




CRF基本介绍
在机器学习中,建模线性序列结构的方法,除了HMM算法,另一个重要的模型就是CRF。HMM为了降低模型复杂性,对观测变量做了独立假设(即隐状态之间有相关性,而观测变量之间没有相关性),这在某种程度上损害了模型的准确性;CRF弥补了这个缺陷,它同样假设类别变量之间有相关性,但没有对观测变量之间做出任何假设(即可能有相关性,也可能没有相关性)。
CRF除了和HMM形成对比,前者是判别式模型,后者是生成式模型;另一方面,CRF还可看成是对最大熵模型的扩展,即它是一个结构化学习模型,而不是单个位置的分类模型。CRF如何被因子化,CRF公式如何推导,如何建立最大熵模型和CRF的公式联系,以及如何得到CRF图表示结构是本文的几个重点。本文还会提到,一些算法,刚开始被用于HMM,稍作修改也能用于线性链CRF,比如前向-后向算法、维特比算法。另外需要指出,用于线性链CRF的训练和推理算法,不能直接用于任意结构的CRF。
背景知识:条件熵(Conditional entropy)
信息论中,条件熵用于量化描述随机变量Y所需的信息量,在另一个随机变量X已知的情况下,写作H(Y|X),具体形式如下:
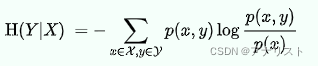 (公式1)
(公式1)
其中和
![]() 表示随机变量X和Y的样本集。注意,这里有可能出现
表示随机变量X和Y的样本集。注意,这里有可能出现,可以认为等于0,因为
![]()
直觉上,可以把看成是某个函数
的期望,即
,其中
是条件概率,被定义为:
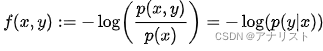
它是公式1中负号放到求和里面后的右半部分。
函数可看成当给定变量
时,为描述变量
需要的额外信息量。因此通过计算所有的
数据对的
期望值,条件熵
就能测量出要想通过
变量解码出
变量,平均意义上需要多少信息。
现在进一步要问,以上具体怎么来的?首先假设Y的概率密度函数为
,那么Y的熵
就是
,具体为:
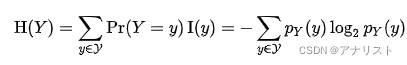 (公式2)
(公式2)
其中是当Y取
的互信息。因此,已知X为某个取值x时求Y的熵
根据条件期望,即代入公式2有:
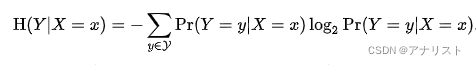 (公式3)
(公式3)
注意,表示对
求关于所有不同x取值的平均。换言之,
是对
关于每个x的加权求和,其中权重就是概率
,具体如下:
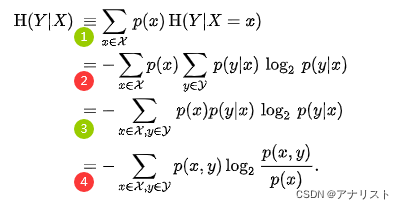 (公式4)
(公式4)
上式第1个等号根据定义;第2个等号使用了公式3;第3个等号调整,将两个合并简化;第4个等号利用贝叶斯公式。公式4最后得到公式1。
一些基本属性:当且仅当Y完全被X控制。
当且仅当Y和X是两个独立的随机变量。
条件熵的链式规则:,即当X的熵
已知,那么Y的条件熵
可通过联合熵
减去
得到。它的推导过程如下:
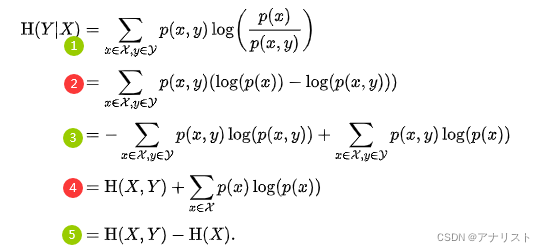 (公式5)
(公式5)
上式第1步来自公式4;第2步把log拆成相减的两项;第3步把拆成两项;第4步对第一项套用熵的公式得到
,对第二项消去y变量(对y求和);第5步继续套用熵的公式,得到
把公式5扩展到多个随机变量,得到:
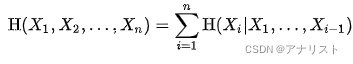 (公式6)
(公式6)
可以发现公式6和概率中的链式法则类似,只不过把乘法变为了加法。
条件熵的贝叶斯规则:,证明如下:因为有
,以及
,别忘了
,得证。特别的当Y条件独立于Z(当给定X),那么有
最大熵模型(Maximum Entropy Model)
最大熵模型是一个条件概率模型,它基于最大熵原则,意思是,当我们不具备对一个概率分布的完整信息时,唯一的无偏估计假设就是均匀分布。在该假设下,最恰当的概率分布就是在给定约束下的最大化熵的分布。根据公式1,对于条件模型,对应的条件熵
为:
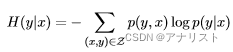 (公式一)
(公式一)
其中Z = X ×Y ,包含了所有可能的输入x和输出y。注意:Z不仅包括所有训练数据的样本,也包括所有可能出现的组合。最大熵模型的基本原理是:找到
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1986
1986

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









