




 本文深入探讨Flink的状态原理,包括状态、状态后端与Checkpoint的关系,强调RocksDB在处理大状态场景的优势。同时,阐述了operator-state与keyed-state的区别,以及它们在并行度变化时的恢复策略。此外,文章还介绍了ValueState与MapState的应用场景,并讲解了Flink中StateTTL的配置选项。最后,水印的概念被提出,不仅解决时间窗口乱序问题,更是推动事件时间窗口触发的关键。
本文深入探讨Flink的状态原理,包括状态、状态后端与Checkpoint的关系,强调RocksDB在处理大状态场景的优势。同时,阐述了operator-state与keyed-state的区别,以及它们在并行度变化时的恢复策略。此外,文章还介绍了ValueState与MapState的应用场景,并讲解了Flink中StateTTL的配置选项。最后,水印的概念被提出,不仅解决时间窗口乱序问题,更是推动事件时间窗口触发的关键。
6 大主题,36 个 Flink 高频面试题:
- ⭐ 状态原理
- ⭐ 时间窗口
- ⭐ 编程技巧
- ⭐ 实战经验
- ⭐ 实时数仓
- ⭐ 前沿探索
1.状态原理
1.1.状态、状态后端、Checkpoint 三者之间的区别及关系?
- 状态:本质来说就是数据,在 Flink 中,其实就是 Flink 提供给用户的状态编程接口。比如 flink 中的 MapState,ValueState,ListState。
- 状态后端:Flink 提供的用于管理状态的组件,状态后端决定了以什么样数据结构,什么样的存储方式去存储和管理我们的状态。Flink 目前官方提供了 memory、filesystem,rocksdb 三种状态后端来存储我们的状态。
- Checkpoint(状态管理):Flink 提供的用于定时将状态后端中存储的状态同步到远程的存储系统的组件或者能力。为了防止 long run 的 Flink 任务挂了导致状态丢失,产生数据质量问题,Flink 提供了状态管理(Checkpoint,Savepoint)的能力把我们使用的状态给管理起来,定时的保存到远程。然后可以在 Flink 任务 failover 时,从远程把状态数据恢复到 Flink 任务中,保障数据质量。
1.2 把状态后端从 FileSystem 变为 RocksDB 后,Flink 任务状态存储会发生那些变化?
结论:是否使用 RocksDB 只会影响 Flink 任务中 keyed-state 存储的方式和地方,Flink 任务中的 operator-state 不会受到影响。
首先我们来看看,Flink 中的状态只会分为两类:
- keyed-state:键值状态,如其名字,此类状态是以 k-v 的形式存储,状态值和 key 绑定。Flink 中的 keyby 之后紧跟的算子的 state 就是键值状态;
- operator-state:算子状态,非 keyed-state 的 state 都是算子状态,非 k-v 结构,状态值和算子绑定,不和 key 绑定。Flink 中的 kafka source 算子中用于存储 kafka offset 的 state 就是算子状态。
如下图所示是 3 种状态后端和 2 种 State 的对应存储关系:
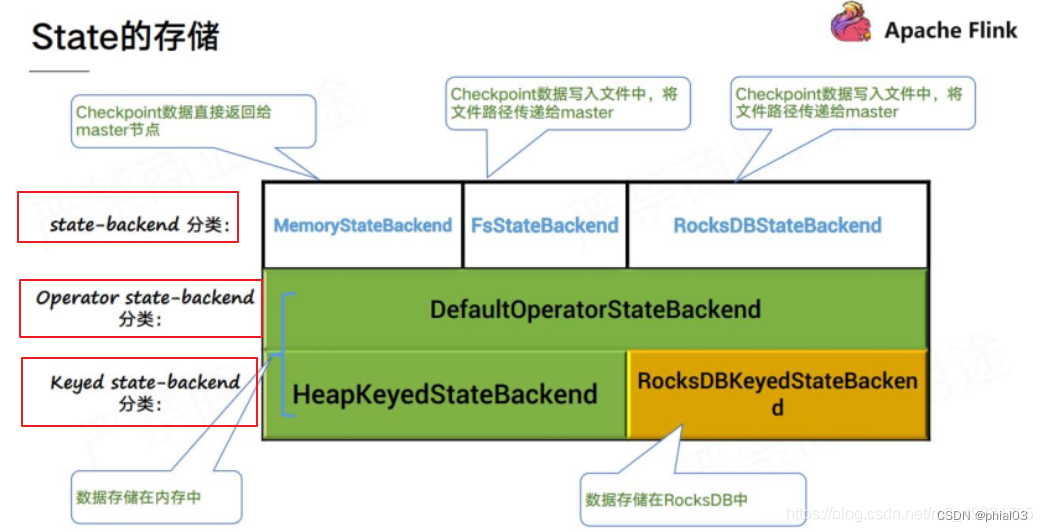
- 横向(行)来看,即 Flink 的状态分类。分为 Operator state-backend、Keyed state-backend;
- 纵向(列)来看,即 Flink 的状态后端分类。用户可以
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











