



最近看了一篇论文《基于 LLVM 克隆代码检测关键技术研究》,觉得有些概念和思路不错,做了些笔记。
本文大纲如下:
1、意义
2、检测等级
3、主流思路
3.1、基于文本的检测方法
3.2、基于树的检测方法
3.3、基于图的检测方法
3.4、论文思路
1、意义
重复代码的增多会大大降低代码的可维护性。
不恰当的代码重复表明程序设计不良,例如缺少抽象。这会导致程序过长,错误更多,进而难以维护,因为需要人工寻找并修改重复的部分。
当克隆具有软件漏洞的代码时,如果开发人员不知道这样的副本,则克隆的代码中可能会继续存在漏洞。代码重构可以改善许多软件的度量衡标准,例如源代码行数,循环复杂度和耦合度。这可能会缩短编译时间,降低认知负载,减少人为错误,减少被遗忘或被忽视的代码。
减少重复代码量,从而提高代码质量。
2、检测等级
Type-1:代码除了空格、注释以外都与源程序都相同;
Type-2:在级别1 基础上,代码片段的变量名、常量、类名等标识符不同,但是语法结构相同;
Type-3:在级别 2 的基础上,改变、删除、增加程序的执行语句,但是程序大体结构基本不变;
Type-4:两段代码能实现相同的功能,在相同的输入值的情况下会得到相同的结果。
3、主流思路
3.1、基于文本的检测方法
该类方法直接以文本内容作为对比依据或将文本转成中间形式再进
行对比。
-
以原代码行作为基础单位,后缀树分析。
-
将源代码转成 token 序列,按照规则规范化 token 序列,再用后缀树分析。
-
设计不同的前端将不同的代码转换成标准化的 token 序列,并采用优化后的前缀倍增算法
加快了检测速度。 -
将 token 序列定长子串进行映射,利用编辑距离算法确定克隆对,通过并查集算法加速构建克隆群,借此提供检测 Type-3 克隆代码的能力。
3.2、基于树的检测方法
该类方法的使用前提是通过词法分析器与语法分析器获取一个抽象语法树。查找克隆代码的过程其实是抽象语法树查找相同或者相似子树的过程。
-
聚类查找相似子树。
-
消除抽象语法树的冗余节点,分析相关节点生成特征标记串文本,并利用决策函数完成检测工作。
3.3、基于图的检测方法
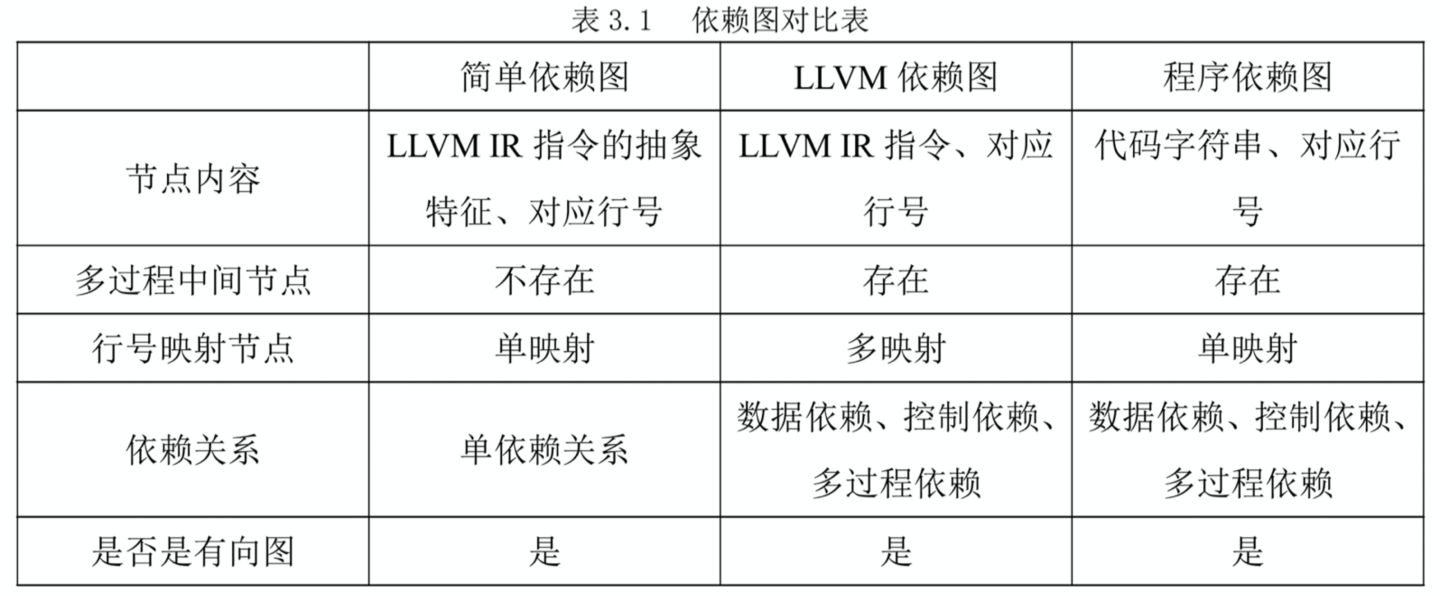
该方法以包含调用关系、控制流信息与数据流信息的程序依赖图作为分析基础,并以基于依赖图查找同构子图的方式确定克隆代码的位置。
- 以程序依赖图分割方法作为理论基础,结合了 Hadoop 并行查找结构子图的方式,加快了克隆代码的查找效
率。
3.4、论文思路
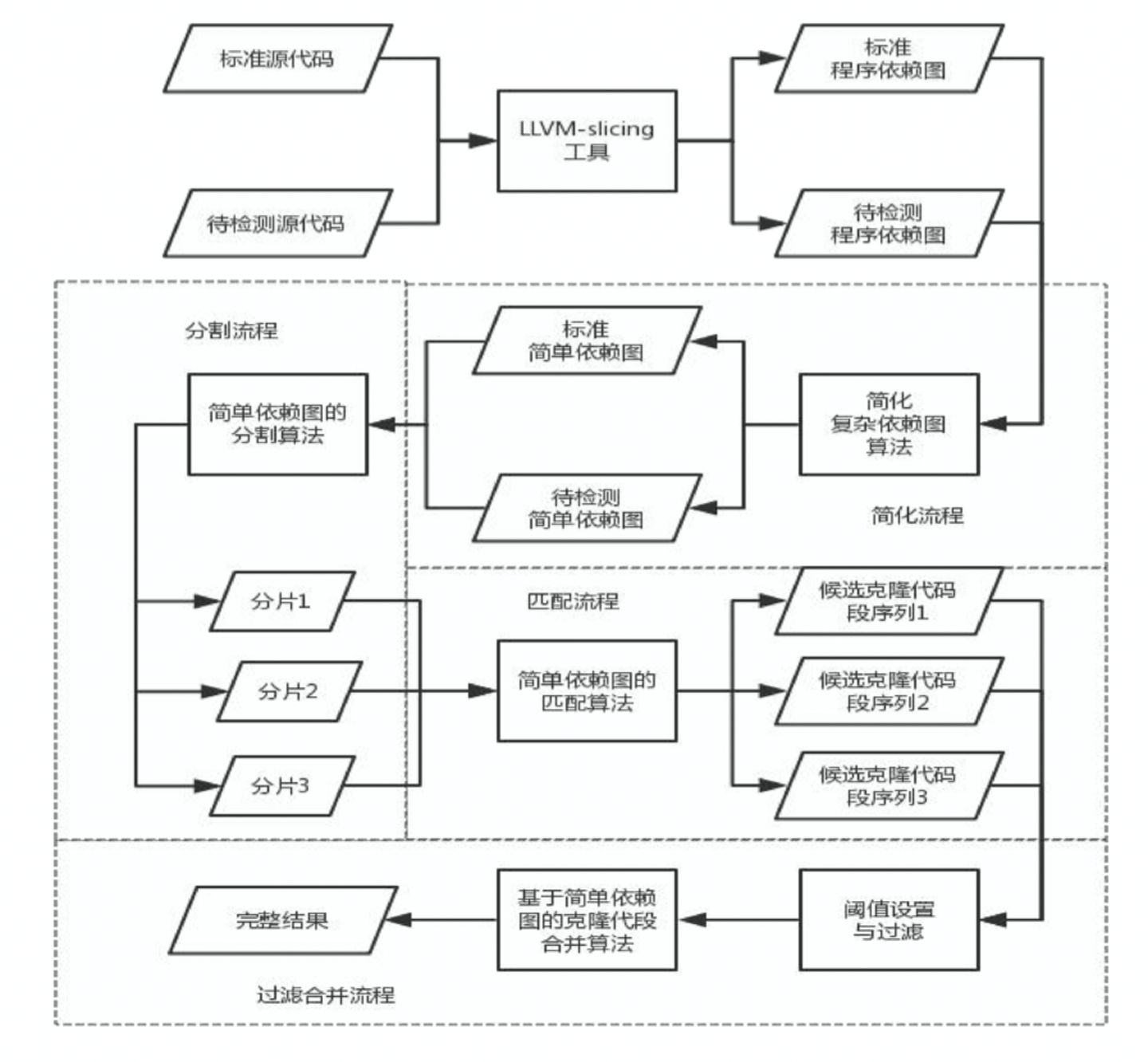
(1)提出基于简单依赖图的分割与克隆代码匹配方法。通过固定分片边界,以 LLVM IR 代码特征作为匹配依据,确定克隆代码候选位置。
(2)提出基于简单依赖图的克隆代码合并与连接方法。通过连接候选代码片段,屏蔽孤立的代码片段,确定最大的连续克隆代码段。
(3)实现一个基于 LLVM 通用的克隆代码检测模型并进行实验对比。结合分割、匹配、过滤、合并流程,混合 LLVM 的特性以及机器学习知识,完成对克隆代码的检测。

















 786
786

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









