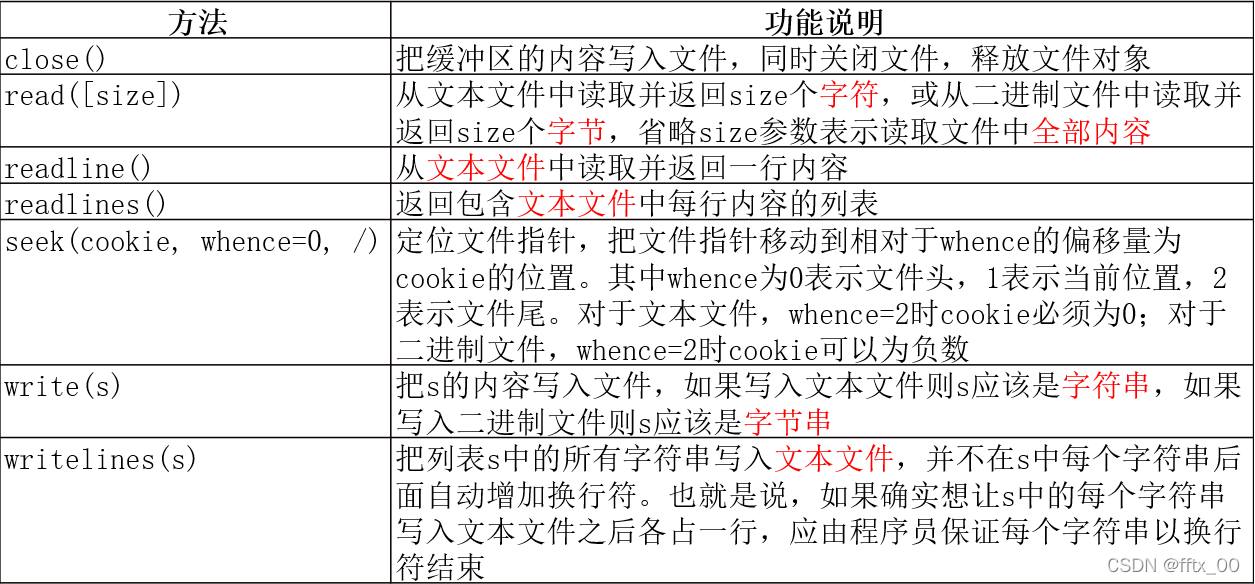
二、with语句自动管理

(不需要自己关)
with open("result.txt","w") as fp: with open("test.txt","r") as fp1, open("test1.txt","r") as fp2: while True: line1 = fp1.readline() if line1: fp.write(line1) else: flag = False break line2 = fp2.readline() if line2: fp.write(line2) else: flag = True break fp3 = fp1 if flag else fp2 for line in fp3: fp.write(line)
(注意短的文件末尾要空一行,不然只用write(),末尾拼接地方会共用一行)

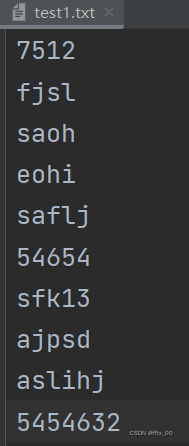
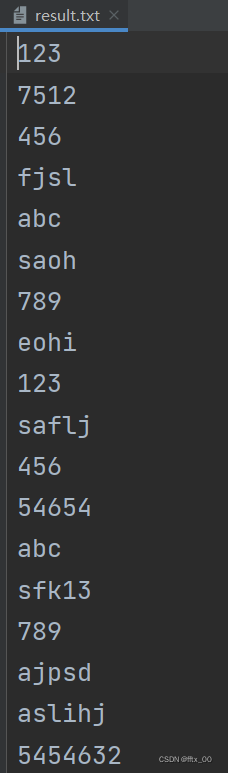
将read出来的字符串转换成真实python类型:
import json with open("student_list.txt", "r", encoding='utf-8') as fp: data1 = fp.readlines() student_list = [eval(each) for each in data1] print(student_list)
三、json文件操作
1.任意类型转字符串 json.dumps(),json.loads()
import json
data1 = json.dumps('3')
print(data1,type(data1))
data1
dict = '{"name": "Tom", "age": 23}' # 将字符串还原为dict,eval
data2 = json.loads(dict)
print(data2, type(data2))
data2
2.文件操作 json.dump(),json.load()
import json
information = [
{'小区名称': '小区A', '均价': 8000, '月交易量': 20},
{'小区名称': '小区B', '均价': 8500, '月交易量': 35},
{'小区名称': '小区C', '均价': 7800, '月交易量': 50},
{'小区名称': '小区D', '均价': 12000, '月交易量': 18}]
with open('房屋信息.json', 'w') as fp:
json.dump(information, fp, indent=4, separators=(',', ':'))
with open('房屋信息.json') as fp:
information = json.load(fp)
for info in information:
print(info)
两种文件load方法:
import json
with open("test2.json", "r", encoding='utf-8') as f:
data2 = json.loads(f.read()) # load的传入参数为字符串类型
print(data2, type(data2))
f.seek(0) # 将文件游标移动到文件开头位置
data3 = json.load(f)
print(data3, type(data3))
三、csv文件操作
1.读一行
import csv
with open("test.csv", "r") as f:
reader1 = csv.reader(f)
rows =[row for row in reader1]
print(rows)
print(len(rows))
print(rows[0].index('工资'))
"""
读表头,推测阅读器是个迭代器
"""
import csv
with open("test.csv") as f:
reader = csv.reader(f)
head_row = next(reader)
print(head_row)
"""
迭代器性质
"""
import csv
with open("test.csv", "r") as fp:
reader = csv.reader(fp)
row1 = [row for row in reader] # 正常读入
row2 = [row for row in reader] # 空
"""
因为还没有关闭文件,先要移动文件光标,再新建迭代器才有效
"""
fp.seek(0)
reader2 = csv.reader(fp)
row3 = [row for row in reader2] # 正常读入
2.读一列
import csv
with open("test.csv") as f:
reader = csv.reader(f)
column = [row[1] for row in reader] # 第1列
print(column)
3.写
import csv
with open("test.csv", "a") as f:
row1 = ['曹操', '23', '学生', '黑龙江', '5000']
writer = csv.writer(f)
writer.writerow(row1)
4.列最大值
""" 获取某列最大值 """ import csv with open("test.csv", "r") as f: reader = csv.reader(f) head_row = next(reader) # 先排除掉表头 column = [row[4] for row in reader if row!=[]] # 末尾有空行,靠if排除 print(column) # list中每个元素都是字符串 print(max(column, key=lambda x: eval(x))) # 要计算需要转成int类型
5.复制csv文件
import csv with open("test1.csv", "w", newline='') as fp: """ 注意消除空行:newline='',不然写入时每行后都会增加一个空行 """ with open("test.csv", "r") as fp1: reader = csv.reader(fp1) data = [row for row in reader] writer = csv.writer(fp) for row in data: writer.writerow(row)
四、json <-> csv
1.csv->json
import csv
import json
"""
1.读csv中的所有行,每行每列与表头组合,转换为字典
"""
with open("test.csv", "r") as fp1:
reader = csv.reader(fp1)
data = [row for row in reader]
print(data)
keys = data[0]
values = data[1:]
res = [dict(zip(keys, value)) for value in values]
print(res)
"""
2.将处理好的数据,写进json文件
"""
with open("test.json", "w") as fp:
json.dump(res, fp, indent=4, separators=(',', ':'))
2.json->csv
import json
import csv
with open("test.json", "r") as fp1:
data = json.load(fp1)
keys = [key for key, value in data[0].items()] # 表头
values = [list(item.values()) for item in data] # 后面每一行
print(keys)
print(values)
res = [keys] + values
"""
注意前一个要再套一个[],不然values会直接嵌在keys后面
"""
with open("test.csv", "w", newline="") as fp:
writer = csv.writer(fp)
for row in res:
writer.writerow(row)
五、excel文件操作
import openpyxl
# 1:打开工作簿
wb = openpyxl.load_workbook("超市营业额1.xlsx")
# 2:选取表单
sh = wb['Sheet1']
# 3:读表头
head_row = list(sh.rows)[0]
print(head_row)
# 4:读后续行
for row in list(sh.rows)[1:]:
case_id = row[0].value
case_name = row[1].value
case_date = row[2].value
wb.close()
六、编码方式




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









