




URL详解
URL(Uniform Resource Locator) 地址用于描述一个网络上的资源, 基本格式如
下
schema://host[:port#]/path/.../[;url-params][?query-string][#anchor]
scheme 指定底层使用的协议(例如:http, https, ftp)
host HTTP 服务器的 IP 地址或者域名
port HTTP 服务器的默认端口是80,这种情况下端口号可以省略。如果使用了别的端口,必须指明,例如 http://www.cnblogs.com:8080/
path 访问资源的路径
url-params
query-string 发送给 http 服务器的数据
anchor- 锚
http://www.mywebsite.com/sj/test;id=8079?name=sviergn&x=true#stuff
Schema: http
host: www.mywebsite.com
path: /sj/test
URL params: id=8079
Query String: name=sviergn&x=true
Anchor: stuff
- HTTP协议是无状态的
http 协议是无状态的,同一个客户端的这次请求和上次请求是没有对应关系,对
http 服务器来说,它并不知道这两个请求来自同一个客户端。 为了解决这个问题, Web程序引入了 Cookie 机制来维护状态.
HTTP消息的结构
先看 Request 消息的结构,
Request 消息分为3部分,第一部分叫请求行, 第二部分叫 http header, 第三部分是 body.
header 和 body 之间有个空行, 结构如下图

- 第一行中的 Method 表示请求方法,比如"POST",“GET”, Path-to-resoure 表示请求的资源, Http/version-number 表示 HTTP 协议的版本号
当使用“GET”方法时,body是空的。
GET http://www.cnblogs.com/ HTTP/1.1
再看 Response 消息的结构, 和 Request 消息的结构基本一样。 同样也分为三部分,第一部分叫 request line, 第二部分叫 request header,第三部分是 body.
header 和 body 之间也有个空行, 结构如下图
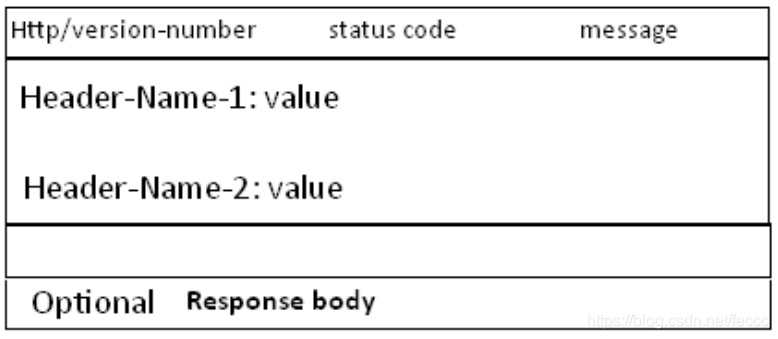
- HTTP/version-number 表示 HTTP 协议的版本号, status-code 和 message见下面
GET和POST的区别
Http 协议定义了很多与服务器交互的方法,最基本的有4种,分别是GET,POST,PUT,DELETE.
一个 URL 地址用于描述一个网络上的资源,而== HTTP 中的GET, POST, PUT, DELETE 就对应着对这个资源的查,改,增,删4个操作==。 我们最常见的就是 GET 和 POST 了。
GET 一般用于获取/查询资源信息,而 POST 一般用于更新资源信息。
- GET 提交的数据会放在 URL 之后,以?分割 URL 和传输数据,参数之间以&相连,如 EditPosts.aspx?name=test1&id=123456. POST 方法是把提交的数据放在HTTP 包的 Body 中.
- GET 提交的数据大小有限制(因为浏览器对 URL 的长度有限制),而 POST 方法提交的数据没有限制.
- **GET 方式需要使用 Request.QueryString 来取得变量的值,**而 POST 方式通过Request.Form 来获取变量的值。
- GET 方式提交数据,会带来安全问题,比如一个登录页面,通过 GET 方式提交数据时,用户名和密码将出现在 URL 上,如果页面可以被缓存或者其他人可以访问这台机器,就可以从历史记录获得该用户的账号和密码.
状态码 status-code
Response 消息中的第一行叫做状态行,由 HTTP 协议版本号, 状态码, 状态消息三部分组成。
状态码用来告诉 HTTP 客户端,HTTP 服务器是否产生了预期的 Response.
HTTP/1.1中定义了5类状态码, 状态码由三位数字组成,第一个数字定义了响应的类别:
| 状态码 | 意义 |
|---|---|
| 1XX | 提示信息 - 表示请求已被成功接收,继续处理 |
| 2XX | 成功 - 表示请求已被成功接收,理解,接受 |
| 3XX | 重定向 - 要完成请求必须进行更进一步的处理 |
| 4XX | 客户端错误 - 请求有语法错误或请求无法实现 |
| 5XX | 服务器端错误 -服务器未能实现合法的请求 |
| 一些常见的状态码 | ||
|---|---|---|
| 200 | 成功响应状态码 | 表明该请求被成功地完成,所请求的资源发送回客户端 |
| 302 | Found | 重定向,新的 URL 会在 response 中的 Location 中返回,浏览器将会使用新的URL 发出新的 Request |
| 304 | Not Modified | 代表上次的文档已经被缓存了, 还可以继续使用 |
| 400 | bad request | 客户端请求与语法错误,不能被服务器所理解 |
| 403 | Forbidden | 服务器收到请求,但是拒绝提供服务 |
| 404 | Not Found | 请求资源不存在 |
| 500 | Internal Server Error | 服务器发生了不可预期的错误 |
| 503 | Server Unavilable | 服务器当前不能处理客户端的请求,一段时间后可能回复正常 |
HTTP Request Header
header 有很多,比较难以记忆,我们把 header 进行分类
- Cache 头域
- If-Modified-Since
作用: 把浏览器端缓存页面的最后修改时间发送到服务器去,服务器会把这个时间与
服务器上实际文件的最后修改时间进行对比。
如果时间一致,那么返回304,客户端就直接使用本地缓存文件。
如果时间不一致,就会返回200和新的文件内容。客户端接到之后,会丢弃旧文件,把新文件缓存起来,并显示在浏览器中。 - If-None-Match
作用: If-None-Match 和 ETag 一起工作,工作原理是在 HTTP Response 中添加
ETag 信息。 当用户再次请求该资源时,将在 HTTP Request 中加入 If-None-Match
信息(ETag 的值)。如果服务器验证资源的 ETag 没有改变(该资源没有更新),将返回
一个304状态告诉客户端使用本地缓存文件。否则将返回200状态和新的资源和 Etag.
使用这样的机制将提高网站的性能 - Pragma
作用: 防止页面被缓存, 在 HTTP/1.1版本中,它和 Cache-Control:no-cache 作用一模一样
Pragma 只有一个用法, 例如: Pragma: no-cache
注意: 在 HTTP/1.0版本中,只实现了 Pragema:no-cache, 没有实现 Cache-Control - Cache-Control
作用: 这个是非常重要的规则。 这个用来指定 Response-Request 遵循的缓存机
制。各个指令含义如下- Cache-Control:Public 可以被任何缓存所缓存()
- Cache-Control:Private 内容只缓存到私有缓存中
- Cache-Control:no-cache 所有内容都不会被缓存
- If-Modified-Since
If-Modified-Since: Thu, 09 Feb 2012 09:07:57 GMT
If-None-Match: "03f2b33c0bfcc1:0"
- Client
- Accept
作用: 浏览器端可以接受的媒体类型,
例如: Accept: text/html 代表浏览器可以接受服务器回发的类型为 text/html,也就是我们常说的 html 文档,如果服务器无法返回 text/html 类型的数据,服务器应该返回一个406错误(non acceptable)。
通配符 * 代表任意类型
例如 Accept: / 代表浏览器可以处理所有类型,(一般浏览器发给服务器都是发
这个)
- Accept

















 1905
1905

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









