



 本文介绍如何使用Excel的DIY工具箱,通过批量导入和转换功能,快速将源工作簿中以列存储的姓名和年龄数据整理成行格式。步骤包括设置源文件、指定提取范围和目标格式,最终实现数据汇总。
本文介绍如何使用Excel的DIY工具箱,通过批量导入和转换功能,快速将源工作簿中以列存储的姓名和年龄数据整理成行格式。步骤包括设置源文件、指定提取范围和目标格式,最终实现数据汇总。
今天我和大家分享的是,Excel批量将固定格式的源数据提取到一个表中,详见下面的动图演示。我们需要将源数据表中以列形式存放的姓名和年龄统一汇总提取到以行形式的数据表中。
(方方格子插件。)
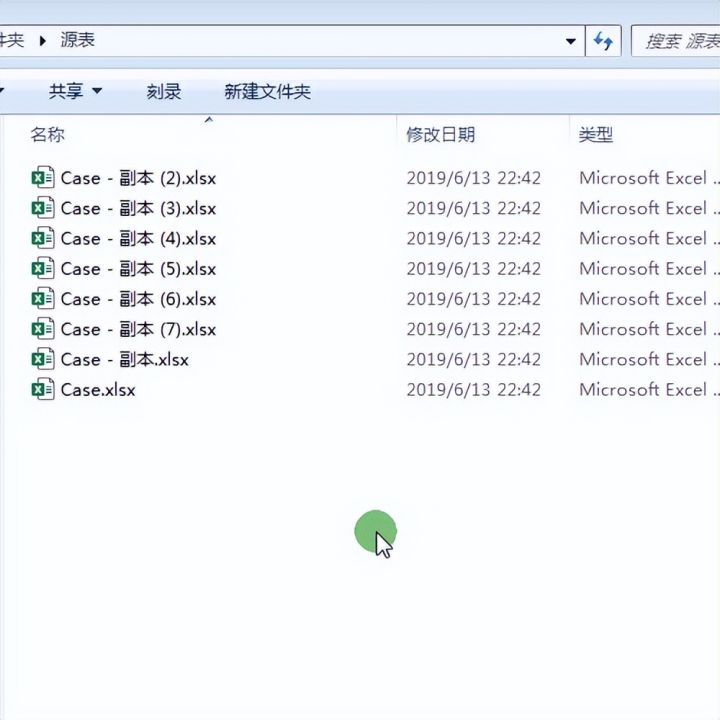
1.首先我们看到共有8个源工作簿。
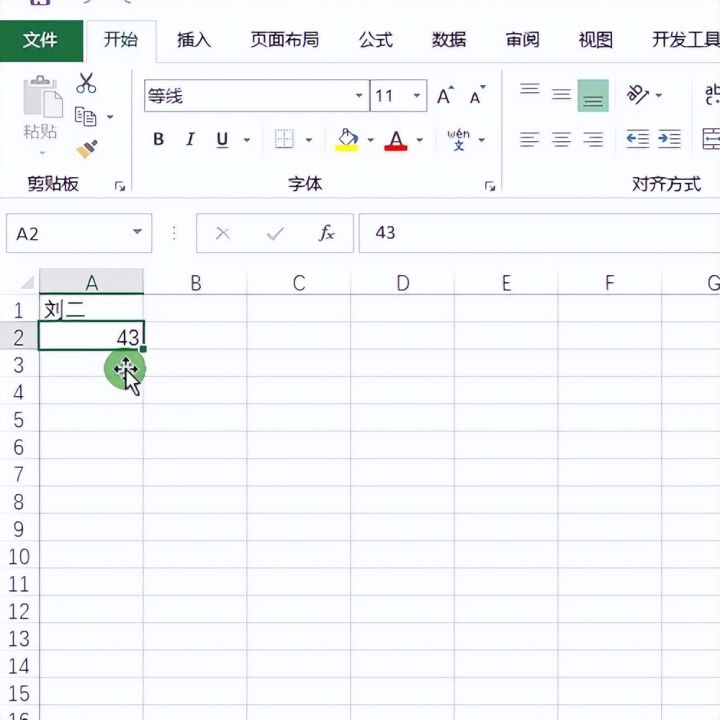
2.然后我们打开每一个工作簿发现A1单元格是姓名A2单元格为年龄
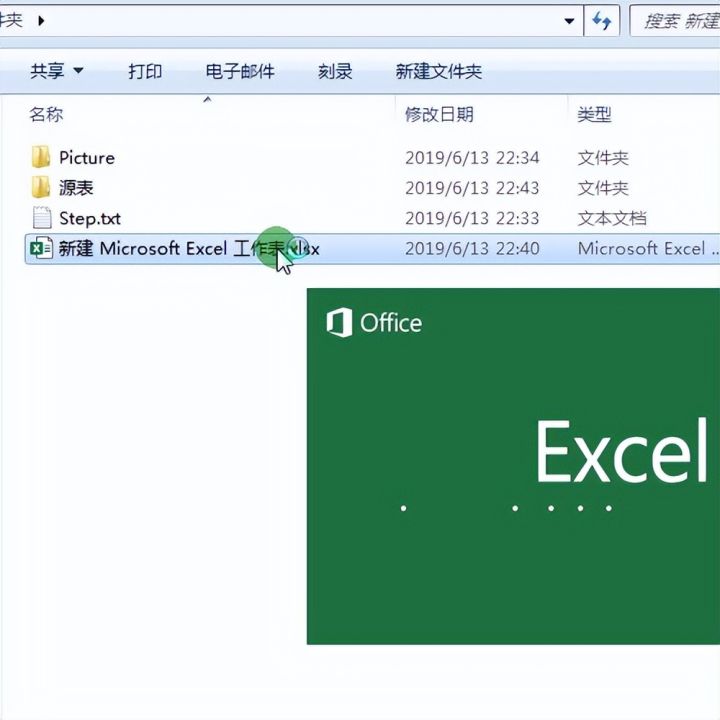
3.然后我们新建一个工作簿。
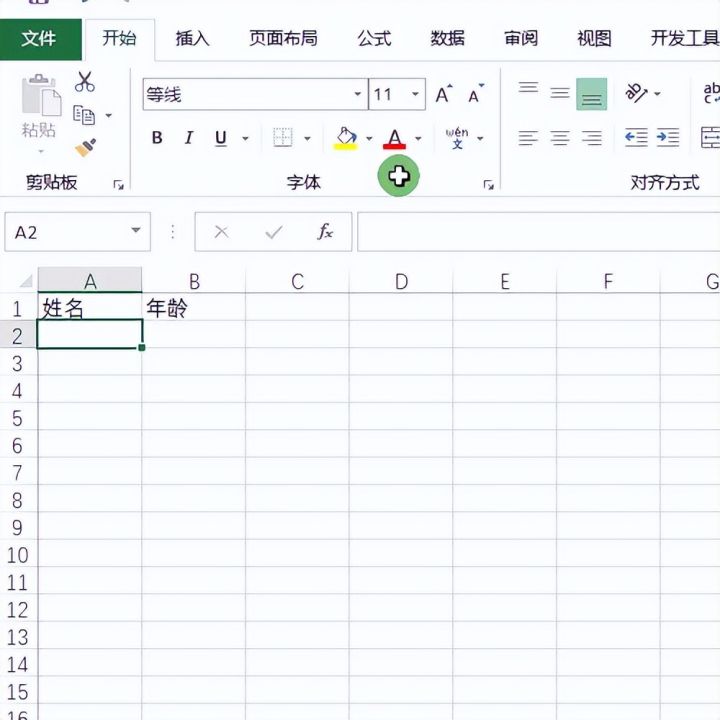
4.选择DIY工具箱。
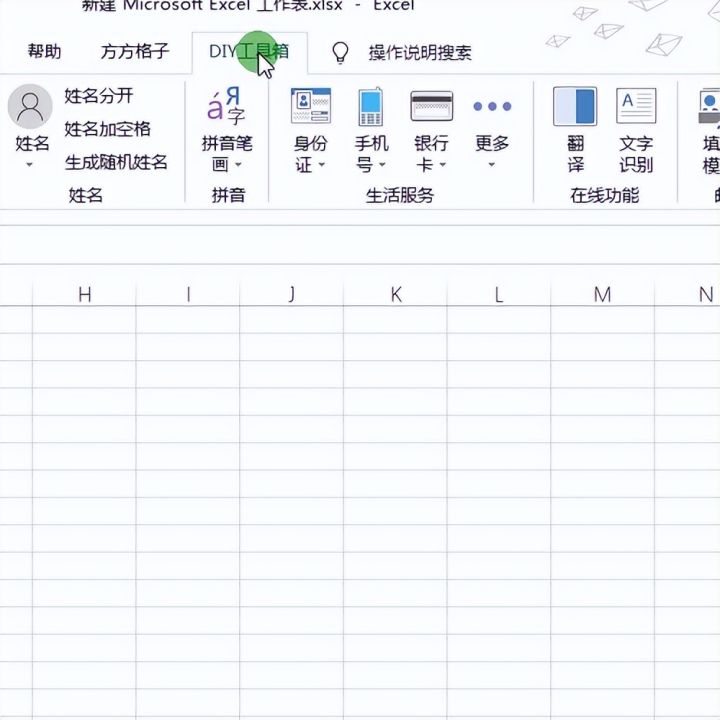
5.选择采集数据选项卡。
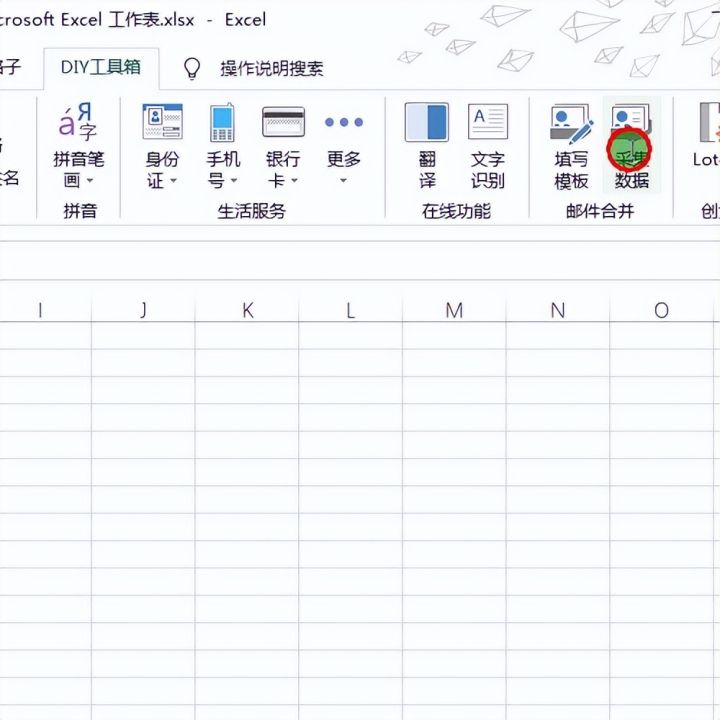
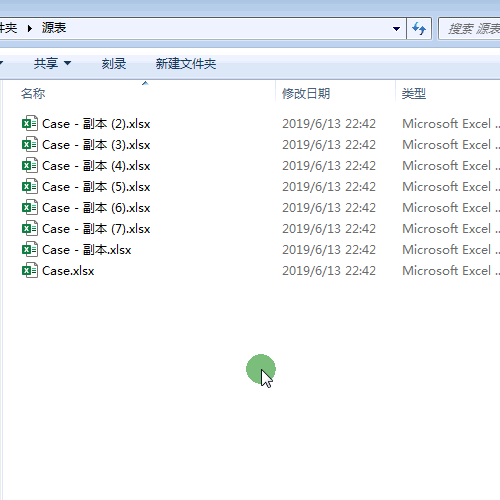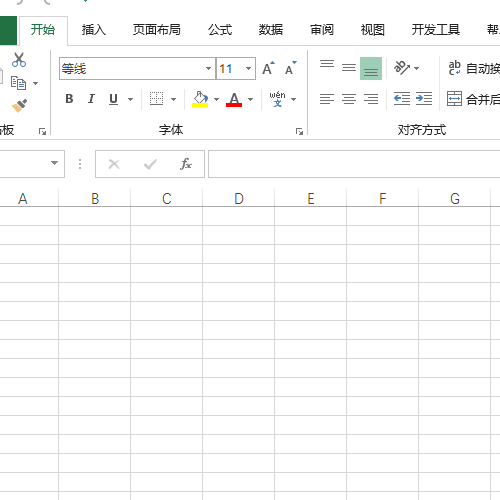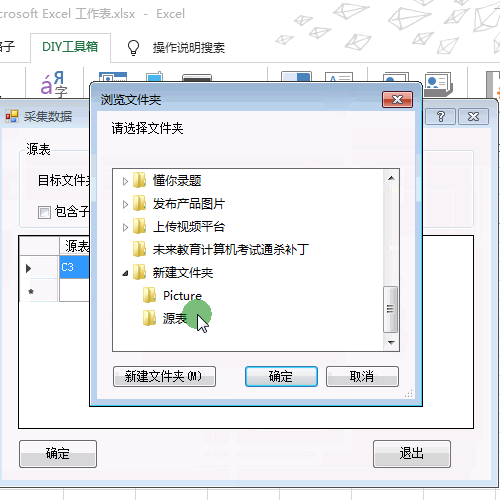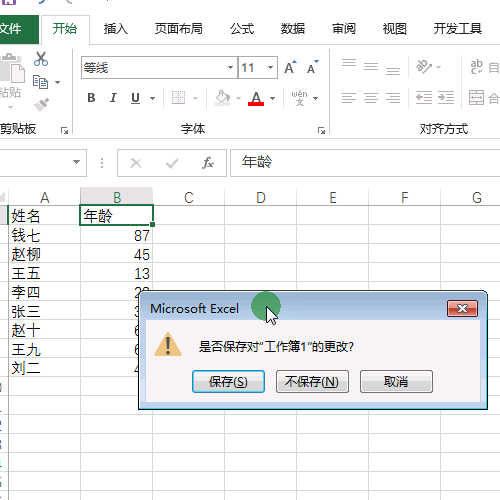
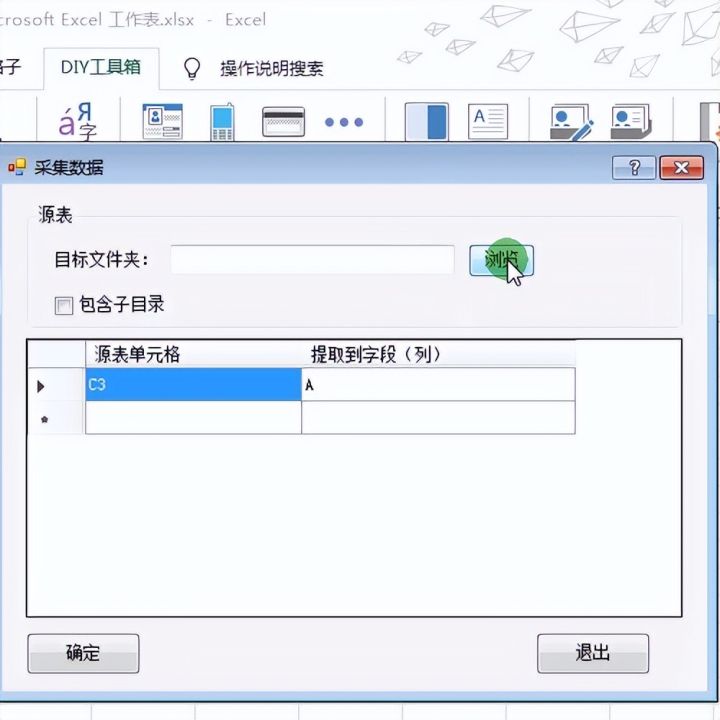
6.弹出对话框浏览源文件。
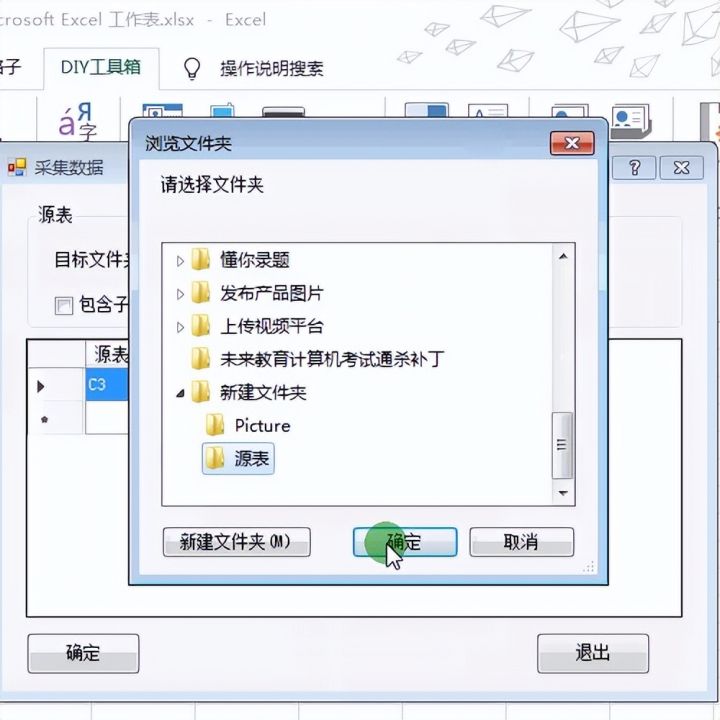
7.找到原来的8个工作簿存放的文件夹。
8.然后设置源表A1单元格的内容提取到A列。源表A2单元格的内容提取到B列。
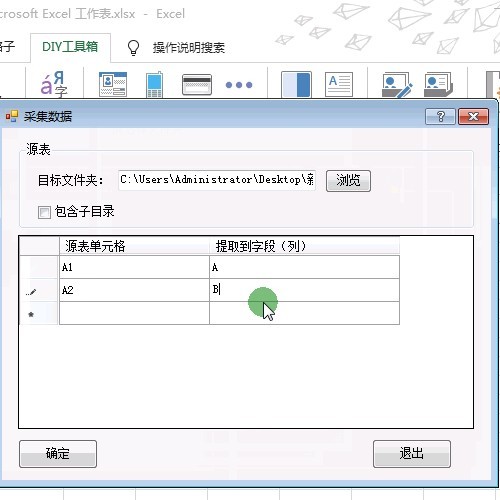
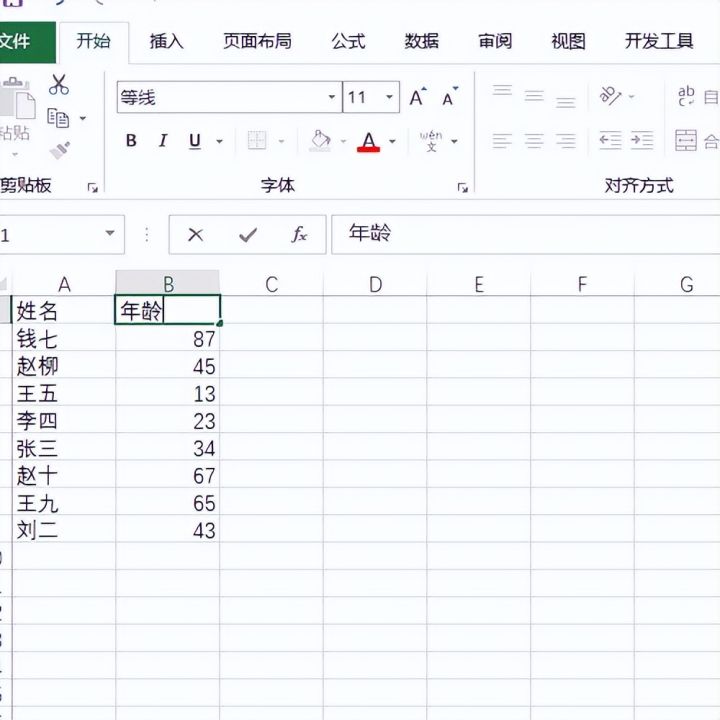
9.单击确定后的我们就会看到结果,会发现姓名和年龄以行的形式统一汇总到一个工作表中。
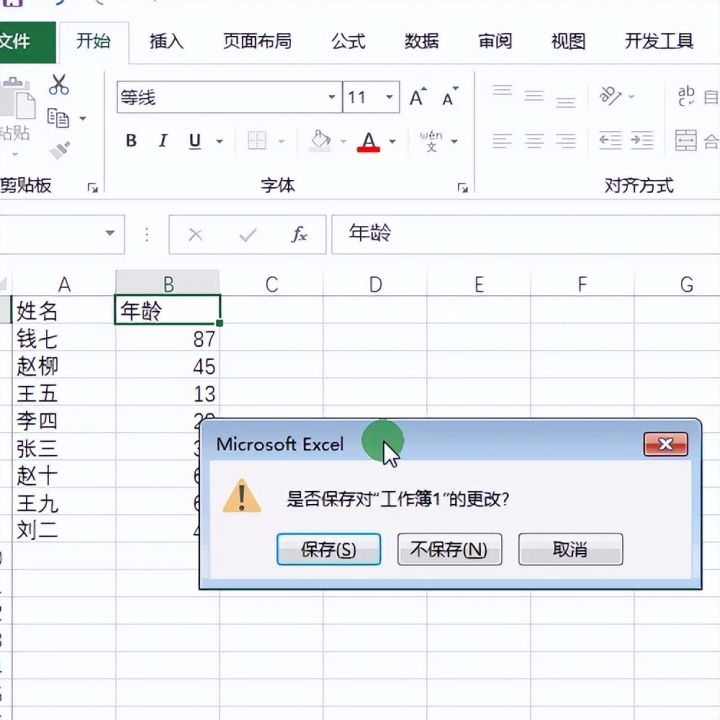
10.最后保存文件即可。
如果该经验帮到了你,请记得分享与点赞。

















 559
559

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









