




 本文介绍了Python爬虫的三大基础库——Requests、Lxml和BeautifulSoup。通过实例展示了如何使用Requests库发送HTTP请求,获取网页源代码,并利用BeautifulSoup解析网页内容。文中详细解释了如何设置User-Agent,以及如何将爬取的数据保存到本地HTML文件。通过运行示例代码,读者可以完成自己的第一个爬虫程序,抓取并保存百度首页的源代码。
本文介绍了Python爬虫的三大基础库——Requests、Lxml和BeautifulSoup。通过实例展示了如何使用Requests库发送HTTP请求,获取网页源代码,并利用BeautifulSoup解析网页内容。文中详细解释了如何设置User-Agent,以及如何将爬取的数据保存到本地HTML文件。通过运行示例代码,读者可以完成自己的第一个爬虫程序,抓取并保存百度首页的源代码。
一、爬虫三大库简单介绍 (后面会一个一个详细介绍使用方法)
import requests 这个就是导入 requests库
需要安装第三方库 就使用这个命令 pip install 第三方库的名称
比如 安装requests库 就是 pip install requests
需要打开cmd
比如: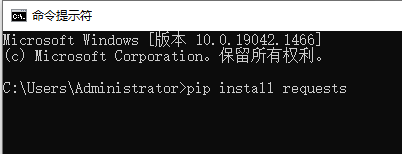
from bs4 import BeautifulSoup 这个是导入 BeautifulSoup库的写法
爬虫三大库 Requests Lxml BeautifulSoup
二、requests库入门
第一个爬虫程序
# 这个是导入requests库
import requests
# 这个可以理解为 定义url网址链接是多少 这个链接需要你自己去复制你想要爬取的网址的链接
url ="http://www.baidu.com"
# 这个headers 在浏览器的f12工具中找 首先进入百度 按f12
# 然后如下图 找到网络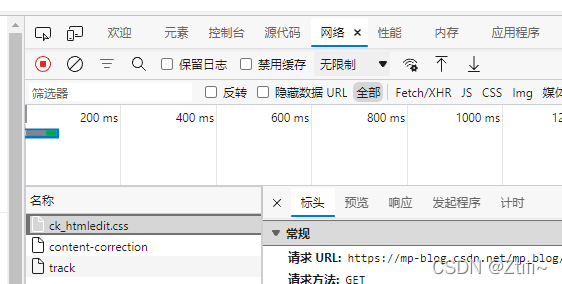
然后随便点一个名称 中的文件 往下滑 找到User-Agant 复制 整个User-Agant的内容 作为headers即可
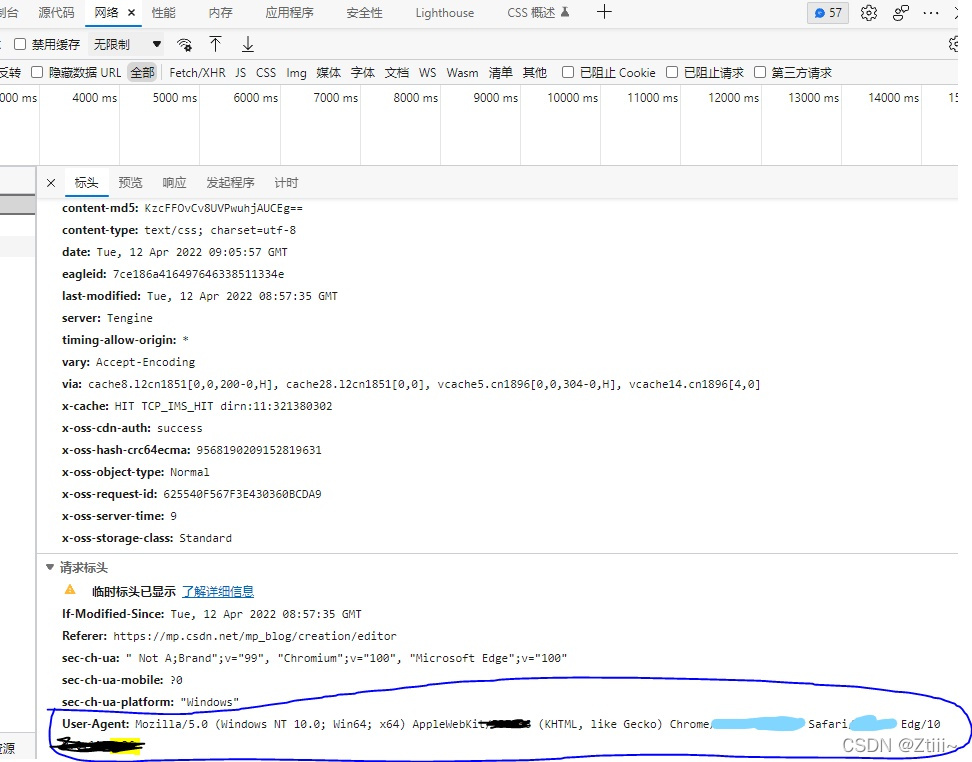
&nbs
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 6730
6730

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











