




 本文详细介绍了如何优化Clang编译器中用于行号到偏移量映射的函数,通过分析源代码文件的新行占比,使用内置函数__builtin_expect进行分支预测优化,并探讨了SSE优化和位操作优化的方法,最终实现了性能的显著提升。文章适合对编译器优化和C++性能调优感兴趣的读者。
本文详细介绍了如何优化Clang编译器中用于行号到偏移量映射的函数,通过分析源代码文件的新行占比,使用内置函数__builtin_expect进行分支预测优化,并探讨了SSE优化和位操作优化的方法,最终实现了性能的显著提升。文章适合对编译器优化和C++性能调优感兴趣的读者。
偶然发现一篇优化函数执行性能的文章,文章以 clang 里的 mapping 函数举例,但其优化思路以及举措可以通用到很多地方,非常值得一读,特此借翻译此文也加深自己的理解。
内容来源: https://developers.redhat.com/blog/2021/05/04/optimizing-the-clang-compilers-line-to-offset-mapping/
原文标题:Optimizing the Clang compiler’s line-to-offset mapping
作者: Serge Guelton
译者:流左沙
注:翻译较原文会有一定的精简、重排和添删,主要是为了提取重要内容以达到更好的理解,请以原文为准。
在用 profile 对 clang 编译器本身进行速度优化的时候,发现有一个函数相当地突出:
clang::LineOffsetMapping::get(llvm::MemoryBufferRef Buffer, llvm::BumpPtrAllocator &Alloc)
这个函数的逻辑就是分配一个容器(通过形参变量 Alloc 分配)来将行号跟文件内容的偏移量做映射(加载了文件内容的形参变量 Buffer)。
即 vector[行号] = 偏移量
这个函数逻辑比较独立,可以很好地去做 benchmark 基准测试。
The problem, and the naive implementation
std::vector<unsigned> LineOffsets;
LineOffsets.push_back(0);
const unsigned char *Buf = (const unsigned char *)Buffer.data();
const std::size_t BufLen = Buffer.size();
unsigned I = 0;
while (I < BufLen) {
if (Buf[I] == '\n') {
LineOffsets.push_back(I + 1);
} else if (Buf[I] == '\r') {
// If this is \r\n, skip both characters.
if (I + 1 < BufLen && Buf[I + 1] == '\n')
++I;
LineOffsets.push_back(I + 1);
}
++I;
}
大概操作就是:当读到行分隔符 \n 或 \r\n 时,就进行存储 vector[行号] = 偏移量
Manual profile-guided optimization
因为读入 Buffer 的文件内容其实就是源代码,所以字符是新行或非新行的比率就可以当作优化指标了。
$ find llvm -name '*.cpp' -exec cat {} \; | tr -cd '\n' | wc -c
2130902
$ find llvm -name '*.cpp' -exec cat {} \; | wc -c
78537977只有大概 2% 左右的新行占比。
那么根据这个比率,我们可以使用 gcc 的 __builtin_expect(expression, value) 来进行优化,这个函数的作用是允许程序员将最有可能执行的分支告诉编译器。【参考博文:https://www.jianshu.com/p/2684613a300f】
将流水线引入 CPU,可以提高 CPU 的效率。更简单的说,让 CPU 可以预先取出下一条指令,可以提供 CPU 的效率。如果存在跳转指令,那么预先取出的指令就无用了。CPU 在执行当前指令时,从内存中取出了当前指令的下一条指令。执行完当前指令后,CPU 发现不是要执行下一条指令,而是执行 offset 偏移处的指令。CPU 只能重新从内存中取出 offset 偏移处的指令。因此,跳转指令会降低流水线的效率,也就是降低 CPU 的效率。 【参考博文: https://blog.youkuaiyun.com/shuimuniao/article/details/8017971】
意思是 expression == value 的概率很大,编译器拿到这个信息(分支转移的信息)之后,在编译过程会将可能性更大的代码紧接在其后,从而减少指令跳转带来的性能损耗。
值得一提的是 c++20 的 likely 和 unlikely 与此殊途同归。
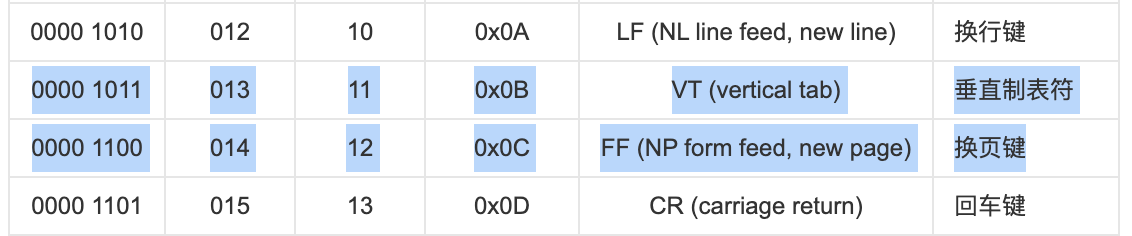
继续回到我们的优化,因为 \n 和 \r 在 ASCII 表中,位于这两个符号中间的那些都不常见,是垂直制表符和换页符,所以我们能够做一个快速的判断逻辑。【\n 是换行且使光标到行首;\r 是回车且使光标下移一格】
unsigned I = 0;
while (I < BufLen) {
// Use a fast check to catch both newlines
if (__builtin_expect((Buf[I] - '\n') <= ('\r' - '\n'), 0)) {
if (Buf[I] == '\n') {
LineOffsets.push_back(I + 1);
} else if (Buf[I] == '\r') {
if (I + 1 < BufLen && Buf[I + 1] == '\n')
++I;
LineOffsets.push_back(I + 1);
}
}
++I;
}
注意,这里的快速判断逻辑不能改为看似等价的 Buf[I] <= '\r' 。因为 tab 键就符合这个错误的判断逻辑。
Adding a fast path
我们可以调整算法来做 \r 字符的快速扫描,如果没有的话就进入快速通道。如果有则走正常的之前的逻辑。
if(!memchr(Buf, '\r', BufLen)) {
while (I < BufLen) {
if (__builtin_expect(Buf[I] == '\n', 0)) {
LineOffsets.push_back(I + 1);
}
++I;
}
}
else {
// one of the version above... or below
}
Looking through history
clang 源码包含有一个优化点:clang::LineOffsetMapping::get 曾经有过一个 SSE 的版本,但之后为了可维护性在之后版本 d906e731 又被去掉了。
那个 SSE 版本在 aligned load (对齐加载) 费尽心思,但对于旧的架构而言是一个很重要的优化点。从那之后,unaligned loads (非对齐加载) 在一些现代英特尔架构的开销已经下降了很多,所以我们可以尝试写一个新的 SSE 版本,同时它会是很容易去理解和维护的:
【解释下这两个 SSE 操作:【参考 https://stackoverflow.com/a/15964428/13005964 】
如果你知道你的源地址是正常对齐的,那么使用对齐加载 (aligned load) 可以更加高效地读取,因为它只需要一次的读操作,而不需要去处理几块不对齐的数据。
现代 CPU 对于对齐数据 (aligned data)进行这两个操作的开销差异已经不大了,但如果对于不对齐数据 (misaligned data) 进行对齐加载 (aligned load) 会引发异常。】
#include <emmintrin.h>
// Some renaming to help the reader not familiar with SSE
#define VBROADCAST(v) _mm_set1_epi8(v)
#define VLOAD(v) _mm_loadu_si128((const __m128i*)(v))
#define VOR(x, y) _mm_or_si128(x, y)
#define VEQ(x, y) _mm_cmpeq_epi8(x, y)
#define VMOVEMASK(v) _mm_movemask_epi8(v)
const auto LFs = VBROADCAST('\n');
const auto CRs = VBROADCAST('\r');
while (I + sizeof(LFs) + 1 < BufLen) {
auto Chunk1 = VLOAD(Buf + I);
auto Cmp1 = VOR(VEQ(Chunk1, LFs), VEQ(Chunk1, CRs));
unsigned Mask = VMOVEMASK(Cmp1) ;
if(Mask) {
unsigned N = __builtin_ctz(Mask);
I += N;
I += ((Buf[I] == '\r') && (Buf[I + 1] == '\n'))? 2 : 1;
LineOffsets.push_back(I);
}
else
I += sizeof(LFs);
}
除了添加 SSE 的操作,还使用了内置函数 __builtin_ctz 去计算一个数末尾 0 的数量,这样可以直接就操作到要匹配的字符的位置。
因为我们知道要匹配的字符要么是 \r,要么是 \n,所以可以避免一些比较,直接用一行像 x86 的有状态 mov 的代码去操作要偏移的位置(这里指的是第 21 行)。
Bit hacks
接下来尝试看下 memchr 函数在 glibc 上的实现,它使用了类似向量化的操作,但有不少的兼容性问题,一般称之为 multibyte word packing (多字节压缩)。
位操作的爱好者知晓 Hacker's Delight 和他的好朋友 Bit Twiddling Hacks。他们包含有对于多字节的很多有用的操作,包括如何确定一个字 (word) 是否有在 m 到 n 区间范围内的字节 (byte)。
template <class T>
static constexpr inline T likelyhasbetween(T x, unsigned char m,
unsigned char n) {
// see http://graphics.stanford.edu/~seander/bithacks.html#HasBetweenInWord
return (((x) - ~static_cast<T>(0) / 255 * (n)) & ~(x) &
((x) & ~static_cast<T>(0) / 255 * 127) + ~static_cast<T>(0) / 255 * (127 - (m))) &
~static_cast<T>(0) / 255 * 128;
}
uint64_t Word;
// scan sizeof(Word) bytes at a time for new lines.
// This is much faster than scanning each byte independently.
if (BufLen > sizeof(Word)) {
do {
memcpy(&Word, Buf + I, sizeof(Word));
#if defined(BYTE_ORDER) && defined(BIG_ENDIAN) && BYTE_ORDER == BIG_ENDIAN
Word = __builtin_bswap64(Word); // some endianness love
#endif
// no new line => jump over sizeof(Word) bytes.
auto Mask = likelyhasbetween(Word, '\n' - 1, '\r'+1 );
if (!Mask) {
I += sizeof(Word);
continue;
}
// Otherwise scan for the next newline - it's very likely there's one.
// Note that according to
// http://graphics.stanford.edu/~seander/bithacks.html#HasBetweenInWord,
// likelyhasbetween may have false positive for the upper bound.
unsigned N = __builtin_ctzl(Mask) - 7;
Word >>= N;
I += N / 8 + 1;
unsigned char Byte = Word;
if (Byte == '\n') {
LineOffsets.push_back(I);
} else if (Byte == '\r') {
// If this is \r\n, skip both characters.
if (Buf[I] == '\n')
++I;
LineOffsets.push_back(I);
}
}
while (I < BufLen - sizeof(Word) - 1);
}
这代码有点长,而且依赖了 likelyhasbetween 函数中没被记载的特性:它设置比特来持有要搜索的值 0x80。
我们可以用这个 mask (掩码) 和内置函数 __builtin_ctzl 来匹配到正确的位置。
Crunching numbers
我把各种各样的实现都放到了一个仓库里了,里面还有一些测试来验证效果,使用 SQLite amalgamation 作为输入。
这是我笔记本电脑的效果,Core i7-8650U and gcc 8.2.1 (timing in milliseconds, average on 100 runs):
ref: 11.37
seq: 11.12
seq_memchr: 6.53
bithack: 4
bithack_scan: 4.78
sse_align: 5.08
sse: 3
sse_memchr: 3.7ref 是参考的版本,作为对照。
使用 pgo 方式的 seq 只有少量提升。
快速通道的方式 seq_memchr提升效果比较明显。
位操作的两个版本几乎和 SSE 一样快,使用了快速通道的 SSE 版本反而适得其反。
在其他平台结果还不太一样,On a Mac Mini (on arm64), using the Apple clang version 12.0.0:
ref: 6.49
seq: 4
seq_memchr: 4
bithack: 2
bithack_scan: 2.05Conclusion
最终我提交了位操作的版本给 LLVM。所以它没有 SSE 的表现效果好,但合入方强调了对于未知架构都能优于当前版本的好处,位操作会更加符合。
想了解更多 clang 和 LLVM 后端的内容,可以在这里查看:Red Hat Developer topic page。

















 1789
1789

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









