






论文信息
题目:Mamba-YOLO-World: Marrying YOLO-World with Mamba for Open-Vocabulary Detection
Mamba-YOLO-World: 将 YOLO-World 与 Mamba 结合用于开放词汇检测
作者:Haoxuan Wang, Qingdong He, Jinlong Peng, Hao Yang, Mingmin Chi, Yabiao Wang
论文创新点
Mamba-YOLO-World模型:作者提出了一个新颖的基于YOLO的开放词汇检测(OVD)模型,名为Mamba-YOLO-World。该模型采用了作者提出的**MambaFusion Path Aggregation Network (MambaFusion-PAN)**作为其颈部架构,这是对传统YOLO系列在OVD领域应用的一个重要扩展。
基于状态空间模型的特征融合机制:作者引入了一个创新的基于状态空间模型的特征融合机制,包括并行引导选择性扫描算法和串行引导选择性扫描算法。这一机制具有线性复杂度和全局引导的接受域,能够有效地利用多模态输入序列和mamba隐藏状态来指导选择性扫描过程,从而提高了模型在开放词汇检测任务中的表现。
摘要
开放词汇检测(OVD)旨在检测超出预定义类别集的对象。作为将 YOLO 系列纳入 OVD 的先驱模型,YOLO-World 非常适合优先考虑速度和效率的场景。然而,其性能受到其颈部特征融合机制的限制,这导致了二次复杂度和有限的引导接受域。为了解决这些限制,我们提出了 Mamba-YOLO-World,这是一个新颖的基于 YOLO 的 OVD 模型,采用了我们提出的 MambaFusion Path Aggregation Network(MambaFusion-PAN)作为其颈部架构。具体来说,我们引入了一个创新的基于状态空间模型的特征融合机制,包括一个并行引导选择性扫描算法和一个串行引导选择性扫描算法,具有线性复杂度和全局引导的接受域。它利用多模态输入序列和 mamba 隐藏状态来指导选择性扫描过程。实验表明,我们的模型在 COCO 和 LVIS 基准测试中的零样本和微调设置下均优于原始的 YOLO-World,同时保持了可比的参数和 FLOPs。此外,它以更少的参数和 FLOPs 超越了现有的最先进的 OVD 方法。关键词—目标检测,开放词汇,Mamba
关键词
目标检测、开放词汇、Mamba

方法
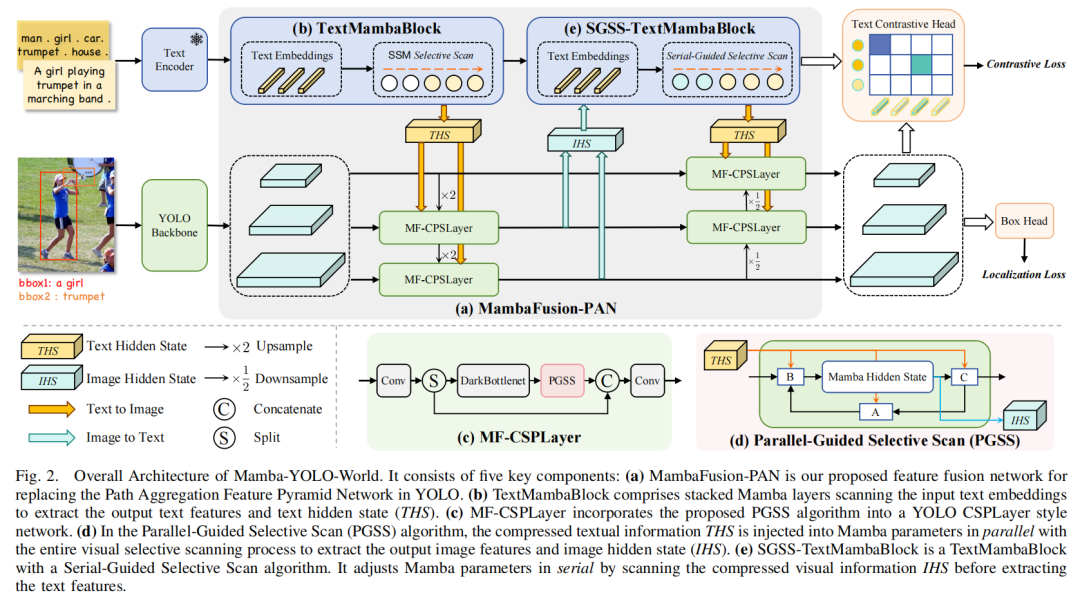
Mamba-YOLO-World 主要基于 YOLOv8[30] 开发,包括一个 Darknet 背骨[3]和一个 CLIP[31] 文本编码器作为模型的背骨,我们的 MambaFusion-PAN 作为模型的颈部,以及一个文本对比分类头和一个边界框回归头作为模型的头部,如图 2 所示。
Mamba 预备知识
对于连续输入信号 ,SSM[32] 将其映射到连续输出信号 通过一个隐藏状态 。 (1) (2) 其中 E 是 SSM 状态扩展因子, 是状态转移矩阵, 和 分别是输入和输出映射矩阵。在 SSM 的基础上,Mamba[21] 引入了选择性扫描算法,使 A、B 和 C 成为输入序列的函数。
MambaFusion-PAN
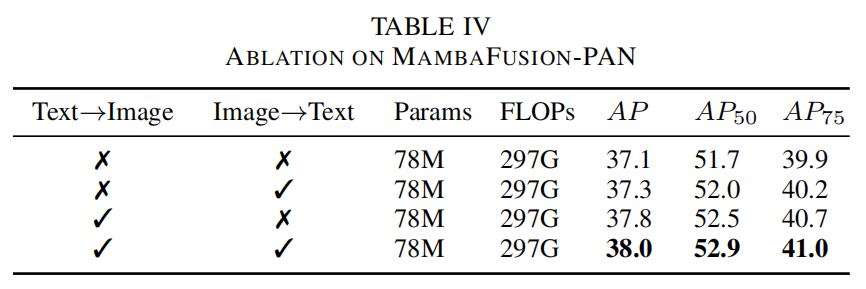
MambaFusion-PAN 是作者提出的用于替换 YOLO 中路径聚合特征金字塔网络的特征融合网络。如图 2(a) 所示,MambaFusion-PAN 利用作者提出的基于 SSM 的并行和串行特征融合机制来聚合多尺度图像特征,并通过视觉和语言分支之间的三阶段特征融合流程同时增强文本特征:文本到图像、图像到文本,最后是文本到图像。具体组件在本节的以下部分详细说明。
Mamba 隐藏状态
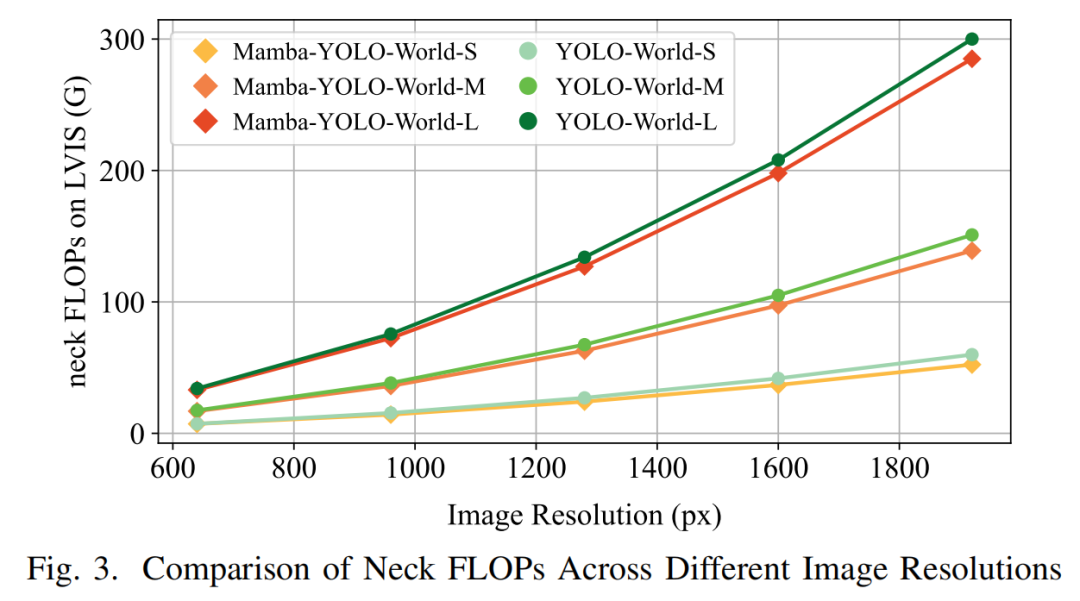
目前,基于 Transformer 和基于 Mamba 的 VLMs 简单地串联多模态特征[18]、[19]、[27]-[29]、[33]、[34],导致随着文本序列长度和图像分辨率的增长,复杂度不可避免地增加。尽管 YOLO-World 中的 VL-PAN 采用了单向融合而没有特征串联,但它仍然导致了 O(N^2) 复杂度。这是由于文本到图像融合流程中的视觉通道注意力机制和图像到文本融合流程中的多头交叉注意力机制。为了解决这些问题,我们提出通过 mamba 隐藏状态 作为不同模态之间特征融合的中介,其中 D 是输入序列的维度,E 是 SSM 状态扩展因子[21]、[26]。由于 D 和 E 都是常数且不受序列长度的影响,我们的特征融合机制的复杂度为 O(N + 1),其中 N 来自一个模态的输入序列,1 来自另一个模态的 mamba 隐藏状态。
TextMambaBlock
TextMambaBlock 由堆叠的 Mamba 层组成。给定从 CLIP 文本编码器输出的文本嵌入 ,我们采用图 2(b) 中描述的 TextMambaBlock 不仅提取输出文本特征 ,还提取文本隐藏状态 THS ,这将用于后续的文本到图像特征融合。
MF-CSPLayer
如图 2(c) 所示,我们通过 MambaFusion CSPLayer(MF-CSPLayer)将 THS 与多尺度图像特征集成在一起。MF-CSPLayer 将提出的并行引导选择性扫描算法并入 YOLO CSPLayer 风格的网络中。通过 MFCSPLayer 处理后我们不仅可以获得输出图像特征,还可以获得图像隐藏状态 IHS ,这将用于后续的图像到文本特征融合。
并行引导选择性扫描
Mamba 选择性扫描算法根据输入序列动态调整内部参数。受此启发,我们创新性地提出了并行引导选择性扫描(PGSS)算法,它根据输入图像序列和 THS 在扫描过程中动态调整 Mamba 内部参数(A、B 和 C),如图 2(d) 和算法 1 所示。因此,压缩的文本信息与整个视觉选择性扫描过程并行注入 Mamba,使得多尺度图像特征在像素级而不是通道级得到引导。由此产生的输出被传递到 MF-CSPLayer 的后续层。以下,我们将这部分称为文本到图像特征融合流程。

串行引导选择性扫描
Mamba 选择性扫描算法根据输入序列持续将信息压缩到 h(t) 中。受此启发,我们提出了串行引导选择性扫描(SGSS)算法,并将其整合到 TextMambaBlock 中,如图 2(e) 所示。SGSS 的目标是将先前序列的先验知识压缩到 h(t) 中,并将其作为后续序列的引导。具体来说,SGSS-TextMambaBlock 通过扫描压缩的视觉信息 IHS 来串行调整 Mamba 内部参数(A、B 和 C),然后提取文本特征。以下,我们将这部分称为图像到文本特征融合流程。
实验
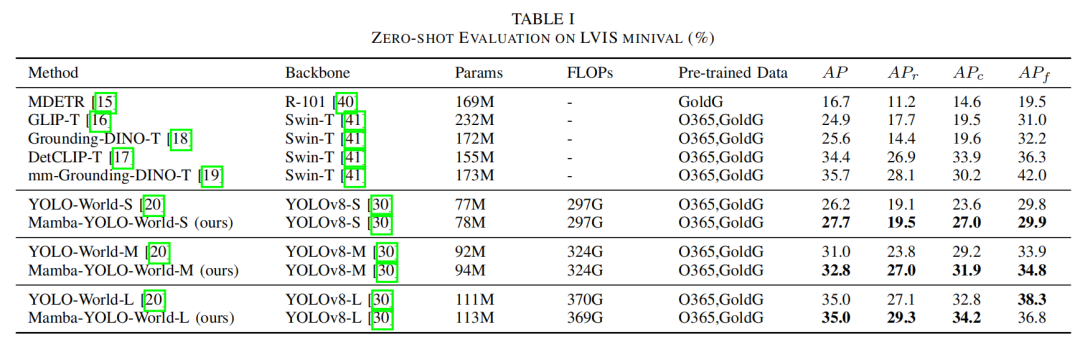
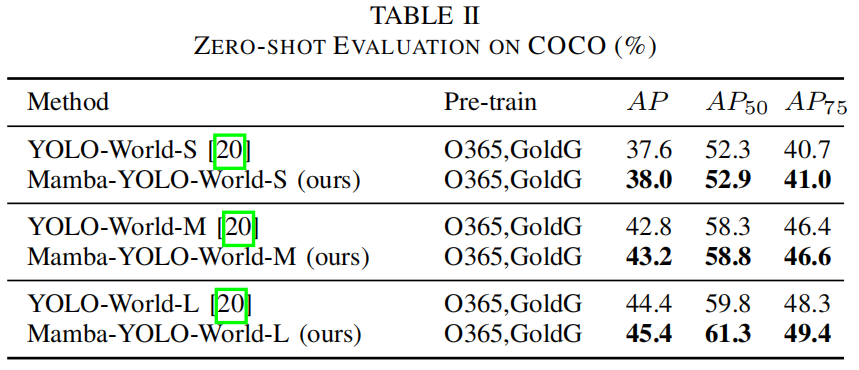
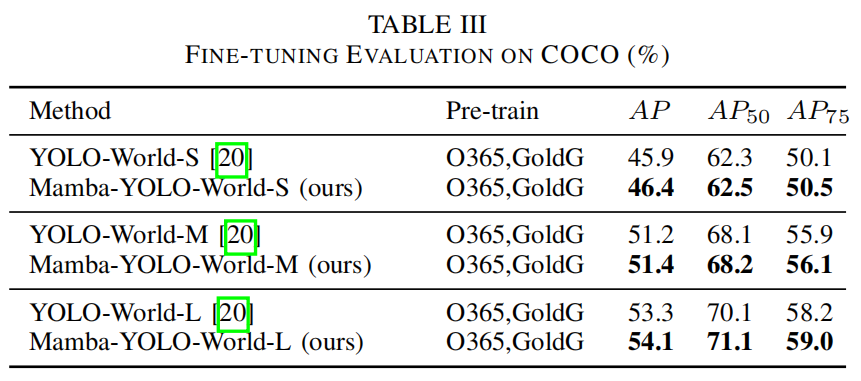
声明
本文内容为论文学习收获分享,受限于知识能力,本文对原文的理解可能存在偏差,最终内容以原论文为准。本文信息旨在传播和学术交流,其内容由作者负责,不代表本号观点。文中作品文字、图片等如涉及内容、版权和其他问题,请及时与我们联系,我们将在第一时间回复并处理。

往期精彩回顾
适合初学者入门人工智能的路线及资料下载(图文+视频)机器学习入门系列下载机器学习及深度学习笔记等资料打印《统计学习方法》的代码复现专辑交流群
请备注:”昵称-学校/公司-研究方向“,例如:”张小明-浙大-CV“加群。
(也可以加入机器学习交流qq群772479961)


















 855
855

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









