




 本文详细介绍了LLVM的链接时优化(LTO)技术,包括其原理、如何通过跨模块优化提高程序性能,以及两种主要模式:大型LTO和增量LTO的区别与应用场景。此外还涉及了跨语言LTO及其实现。
本文详细介绍了LLVM的链接时优化(LTO)技术,包括其原理、如何通过跨模块优化提高程序性能,以及两种主要模式:大型LTO和增量LTO的区别与应用场景。此外还涉及了跨语言LTO及其实现。
由于编译器一次只编译优化一个编译单元,所以只是在做局部优化,而利用 LTO,利用链接时的全局视角进行操作,从而得到能够进行更加极致的优化。
1、定义
“Link-Time Optimization.” Any kind of optimization that requires looking at the whole program, LLVM features powerful intermodular optimizations which can be used at link time.
LTO(Link-Time Optimization) 就是对整个程序代码进行的一种优化,是 LLVM 里在链接时进行跨模块间的优化。
LTO 属于 IPO(interprocedural optimization) 当中的一种优化,根据维基百科的解释,IPO 是优化代码的一系列编译器优化技术的集合,不同于其他的优化技术,IPO 聚焦于分析整个程序代码。
2、实际操作
The basic principle behind LTO is that some of LLVM's optimization passes are pushed back to the linking stage. Why the linking stage? Because that is the point in the pipeline where the entire program (i.e. the whole set of compilation units) is available at once and thus optimizations across compilation unit boundaries become possible.
即把一些 pass 的优化推迟到链接时再执行,从而使这些 pass 获得跨模块优化的能力。
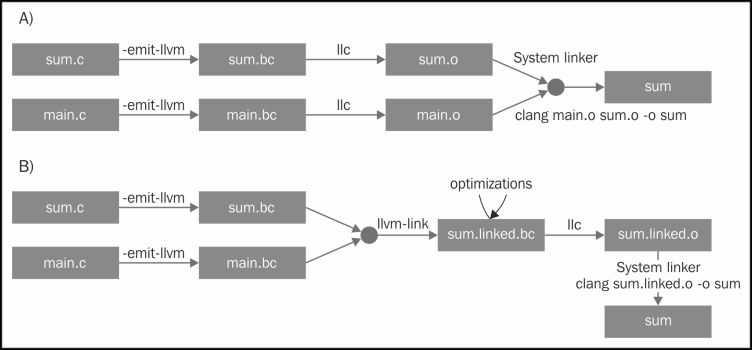
Link-Time Optimization (LTO) addresses the problem where the compiler traditionally only sees one translation unit (e.g., a .c file with all its headers) at a time and therefore cannot do optimizations (like inlining) across file boundaries. LLVM compilers like Clang support this with the -flto or -O4 command line option. This option instructs the compiler to emit LLVM bitcode to the .o file instead of writing out a native object file, and delays code generation to link time.
LTO 指出了问题:编译器一次只能看到一个编译单元,因此没法跨文件范围做优化(如内联)。LLVM 的编译器比如 clang 支持 -flto 或者 -O4 命令。这个命令让编译器输出 bitcode 格式(LLVM IR 的其中一种格式)的 .o 文件而不是本地的目标文件,推迟代码生成到链接时。

Details differ depending on which operating system you're on, but the important bit is that the linker detects that it has LLVM bitcode in the .o files instead of native object files. When it sees this, it reads all the bitcode files into memory, links them together, then runs the LLVM optimizer over the aggregate. Since the optimizer can now see across a much larger portion of the code, it can inline, propagate constants, do more aggressive dead code elimination, and more across file boundaries. While many modern compilers support LTO, most of them (e.g., GCC, Open64, the Intel compiler, etc.) do so by having an expensive and slow serialization process. In LLVM, LTO falls out naturally from the design of the system, and works across different source languages (unlike many other compilers) because the IR is truly source language neutral.
具体细节会因操作系统而异,但链接器重要的一点是检查 .o 文件是 bitcode 格式还是本地目标格式。当看到是 bitcode 格式,它会把所有的 bitcode 文件读进内存,把他们链接到一起,然后在集成过程中执行 LLVM 的优化器。由于优化器可以看到更多的代码范围,它就能做到内联、常量传播、更激进的无用代码删除的优化。当现代编译器支持 LTO 时,大部分会有较高的代价和缓慢的序列化过程,在 LLVM 中 LTO 就自然得多,因为有 IR 这个中间格式。
The linker uses libLTO, a shared object, to handle LLVM bitcode files.
链接器会使用 libLTO 这个动态库来处理 LLVM bitcode 格式的文件。
2.1、为什么 LTO 采用 bitcode 的方式来实现?
LTO 让编译器生产 bitcode 格式的文件,然后让链接器读取来进行优化,但为什么要这样实现呢?
看下其他方法可能的问题:
- Compiler driver invokes link time optimizer separately 让编译器来调用 LTO
这样的话,LTO 就没法在链接器解析符号阶段来收集信息了。由于某些符号是对外可见的(externally visible),所以链接器没有足够的信息来处理这部分符号。
- Use separate tool to collect symbol information from all object files 使用独立的工具来收集所有目标文件的符号信息
复制 LTO 的能力到一个单独的工具上,是不太合理的,不同平台链接器的语义和功能都不太一致,这样维护成本非常高,还需要与链接器的开发进度进行同步,这已经偏离 LTO 原本的开发了。而且还增加了编译的时间。
3、主要优化
跨模块优化的效果,也即开启LTO主要有这几点好处:
(1)将一些函数內联化
(2)去除了一些无用代码
(3)对程序有全局的优化作用
PGO(Profile Guided Optimization) 对于进行 LTO 优化也很有帮助。
4、monolithic LTO (-flto)
Monolithic Link-Time Optimization: This mode performs monolithic link-time optimization of binaries, combining all executable code into a single unit and running aggressive compiler optimizations.
大型 LTO:这种模式对二进制进行大型的链接时优化,合并所有的可执行代码到一个单元,并且执行更加激进的编译器优化。
monolithic LTO implements this by merging all input into a single module, which is not scalable in time or memory, and also prevents fast incremental compiles.
大型 LTO 的实现是把所有的输入合并到一个模块,并没有考虑时间和内存的问题,而且还阻碍了增量编译的执行。
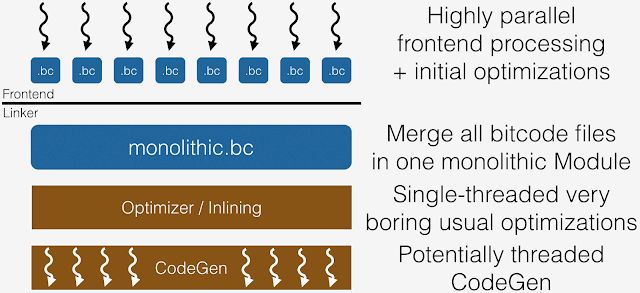
What this means in practice is that LTO often requires a large amount of memory (to hold all IR at once) and is very slow. And with debug information enabled via -g, the size of the IR and the resulting memory requirements are significantly larger. Even without debug information, this is prohibitive for very large applications, or when compiling on memory-constrained machines. It also makes incremental builds less effective, as everything from the LTO step on must be re-executed when any input source changes.
这意味着 LTO 经常需要大量的内存,而且很慢。加上 -g 带来的调试信息,IR 的大小和内存需要都会非常大。即使没有调试信息,对于大型软件而言是难以执行的,或者在一台内存受限的机器上也是。同时它会导致增量编译变得低效,因为当源码改变时, LTO 的步骤中的所有东西都需要被重新执行。
-Xlinker -object_path_lto
-Xlinker Release-iphoneos/test.build/Objects-normal/arm64/test_lto.o
-flto4.1、problem
- Not all passes are linear-time
- Memory usage explodes
5、ThinLTO (-flto=thin)
Incremental Link-Time Optimization: This mode performs partitioned link-time optimization of binaries, inlining between compilation units and running aggressive compiler optimizations on each unit in parallel. This enables fast incremental builds and uses less memory than Monolithic LTO.
增量 LTO:这个模式可以对二进制执行部分的链接时优化,在编译单元之间进行内联,并行地在每个单元里执行更激进的编译器优化。这个可以允许更快的增量编译,以及使用更少的内存。
It utilizes compact summaries of each module for global analyses in the serial link step, as well as an index of function locations for later cross module importing. The function importing and other IPO transformations are performed later when the modules are optimized in fully parallel backends.
在连续的链接阶段,它使用紧凑的描述来代表每个模块来进行全局的分析,包含有之后进行跨模块引入的函数位置的索引信息。函数引入和其他的 IPO 转换会在模块在并行优化时再执行。
The key transformation enabled by ThinLTO global analyses is function importing, in which only those functions likely to be inlined are imported into each module. This minimizes the memory overhead in each ThinLTO backend, while maximizing the most impactful cross module optimization opportunities. The IPO transformations are therefore performed on each module extended with its imported functions.
ThinLTO 全局分析的一个关键转换是函数引入,只有那些可能被内联的函数才会被引入到模块之中。这种方式最小化了内存的开销,同时最大化了跨模块优化的机会。IPO 转换因此会在每个使用了函数引入的扩展模块中执行。
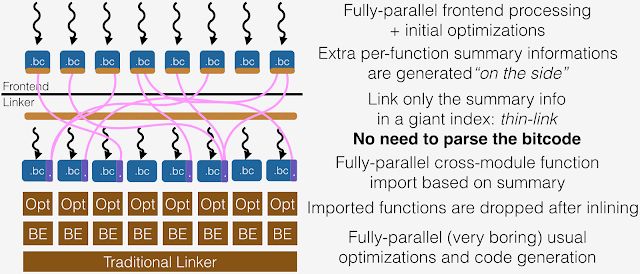
The ThinLTO process is divided into 3 phases: ThinLTO 被分成了三个步骤
- Compile: Generate IR as with full LTO mode, but extended with module summaries 编译:生成完全 LTO 模式的 IR,但是扩展以模块描述
- Thin Link: Thin linker plugin layer to combine summaries and perform global analyses 链接:thin 链接器插件层合并这些描述并执行全局分析
- ThinLTO backend: Parallel backends with summary-based importing and optimizations 后端:并行基于描述信息的引入和优化
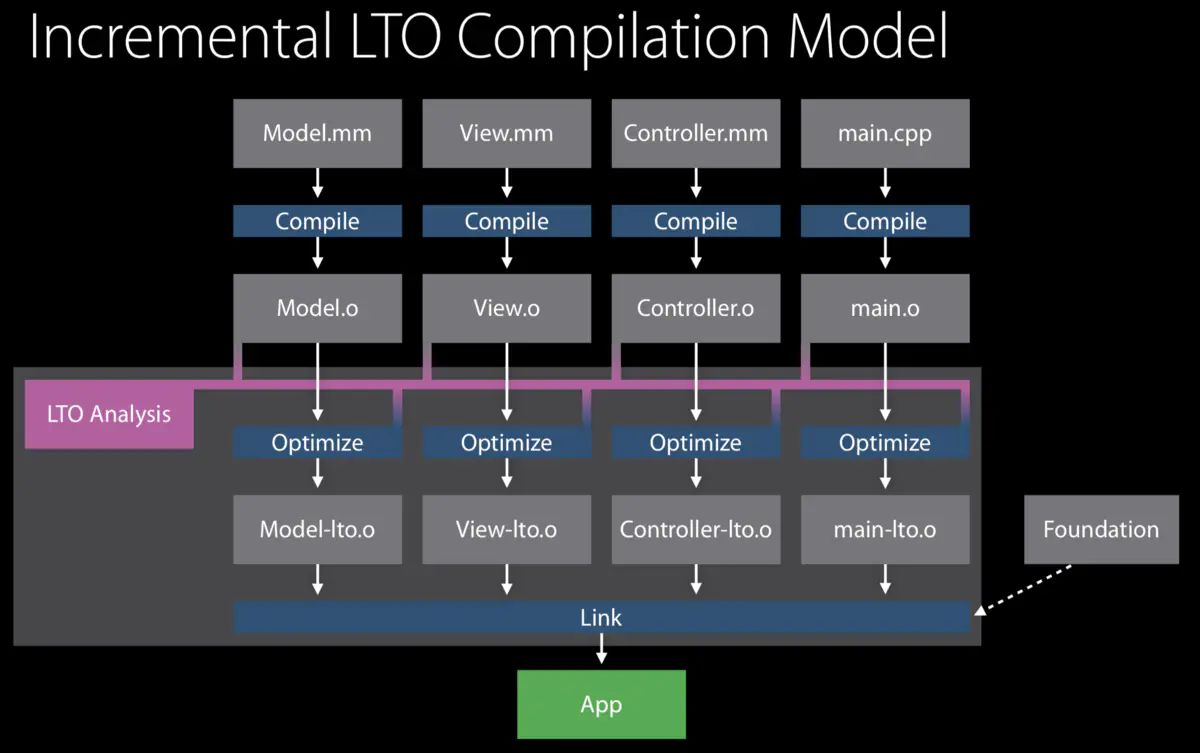
By default, linkers that support ThinLTO (see below) are set up to launch the ThinLTO backends in threads. So the distinction between the second and third phases is transparent to the user.
默认情况下,链接器会支持 ThinLTO 被设置为在一个线程开启 ThinLTO 的后端,所以在第二步和第三步之间的差异对于用户是透明的。
These summaries are emitted using the bitcode format, but designed so that they can be separately loaded without involving an LLVMContext or any other expensive construction. Each global variable and function has an entry in the module summary. An entry contains metadata that abstracts the symbol it is describing.
描述信息是用 bitcode 格式生成的,但是经过设计以让他们可以分开各自地加载,而不用 LLVMContext 的参与以及其他开销较大的构造。每个全局变量和函数在模块描述文件中都有一个实体,一个实体包含有描述符号抽象的元信息。
-Xlinker -object_path_lto
-Xlinker Release-iphoneos/test.build/Objects-normal/arm64/test_lto.o
-flto=thin
-Xlinker -cache_path_lto
-Xlinker Build/Intermediates.noindex/LTOCache
6、cross language LTO

The compiler front-end generates an LLVM bitcode module (.bc) for each compilation unit. In C and C++ each source file will result in a single compilation unit. In Rust each crate is translated into at least one compilation unit. 编译器前端为每一个编译单元生成 LLVM bitcode 的模块。
In the next step, LLVM's optimization pipeline will optimize each LLVM module in isolation 下一步,LLVM 的优化器会单独地优化每一个 LLVM 模块。
LLVM then lowers each module into machine code so that we get one object file per module 然后 LLVM 把每个模块转成机器码
Finally, the linker will take the set of object files and link them together into a binary 最后链接成最终的二进制文件
6.1、Cross-language link time optimization

7、LTO 的问题
开启 lto 后导致产生的 linkmap 可读性变差,如文件名信息可能会变成 8.arm64.thinlto.o 这样的数字,可以对 libLTO.dylib 的行为进行修改,使用 -lto_library 让链接器使用我们指定的 dylib 库。
reference
cross language LTO:https://blog.llvm.org/2019/09/closing-gap-cross-language-lto-between.html
thisLTO:http://blog.llvm.org/2016/06/thinlto-scalable-and-incremental-lto.html
LTO 有什么优化:https://www.jianshu.com/p/58fef052291a
LLVM Link Time Optimization: Design and Implementation:https://llvm.org/docs/LinkTimeO

















 1539
1539

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









