




 本文深入探讨了Flink的Checkpoint机制,包括执行流程、常见问题及解决方案。针对数据流动缓慢和状态数据过大的挑战,提出了非对齐Checkpoint(FLIP-76)和动态调整Buffer大小(FLIP-183)的优化策略,旨在减少Checkpoint时间并提高系统性能。此外,还介绍了通用增量快照(FLIP-158)以解决全量与增量Checkpoint的不稳定问题,通过状态变更日志实现快速稳定的Checkpoint过程。
本文深入探讨了Flink的Checkpoint机制,包括执行流程、常见问题及解决方案。针对数据流动缓慢和状态数据过大的挑战,提出了非对齐Checkpoint(FLIP-76)和动态调整Buffer大小(FLIP-183)的优化策略,旨在减少Checkpoint时间并提高系统性能。此外,还介绍了通用增量快照(FLIP-158)以解决全量与增量Checkpoint的不稳定问题,通过状态变更日志实现快速稳定的Checkpoint过程。
Flink Checkpoint主要从以下几方面进行介绍:
- Checkpoint 执行流程
- checkpoint 执行失败问题分析
- 非对齐checkpoint 优化方案
- 动态调整 buffer 大小
- 通用增量快照
1. checkpoint 执行流程
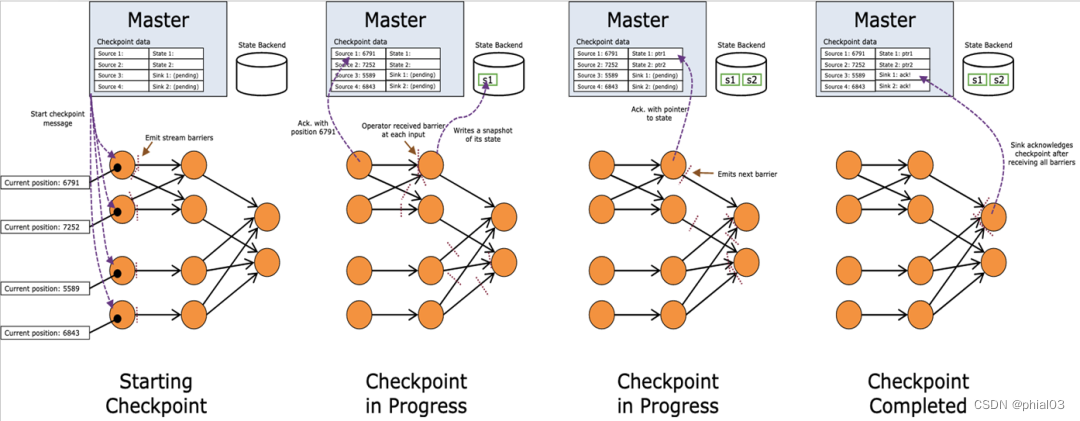
如上图所示,chechpoint 在执行过程中,可以简化为可以简化为以下四大步:

- 在数据流中插入 checkpoint barrier;
- 每执行到当前算子时,对算子 state 状态进行同步快照与异步上传;
- 当算子是多输入时,要进行 barrier 对其操作;
- 所有算子状态都已上传,确认 checkpoint 完成;
2. checkpoint 执行失败问题分析
Flink 机制是基于 Chandy-Lamport 算法实现的 checkpoint 机制,在正常情况下,能够实现对正常处理流程非常小的影响,来完成状态的备份。但仍存在一些异常情况,可能造成checkpoint 代价较大。
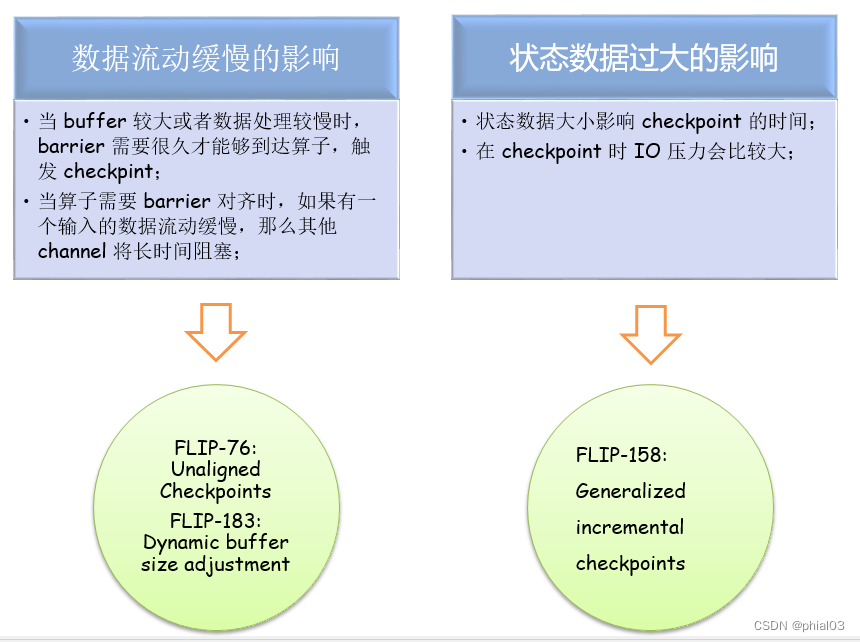
- 问题1:数据流动缓慢
我们知道 Flink 的 checkpoint 机制是基于 barrier 的,在数据处理过程中,barrier 也需要像普通数据一样,在 buffer 中排队,等待被处理。当 buffer 较大或者数据处理较慢时,barrier 需要很久才能够到达算子,触发 checkpint。尤其是当应用触发反压时,barrier 可能要在 buffer 中流动数个小时,这显然是不合适的。而另外一种情况则更为严重,当算子需要 barrier 对齐时,如果一个输入的 barrier 已经到达,那么该输入 barrier 后面的数据会阻塞住,不能被处理的,需要等待其他输入 barrier 到达之后,才能继续处理。如果有一个输入的数据流动缓慢,那么等待 barrier 对齐的过程中,其他输入的数据处理都要暂停,这将严重影响应用的实时性。
针对数据流动缓慢的问题,解决思路有两个:
一、让 buffer 中的数据变少;
二、让 barrier 能跳过 buffer 中缓存的数据;
上述的解决办法正是 Flink 社区提出的两个优化方案,分别为FLIP-76: Unaligned Checkpoints,FLIP-183: Dynam
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1348
1348




 到【灌水乐园】发言
到【灌水乐园】发言









