






介绍
Null Importances是竞赛中比较靠谱的特征筛选方法,且在多个Kaggle结构化比赛中被验证过。
特征筛选从原始特征空间筛选部分特征,具体筛选方法可以分为:
过滤法;
包装法;
嵌入法;
过滤法思路使用相关统计值来计算特征有效性,然后完成筛选;包装法使用特征带来的精度增益来衡量;嵌入法使用特征在模型内部权重来衡量重要性。
在竞赛中一般使用包装法来筛选特征,但单纯追求精度收益非常容易过拟合,导致线上和线下不一致。
原理
使用包装法和嵌入法筛选特征,容易筛选得到有较高CV(验证集)精度,但导致分布一致的特征。
CV精度增加,线上不一定有提高;
树模型重要性高,不一定有效的;
举一个例子:样本标签和ID两列,两列是一一对应,如果将ID列加入训练,CV精度可能不会增加,但ID在树模型特征重要性会很高。
Null Importances的出发点也是如此,特征重要性只反映特征的信息增益或使用次数,但并不能说明特征一定有效。
步骤
Null Importances思路如下:
步骤1:将原有特征和标签使用树模型训练,得到每个特征原始重要性A;
步骤2:将数据的标签打乱,特征不变再此训练,记录下打散后的每个特征重要性B,将此步骤重复N次;
步骤3:将步骤1中特征步骤2两个特征重要性进行比较。
若
A远大于B,则特征为有效特征;若
A小于等于B,则特征为无效特征;
步骤2重复N是为了看标签打散后的特征重要性分布,A与B的分布比较,会更加清晰。
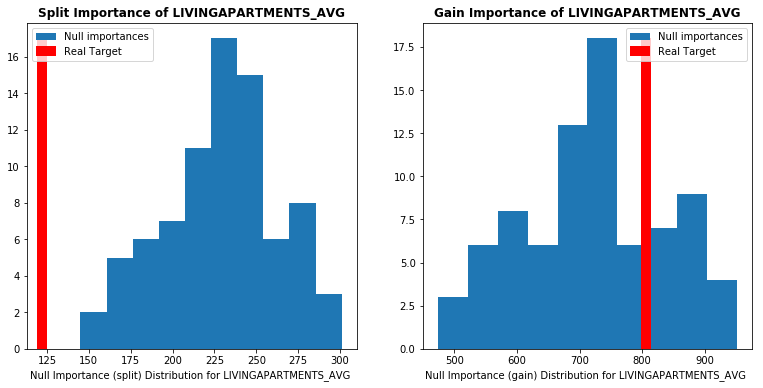
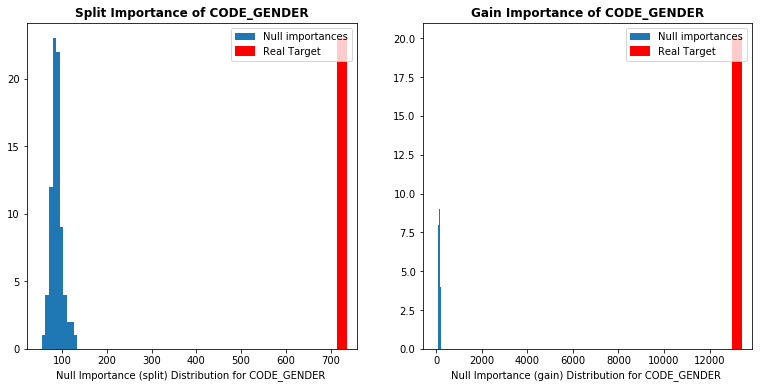
Null Importances是借助了嵌入法的重要性计算过程,然后使用重要性变化来完成衡量过程。如下图所示,使用LightGBM模型来完成上述操作。红色为原始重要性A,蓝色为打乱后的重要性。
每一行对应一个特征,左边特征使用次数,右边为特征信息增益。
参考资料
https://academic.oup.com/bioinformatics/article/26/10/1340/193348
https://www.kaggle.com/ogrellier/feature-selection-with-null-importances

往期精彩回顾
适合初学者入门人工智能的路线及资料下载(图文+视频)机器学习入门系列下载机器学习及深度学习笔记等资料打印《统计学习方法》的代码复现专辑机器学习交流qq群955171419,加入微信群请扫码
















 6111
6111

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









