




目录
你有没有过这样的经历:训练数据量大的模型时,要等上十几分钟甚至半小时?
但有这样一种模型,面对普通数据集分类时,往往能在几秒内就能完成训练,预测精度还不输支持向量机(SVM)和神经网络——它就是极限学习机(ELM)。
今天我们就来好好聊聊这个“快得离谱”的模型,从原理到代码一次讲明白。
模型介绍
极限学习机是2006年由黄广斌教授团队提出的单隐层前馈神经网络改进模型,和传统神经网络比,它的“快”藏在核心设计里:
训练逻辑大不同:传统神经网络要反复调整输入层→隐层、隐层→输出层的所有参数,而ELM只需要固定输入层到隐层的权重(甚至随机生成就行),只优化隐层到输出层的参数。这一步直接把复杂的迭代优化变成了“求解线性方程组”,速度自然飙升。
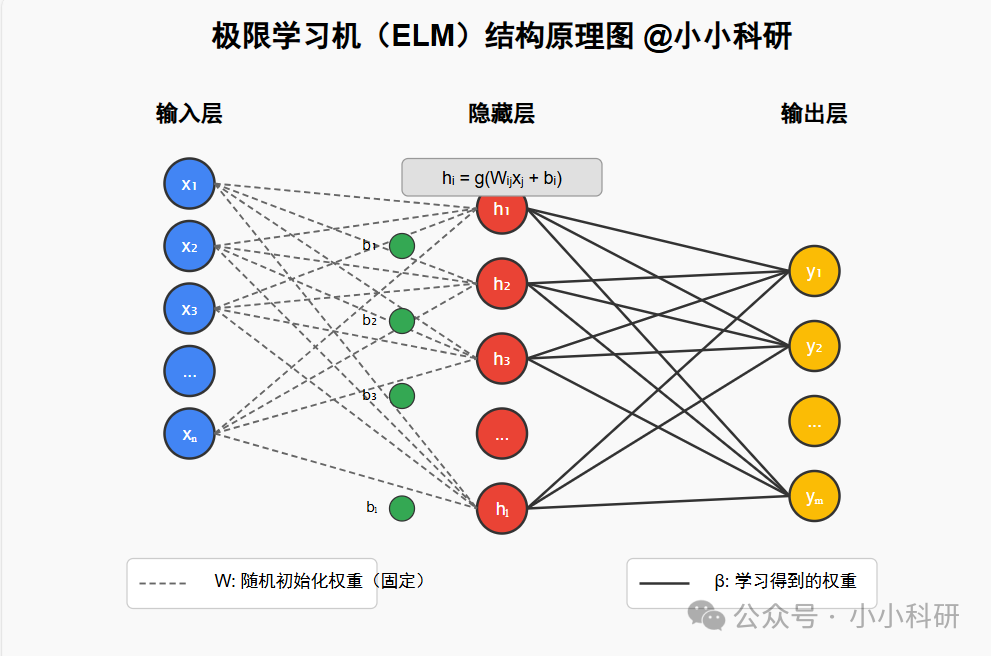
结构不复杂但够用:基本结构就三层——输入层接收数据,隐层用激活函数(比如sigmoid、ReLU)做非线性映射,输出层直接算结果。不用像深度学习那样堆层数,小数据集上反而更灵活,还不容易过拟合。
简单说:传统神经网络是“精雕细琢慢工出细活”,ELM是“抓重点快刀斩乱麻”,适合追求效率。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











