







 本文介绍Python爬虫的基础知识,涵盖requests库的使用方法,包括发送GET和POST请求,以及如何利用beautifulSoup库解析网页数据,提取所需信息。文章详细解释了find_all和find方法的区别,并提供了实际操作示例。
本文介绍Python爬虫的基础知识,涵盖requests库的使用方法,包括发送GET和POST请求,以及如何利用beautifulSoup库解析网页数据,提取所需信息。文章详细解释了find_all和find方法的区别,并提供了实际操作示例。
前言
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理。
PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行获取
三大库:requests,lxml,beautifulSoup.
Request库作用:请求网站获取网页数据。
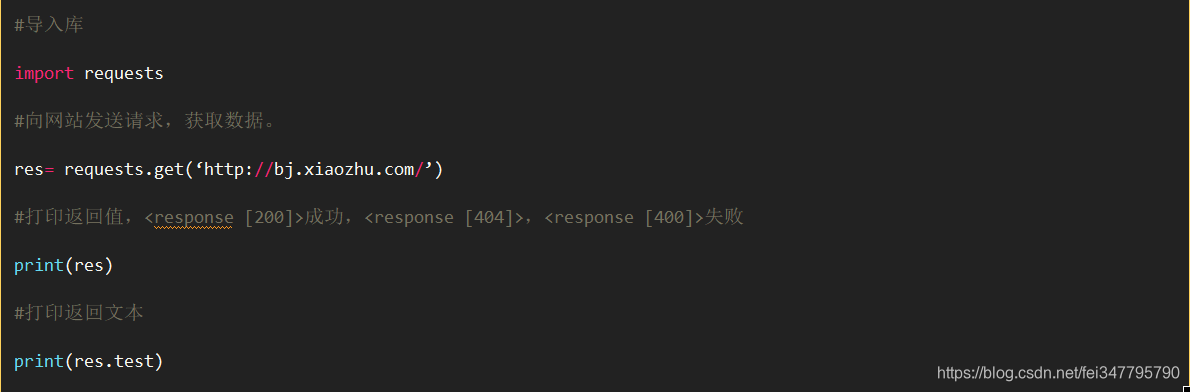
get()的基本使用方法
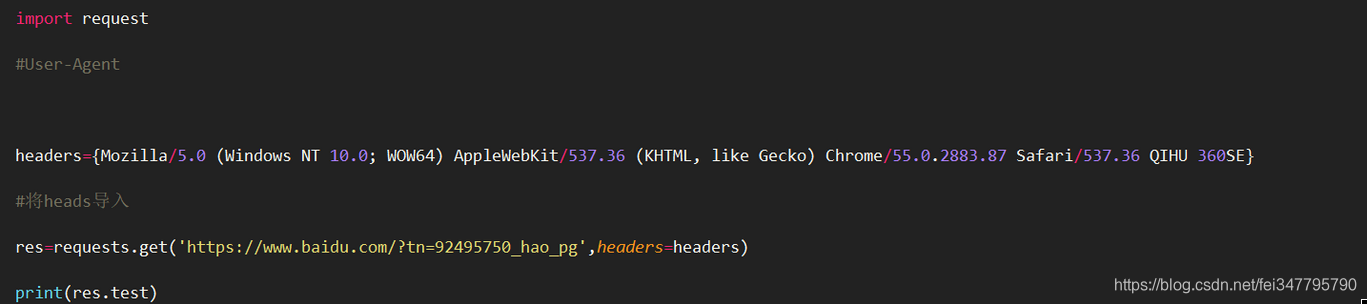
加入请求头伪装成浏览器
post()的基本使用:用于提交表单来爬取需要登录才能获得数据的网页。
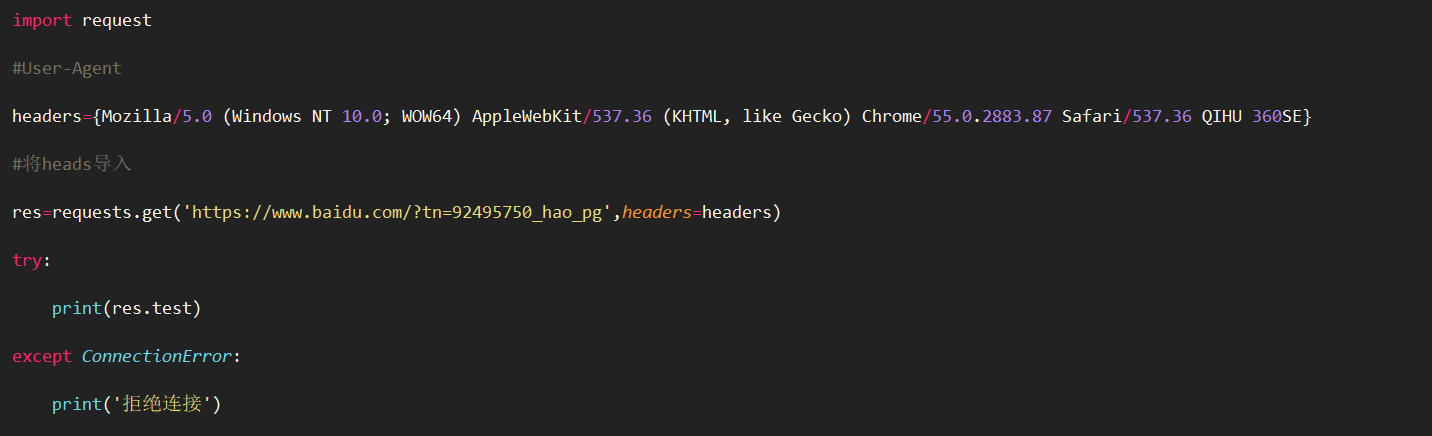
增加健壮性和效率
Requests库的错误和异常分四种:自己分为两种①未发出Reques②未收到Html
当发现这些错误或异常进行代码修改重新再来,爬虫重新再来,有些数据又爬一次。效率和质量低。
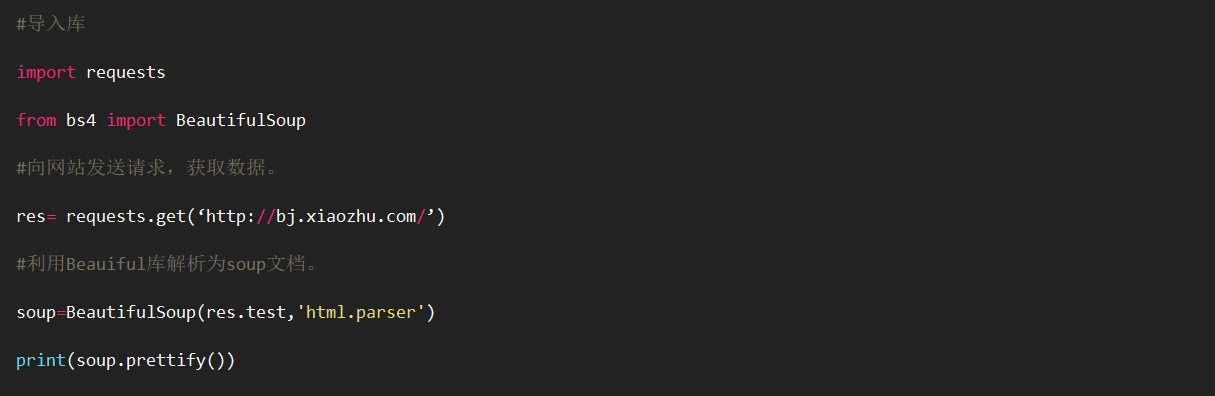
beautifulSoup()库的作用:①解析requests库请求的网页,把网页源代码解析成soup文档。②初步提取
①解析requests库请求的网页,把网页源代码解析成soup文档,得到标准缩进格式的结构输出,为进步处理准备。
②初步提取
find_all和find()的区别:查询一个或查询所有。使用方法一样,没有具体事例可能用的不多。
根据标签名提取内容
soup.find_all('div',"item")
soup.find_all('div',class='item')
soup.find_all('div',attrs={"class":"item"})
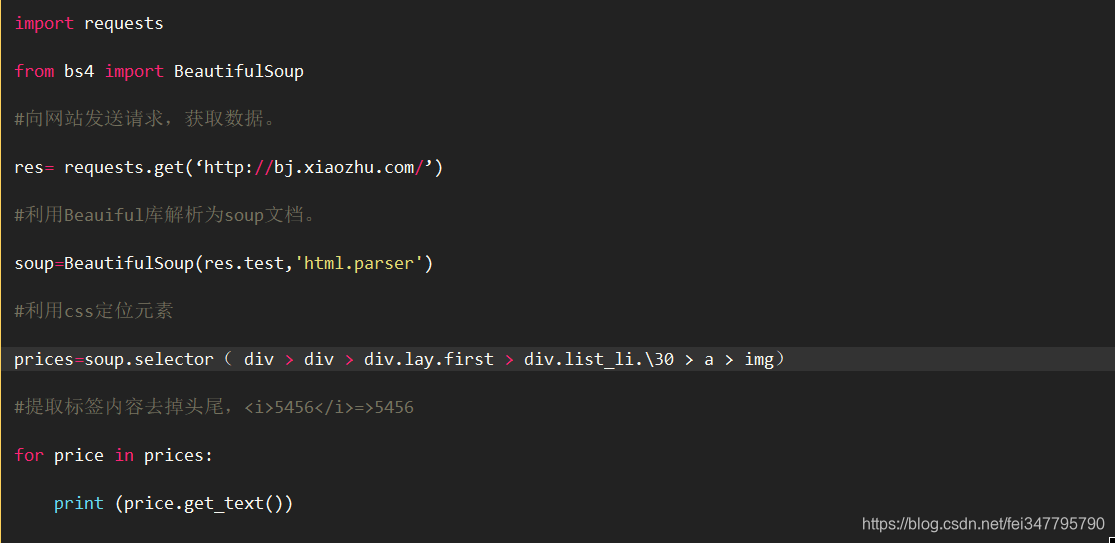
selector():根据路径查询数据
soup.selector( div > div > div.lay.first > div.list_li.\30 > a > img)
div是标签名,list_li.\30是属性class的值
多分支标签中不能使用child要改为type
li:nth-child(1)需改为li:nth-of-type(1)
③get_text()方法:提取标签内容去掉头尾,5456 => 5456

















 6652
6652

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









