




 本文介绍使用C语言实现BMP图像的缩放功能,包括直接缩放、最近邻插值法和双线性插值法。通过实验对比不同方法的效果,详细解释了每种方法的实现过程及优缺点。
本文介绍使用C语言实现BMP图像的缩放功能,包括直接缩放、最近邻插值法和双线性插值法。通过实验对比不同方法的效果,详细解释了每种方法的实现过程及优缺点。
对BMP图像用C语言实现图像的缩放。缩放的倍数通过输入设定
#include <Windows.h>
#include <stdlib.h>
#include <stdio.h>
#include <math.h>
int main(int argc, char ** argv)
{
FILE *fp = fopen("./01.bmp","rb");
if (fp == 0)
return 0;
BITMAPFILEHEADER fileHead;
fread(&fileHead, sizeof(BITMAPFILEHEADER), 1, fp);
BITMAPINFOHEADER infoHead;
fread(&infoHead, sizeof(BITMAPINFOHEADER), 1, fp);
int width = infoHead.biWidth;
int height = infoHead.biHeight;
int biCount = infoHead.biBitCount;
RGBQUAD *pColorTable;
int pColorTableSize = 0;
pColorTable = new RGBQUAD[256];
fread(pColorTable, sizeof(RGBQUAD), 256, fp);
pColorTableSize = 1024;
unsigned char *pBmpBuf;
int lineByte = (width*biCount / 8 + 3) / 4 * 4;
pBmpBuf = new unsigned char[lineByte*height];
fread(pBmpBuf, lineByte*height, 1, fp);
fclose(fp);
printf("请输入长和宽需要缩放的倍数:");
float lx, ly;
scanf("%f%f", &lx, &ly);
int dstWidth = round(double(lx*width));
int dstHeight = round(double(ly*height));
int lineByte2 = (dstWidth*biCount / 8 + 3) / 4 * 4;
unsigned char*pBmpBuf2;
pBmpBuf2 = new unsigned char[lineByte2*dstHeight];
for (int i = 0; i < dstHeight; ++i){
for (int j = 0; j < dstWidth; ++j){
unsigned char *p;
p = (unsigned char *)(pBmpBuf2 + lineByte2*i + j);
(*p) = 255;
}
}
int x = 0;
int y = 0;
for (int i = 0; i < height; ++i){
for (int j = 0; j < width; ++j){
unsigned char *p1, *p2;
x = round(double(lx*j));
y = round(double(ly*i));
p1 = (unsigned char *)(pBmpBuf + i*lineByte + j);
p2 = (unsigned char *)(pBmpBuf2 + y*lineByte2 + x);
(*p2) = (*p1);
}
}
FILE *fpo = fopen("./shrinkBmp.bmp", "wb");
if (fpo == 0)
return 0;
BITMAPFILEHEADER dstFileHead;
dstFileHead.bfOffBits = 14 + 40 + pColorTableSize;
dstFileHead.bfReserved1 = 0;
dstFileHead.bfReserved2 = 0;
dstFileHead.bfSize = sizeof(BITMAPFILEHEADER)+sizeof(BITMAPINFOHEADER)+pColorTableSize + lineByte2*dstHeight;
dstFileHead.bfType = 0x4D42;
fwrite(&dstFileHead, sizeof(dstFileHead), 1, fpo);
BITMAPINFOHEADER dstInfoHead;
dstInfoHead.biBitCount = biCount;
dstInfoHead.biClrImportant = 0;
dstInfoHead.biClrUsed = 0;
dstInfoHead.biCompression = 0;
dstInfoHead.biHeight = dstHeight;
dstInfoHead.biPlanes = 1;
dstInfoHead.biSize = 40;
dstInfoHead.biSizeImage = lineByte2*dstHeight;
dstInfoHead.biWidth = dstWidth;
dstInfoHead.biXPelsPerMeter = 0;
dstInfoHead.biYPelsPerMeter = 0;
fwrite(&dstInfoHead, sizeof(BITMAPINFOHEADER), 1, fpo);
fwrite(pColorTable, sizeof(RGBQUAD), 256, fpo);
fwrite(pBmpBuf2, lineByte2*dstHeight, 1, fp);
fclose(fpo);
system("pause");
return 0;
}
实验结果:
原图 宽1.5倍,高0.5倍 宽0.5倍 高1.5倍 宽5倍 高2倍




变换后的图像都有一个共同的特点,就是图像有栅格,出现的原因是在缩放坐标取值时采用简单的取整,解决办法:采用插值解决
方法一:最近邻插值法,其实就是四舍五入
for (int i = 0; i < dstHeight; ++i){
for (int j = 0; j < dstWidth; ++j){
unsigned char *p1, *p2;
x = round(double(1/lx*j));
y = round(double(1/ly*i));
p1 = (unsigned char *)(pBmpBuf2 + i*lineByte2 + j);
p2 = (unsigned char *)(pBmpBuf + y*lineByte + x);
(*p1) = (*p2);
}
}
实验结果:
方法倍数:长1.5 宽1.5

实验结果分析:能过保留细节部分,但边缘存在严重的锯齿现象。
方法二:双线性插值
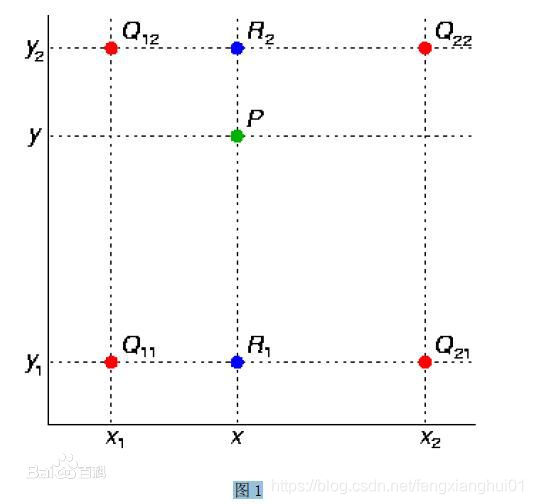
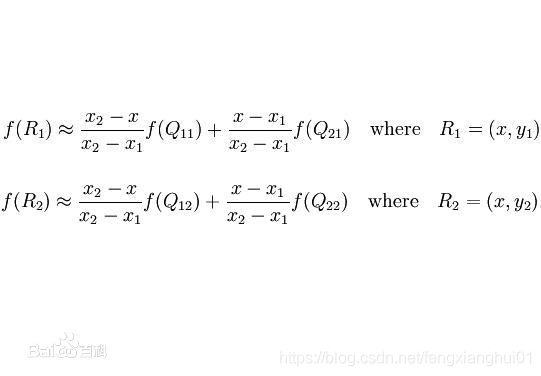
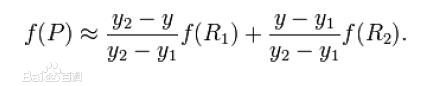
C代码实现:
int x1, x2, y1, y2, Fq11, Fq12, Fq21, Fq22;
double x, y, r1, Fr1, Fr2, Fp;
for (int i = 0; i < dstHeight; ++i){
for (int j = 0; j < dstWidth; ++j){
unsigned char *p1, *p2;
x = 1 / lx*j; // 原图像坐标
y = 1 / ly*i;
// 四个坐标值
x1 = floor(x); x2 = x1 + 1;// 取整ceil向上,floor向下
y1 = floor(y); y2 = y1 + 1;
// 四个坐标对应的灰度值
Fq11 = *(pBmpBuf + y1*lineByte + x1);
Fq12 = *(pBmpBuf + y2*lineByte + x1);
Fq21 = *(pBmpBuf + y1*lineByte + x2);
Fq22 = *(pBmpBuf + y2*lineByte + x2);
// x方向插值和y方向插值
Fr1 = 0; Fr2 = 0;
Fr1 = (x2 - x) / (x2 - x1)*Fq11 + (x - x1) / (x2 - x1)*Fq21;
Fr2 = (x2 - x) / (x2 - x1)*Fq12 + (x - x1) / (x2 - x1)*Fq22;
Fp = (y2 - y) / (y2 - y1)*Fr1 + (y - y1) / (y2 - y1)*Fr2;
// 新图像灰度值赋值
if (Fp >= 0 && Fp <= 255){
p1 = (unsigned char *)(pBmpBuf2 + i*lineByte2 + j); // 新图像
(*p1) = round(Fp);
}
}
}
实验结果:
长宽都放大1.5倍

后续持续更新用C语言实现图像处理算法,敬请期待,欢迎关注。

















 2305
2305

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









